UML Diagrams
Basic structure class diagram
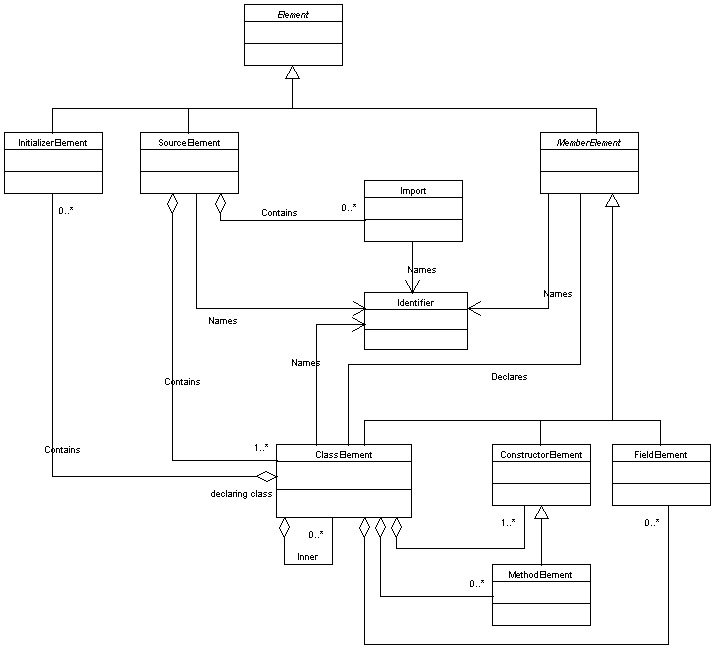
org.openide.src.
The package
org.openide.src.nodes
also provides node representations of them.
Element
and its concrete subclasses (you may want to look at the
inheritance hierarchy).
An element represents one point in the hierarchy, whether a source
file, a class (or interface), a member (including constructors,
methods, and fields), or an initializer block.
SourceElement,
representing a block of code - either a top-level introspected
class, or a Java source file. It is generally obtained from a data
object participating in the elements hierarchy using a
SourceCookie.
ClassElements,
which represent Java classes (or interfaces). The class elements
directly contained by a source element are of course
top-level classes, although classes may themselves contain
inner classes (only named inner classes are represented in
this API).
Typically a source element will only contain one top-level class, although the Java specification still permits additional package-private classes in the same source file (though this is deprecated in favor of inner classes).
Source elements may also contain
Imports
of classes and packages, though these have no element
structure. Introspected top-level classes will of course not
contain any imports, as this is meaningless, but source files may
have them.
MemberElements,
such as
MethodElements,
ConstructorElements,
and
FieldElements.
They may also contain inner classes (which are also
class elements),
as well as initializer blocks represented by
InitializerElements;
initializer blocks may be static or not, for example:
private static Thing myThing;
static {
myThing=new Thing () {
{
init ();
}
public void doStuff () {/* ... */}
};
}
ClassElement clazz; Identifier id = clazz.getSuperClass (); String name = id.getFullName (); ClassElement superclazz = ClassElement.forName (name); if (superclazz != null) // ...Besides the actual hierarchy of elements, particular element types have their own properties or sets of children beyond the list of child elements. For example, constructors and methods have an associated body of Java code (if taken from Java source); fields have associated value types, and methods return types; etc. A few classes in the API, such as
Identifier,
are used by elements, but are not themselves elements.
As a practical matter, it is undesirable for implementations of
the element types to directly provide the full element interface,
as there is a smaller set of core operations on the elements
(getting and setting children and properties) together with a
number of higher-level operations. So, all the element types
(except for SourceElement) have a corresponding inner
interface named Impl which specifies the most basic
operations on that element type. Elements may be created either
specifying an implementation object (and parent element), or with a
default constructor which leaves the element initially unattached
to any parent, and stores its child list and properties in
memory. SourceElement, as it represents a topmost
item, has no default implementation - if needed, an implementation
based on its actual storage (e.g. a *.java file) must
be provided.
