
| XHTML / DIV
Evaluation |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| • | Smaller dataset |
||||||||||||||
| – | 1/5 the size,
limited |
||||||||||||||
| sites for sample |
|||||||||||||||
| – | Both annotated |
||||||||||||||
| and unannotated |
|||||||||||||||
| data sets were |
|||||||||||||||
| smaller |
|||||||||||||||
| – | As a result,
fewer |
||||||||||||||
| co-training |
|||||||||||||||
| iterations |
|||||||||||||||
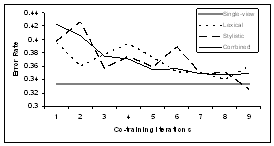
| • | Single view
model still |
||||||||||||||
| seems to do
better |
|||||||||||||||
|
|
|
|
| • | Single view = all features |
||
| • | Combined = most confident of l and s
learners |
||