Example Applications
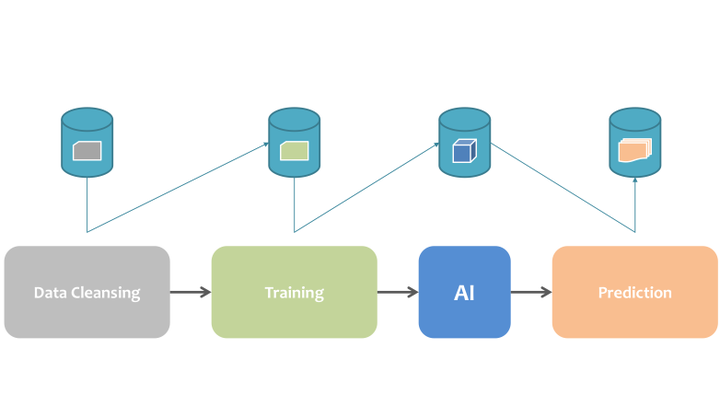
MLCask supports both linear and non-linear version control semantics for ML pipelines of different applications. Here, let us consider the use case of readmission.
Linear Version Control Semantics
We use Directed Acyclic Graph (DAG) to formulate an ML pipeline. A semantic version in MLCask is represented by an identifier: branch@schema.increment, where branch represents the Git-like branch semantics, schema denotes the output data schema, and increment represents the minor incremental changes that do not affect the output data schema.
With the designed semantic version, MLCask is able to provide the component compatibility check: if the output data schema of a component changes, the succeeding component should perform at least one increment update to ensure its compatibility.

The above figure shows the total time for MLCask and two baseline systems, i.e., ModelDB and MLflow, for the readmission application. MLCask consumes less time than ModelDB because linear version control semantics enables MLCask to reuse intermediate results. At the last iteration, MLCask detects the incompatibility and does not run the pipeline, which leads to less total time than MLflow.

The above figure shows the comparison in terms of the cumulative storage size (CSS). Due to the version control semantics for libraries, MLCask saves a lot of storage from the first iteration when all libraries are stored and de-duplicated.
Non-Linear Version Control Semantics

Apart from linear versioning, MLCask additionally supports non-linear versioning to facilitate collaborative development between different users.
Consider the scenario where users Jane and Frank work on their branches separately for the readmission application. User Jane commits a new version of the CNN model (indicated by purple) and the data cleansing method while another user Frank commits a new version of the feature extraction method (indicated by blue) and the CNN model separately in two branches, i.e., “Jane-dev” and “Frank-dev”. NLCask supports merging the pipeline updates from both users and searching for the best component combination among a massive amount of possible combinations of updates based on performance metrics.

To facilitate the search for the optimal combination of pipeline component updates, we propose to build a pipeline search tree as the above figure shows to represent all possible pipelines.
However, the number of pipeline candidates increases dramatically when the number of past commits increases, which may render the merge operation extremely time-consuming. We thus propose two tree pruning methods based on incompatible information and reusable outputs respectively to accelerate the merge operation.
Specifically, there are three types of nodes denoted with different colors: The nodes in green color already have checkpoints in the development history. The nodes in red color are not executable due to the incompatibility between pipeline components. Finally, the nodes in orange, called feasible nodes, are the remaining nodes that need to be executed.

The above figure shows the comparison results in terms of cumulative pipeline time, cumulative storage cost, cumulative execution time, and cumulative storage time. Let us focus on the readmission pipeline. These results confirm the effectiveness in pruning the pipeline search tree using component compatibility (PC) and reusable outputs (PR). The proposed MLCask dominates the comparison in all metrics.