In the standard IDE distribution's modules, there are two separate implementations of the source hierarchy. One is based on class files, and uses Java Reflection to create the structure; the other parses Java source files. Other modules may provide alternate source hierarchies - for example, a NetRexx support module could provide access to NetRexx program constructs in terms of the source hierarchy.
SourceException
to indicate they do not support modification.
All elements except SourceElement indicate their
parent element using
MemberElement.getDeclaringClass(),
InitializerElement.getDeclaringClass(),
and
ClassElement.getSource().
Attaching a parentless element to a container element actually
creates a copy of the child element, which will then indicate the
proper parent element; the original child element's properties and
subhierarchy will be copied to the new child, though the proper
implementation (according to the parent) will be substituted. For
example, to add a new method to an parsed-source class element:
// Get a class element from the system (say, a Java source file):
ClassElement ce = ClassElement.forName ("com.mycom.FooClass");
// Now make up a method with an in-memory implementation:
MethodElement me = new MethodElement ();
// Set its properties:
me.setName (Identifier.create ("getFoo"));
me.setParameters (new MethodParameter[] { });
me.setReturn (Type.INT);
me.setExceptions (new Identifier[] { Identifier.create ("java.io.IOException") });
me.setModifiers (Modifier.PUBLIC | Modifier.STATIC);
me.setBody ("return 5;");
// Add a copy to the class element, actually adding the method to source
// code if writing is supported by the element hierarchy implementation:
ce.addMethod (me);
// public static int getFoo () throws IOException { return 5; }
All modifications to the element hierarchy structure, or to the
non-hierarchy-related properties of individual elements, fire
property change events according to the Java Event model. The names
of all required properties are available in
ElementProperties;
listeners may attach to an element using
Element.addPropertyChangeListener(...).
For example:
SourceElement src = ((SourceCookie) dataObject.getCookie (SourceCookie.class)).getSource ();
// Should also check for multiple top-level classes:
final ClassElement clazz = src.getClasses () [0];
clazz.addPropertyChangeListener (new PropertyChangeListener () {
public void propertyChange (PropertyChangeEvent ev) {
if (ElementProperties.PROP_METHODS.equals (ev.getPropertyName ())) {
MethodElement[] newMethods = clazz.getMethods ();
for (int i = 0; i < newMethods.length; i++)
System.out.println (newMethods [i].getName ());
}
}
});
External code may provide an
ElementPrinter,
which is essentially a set of callback hooks allowing the external
code to receive part or all of the element structure. For example,
an application that wanted to display the structure of a class with
dummy method bodies might do so as follows:
// Make room to add code:
final StringBuffer buf = new StringBuffer ();
// Source element obtained from somewhere:
SourceElement src;
// Print it:
src.print (new ElementPrinter () {
// Whether currently skipping over bodies:
private boolean skip = false;
// Print supplied text:
public void print (String text) {
if (! skip) buf.append (text);
}
public void println (String text) {
print (text + "\n");
}
// Will not truncate any part of field declarations:
public void markField (FieldElement elt, int what) {}
// Snip out the bodies:
public void markClass (ClassElement elt, int what) {mark (what);}
public void markConstructor (ConstructorElement elt, int what) {mark (what);}
public void markMethod (MethodElement elt, int what) {mark (what);}
private void mark (int what) {
if (what == ElementPrinter.BODY_BEGIN) {
print ("/* body... */");
skip = true;
} else if (what == ElementPrinter.BODY_END)
skip = false;
}
// Take out initializers altogether:
public void markInitializer (InitializerElement elt, int what) {
if (what == ElementPrinter.ELEMENT_BEGIN)
skip = true;
else if (what == ElementPrinter.ELEMENT_END)
skip = false;
}
});
// Get the result:
somehowDisplay (buf.toString ());
Element printers that only want the header, e.g., may throw
ElementPrinterInterruptException
in one of the mark methods to indicate that they have received all
of the text they will need. This is a little more efficient, e.g.,
if it desired to print just the header of a class, and not waste
time generating the following code.
As a shortcut, you may use
Element.toString()
to get the complete textual representation of an element, with all
components intact. This just invokes a trivial printer and collects
the results in a string. If only minor modifications to the default
behavior are needed,
DefaultElementPrinter
provides the obvious default implementation that just prints
everything, and it may be subclassed to refine this behavior.
ElementFormat
should be used as in this example:
MethodElement meth; // from somewhere
// e.g.: "public int getFoo (int type, String where) throws MyException, YourException;"
String theFormat = "{m,,\" \"}{r} {n} ({a,,,\", \"}){e,\" throws \",,\", \"};";
String prettyName = new ElementFormat (theFormat).format (meth);
This is used, for example, when creating display names for
element nodes. The default formats for
display names can be found in
SourceOptions.
org.openide.src.nodes
provides the node implementations used for this purpose. Normally
there is no reason for programmatic access to these nodes except by
the actual creator of the nodes, as changes should be done using
the elements themselves (and the nodes will keep their own display
in synch with the elements).
SourceElement) use a private default implementation
which holds all information in memory. However, new sources of
information for the hierarchy require separate implementation of
the WhicheverElement.Impl interfaces.
To start, you should generally provide a hook from which other
IDE components may access your hierarchy implementation. The
general way in which this is done is to start with a
data object
that you create, and attaching a
SourceCookie
to it to provide the source element at the top of a class's
hierarchy. If the data object is associated with an open
editor,
you may instead want to provide a
SourceCookie.Editor
so as to capture the correspondence - this will make it easy to find
points in the source code referred to by the element or its
children.
If you are in fact providing SourceCookie (or
SourceCookie.Editor) from a DataObject,
then you should also provide that same DataObject as a
cookie
from your SourceElement. This will permit the original
file to be retrieved based on the elements, which are sometimes
obtained through different channels.
The source element might create all of its children at once, or (preferably) create them lazily upon request. All elements except the source element should be created with the two-argument form of the constructor, passing in the parent element that is creating them, and the implementation of the element's functionality.
To create the implementations, you must implement the
subinterfaces of
Element.Impl
(according to the type of element). The required methods common to
all types of elements are:
Element.Impl.attachedToElement(...),
called when the associated element is first created to inform the
implementation of which element it is attached to. Some
implementations may not need to pay attention to this, depending on
the architecture.
Element.Impl.addPropertyChangeListener(...)
and
Element.Impl.removePropertyChangeListener(...)
should keep track of listeners to property changes (if the
implementation supports changes to elements at all). When any
aspect of an element is changed - either its basic properties (such
as value type), or its hierarchy properties (such as the list of
methods in a class), a property change event must be fired to all
listeners, using the property names specified in
ElementProperties
and the proper value type (e.g. MethodElement[]).
Element.Impl.getCookie(...)
should provide any
cookies
that this element wishes to expose. No cookies are required, but
special functionality could be added to the hierarchy: for example,
ViewCookie
could be attached to member elements to display Javadoc in the
IDE's Web browser, if this functionality were feasible. Then view
actions would be enabled when the element's node was selected in
the Explorer.
Note that both elements and their node representatives
automatically provide cookies for the element class itself, since
Element is also a type of cookie. This may be used,
for example, to determine if an arbitrary node represents an
element of some sort.
Element.Impl.readResolve()
must recreate some corresponding instance of the associated element
after deserialization. Typically you will just want to call the
two-element constructor of the corresponding element class, passing
in the implementation and no parent element
(i.e. null - it is the responsibility of the
deserialization code to reconstruct the hierarchy), or the sole
constructor in the case of SourceElement.
This method may not be required in a future version of the API, as it is possible to store the essential aspects of the source hierarchy without using direct serialization.
