Min-Yen Kan and Danny C. C. Poo
Known Item Queries (JCDL 2005)
20/25


Task 1: Query Classification
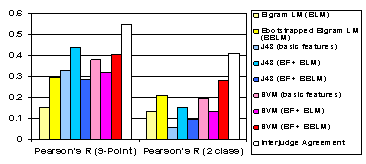
• 9-point task easier
(data is more fine-grained)
• Bootstrapped language
model performs better alone and with SVMs
• BBLM may have noise (due to coarse binning), SVM may handle noisy data better
• