| Rough
grained model |
|
|
|
|
|
|
|
|
|
|
|
|
| • | Slightly
different |
||||||||||
| model of
splitting than |
|||||||||||
| earlier work |
|||||||||||
| • | Smaller amount of |
||||||||||
| training examples |
|||||||||||
| • | No significant
gain |
||||||||||
| from co-training
but |
|||||||||||
| comparable to
other |
|||||||||||
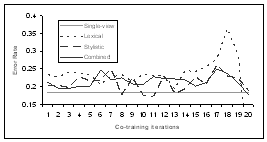
| work (19.5%
error vs. |
|||||||||||
| 14-18 error%) |
|||||||||||