Particular implementation subinterfaces require more methods to
be implemented, but typically these are self-explanatory. For
example,
ConstructorElement.Impl.setExceptions(...)
should actually perform the work of changing the exceptions thrown
by a class in the underlying real object, and firing property
changes about it. Any of the modificational methods may simply
throw
SourceException
if they do not support modification of that aspect of the element;
read-only elements should just throw this exception on all write
methods.
Some methods add new pieces of the hierarchy, and you must
specially support this. For example, the implementation of
ClassElement.Impl.changeClasses(...)
must handle insertions into and removals from the hierarchy:
ClassElement.Impl object must be created for each
added inner classes, using your own class element implementation
but extracting all of its properties (name, etc.) from the
externally supplied classes. You should not try to modify the
supplied inner classes - these are only models.
ClassElement in the system (if there is one) which
represents that class.
One way of doing this is to assume that the class in question is
stored somewhere in the Repository, and to look through all
filesystems, trying to find the folder corresponding to the desired
package name, then looking through all data objects in each such
folder for something providing a SourceCookie (you
could just look for a file with the same basename as the desired
class, but this might not work for classes embedded in another
class's *.java file), then finding the right class
child of the SourceElements thus obtained. But this is
a fair amount of work and provides a number of failure points.
Instead,
ClassElement.forName(String)
attempts to find the right class element for you. This is done
using callbacks - i.e. all modules which wish to provide a
ClassElement.Finder
will have done so using
ClassElement.register(...).
Generally, those modules which provide hierarchy implementations
may also provide finders. For example, the standard Java source
module provides a finder which does something like the job
mentioned above, looking through the filesystems for
*.java files with the right contents. The standard
sourceless class module does a similar job for *.class
files, and also permits you to find classes which are simply in the
classpath, not the Repository (creating a "floating" element just
describing the result of introspection).
If you are writing a module which generates element hierarchies including class elements, you should consider implementing a finder, and registering it in the module's installed and restored methods. Generally such a finder should only look for class elements created by the same module (although if it can just as easily find other module's class elements, it may). If you expect the finder to be used very frequently, and it would normally have to search through the Repository to find the class elements, you may want to try to cache the results using some sort of weak-reference lookup table based on class name.
public class MyDataObject extends MultiDataObject implements SourceCookie {
// other code here...
// Actually create the top source element:
public SourceElement getSource () {/* ... */}
// provide the node for this object, complete with hierarchy:
public Node createNodeDelegate () {
Children kids = new SourceChildren (getSource ());
AbstractNode node = new DataNode (this, kids);
// Make FilterCookie available on the node, so the children can be rearranged by the user:
node.getCookieSet ().add (kids);
// Perform other customizations on the node now...
node.setIconBase ("/com/mycom/MyDataObjectIcon");
return node;
}
}
ElementNodeFactory.
Although it is not too difficult to implement from scratch, you may
prefer to subclass
DefaultFactory
(so as not to have to handle creation of error and wait nodes,
mostly).
Essentially, the factory methods should simply substitute your own subclassed (or externally customized) implementations of the various node types. For example:
class MyNode extends DataNode {
public MyNode (DataObject obj, Children children) {
super (obj, children);
setIconBase ("/my/Icon");
}
public SystemAction getDefaultAction () {
// provide some action to do something special with this source node...
}
}
class MyFactory extends DefaultFactory {
public MyFactory () {
super (true);
}
public Node createFieldNode (FieldElement elt) {
// Use the default impl, just make a trivial change externally:
AbstractNode node = new FieldElementNode (elt, true);
node.setDefaultAction (SystemAction.get (MySpecialFieldAction.class));
return node;
}
public Node createInitializerNode (final InitializerElement elt) {
// Actually use a specialized class:
return new InitializerElementNode () {
{ super (elt, true); }
// Support copy & paste of initializer bodies as text,
// including between initializer nodes:
public boolean canCopy () {
// The default, but just to be sure:
return true;
}
public Transferable clipboardCopy () throws IOException {
Transferable basic = super.clipboardCopy ();
ExTransferable extended = ExTransferable.create (basic);
extended.put (new ExTransferable.Single (DataFlavor.stringFlavor) {
protected Object getData () {
return elt.getBody ();
}
});
return extended;
}
public void createPasteTypes (Transferable t, List s) {
super.createPasteTypes (t, s);
if (t.isDataFlavorSupported (DataFlavor.stringFlavor)) {
try {
String addedBody = (String) t.getTransferData (DataFlavor.stringFlavor);
s.add (new PasteType () {
public String getName () { return "Paste initializer body"; }
public Transferable paste () throws IOException {
try {
elt.setBody (elt.getBody () + addedBody);
} catch (SourceException se) {
throw new IOException (se.getMessage ());
}
return null;
}
});
} catch (Exception ex) { /* ... */ }
}
}
};
}
}
public Node createNodeDelegate () {
ElementNodeFactory myFactory = new MyFactory ();
Children kids = new SourceChildren (myFactory, getSource ());
return new MyNode (this, kids);
}
class MyMethodNode extends MethodElementNode {
public MyMethodNode (MethodElement elt) {
// Read-only:
super (elt, false);
// Display name will be, e.g., "method: public int getFoo (...)"
setElementFormat (new ElementFormat ("method: {m,,\" \"}{r} {n} (...)"));
}
// Give it a special icon depending on whether it is static or not:
public String resolveIconBase () {
return elt.isStatic () ? "/my/StaticMethodIcon" : "/my/VirtualMethodIcon";
}
// Add an expert property to the node's property sheet:
protected Sheet createSheet () {
Sheet sheet = super.createSheet ();
Sheet.Set ps = sheet.get (Sheet.EXPERT);
if (ps == null) ps = Sheet.createExpertSet ();
ps.put (new PropertySupport.ReadWrite () {
{ super ("isBrokenAt", Boolean.TYPE, "Broken here?",
"Whether or not a breakpoint is set on this method."); }
public Object getValue () {
return TopManager.getDebugger ().findBreakpoint (elt) == null ?
Boolean.FALSE : Boolean.TRUE;
}
public void setValue (Object newVal) {
if (newVal.equals (getValue ())) return;
boolean bp = (Boolean) newVal.booleanValue ();
if (bp) {
TopManager.getDebugger ().createBreakpoint (elt);
} else {
TopManager.getDebugger ().findBreakpoint (elt).remove ();
}
}
// (Should also listen to changes in breakpoints.)
});
sheet.put (ps);
return sheet;
}
}
SourceChildren
or
ClassChildren
to generate this list of children for you. The standard children
implementations also automatically keep track of additions and
removals in the associated element and update the node accordingly.
However, the default behavior of these children lists is to include all the children which are normally considered relevant, and to ignore access permissions. For some applications, this is inappropriate - you may want to provide only some children, in a particular order. This should be done using a filter on the standard children implementation.
For example, the following code creates a factory for a class node which only wants to display public or protected methods, fields, and inner classes (i.e., the "API" members).
final ElementNodeFactory factory = new DefaultFactory () {
public Children createClassChildren (ClassElement clazz) {
ClassChildren children = new ClassChildren (factory, clazz);
ClassElementFilter filter = new ClassElementFilter ();
filter.setModifiers (ClassElementFilter.PUBLIC | ClassElementFilter.PROTECTED);
filter.setOrder (new int[] { ClassElementFilter.CLASS | ClassElementFilter.INTERFACE,
ClassElementFilter.FIELD,
ClassElementFilter.METHOD });
children.setFilter (filter);
return children;
}
};
When you are creating a top-level node to represent a source
element, typically there may be other children under that node
besides the subelements of the source element. For example, the
node representing a form in the standard IDE module has children
(actually, just one) for the top-level classes in the source; but
it also has a child node representing the AWT component hierarchy
for inspection or editing. If you wish to add such additional
nodes, you may do so, taking advantage of the fact that
SourceChildren is a
Children.Keys;
just add your own children under whatever kind of key you like.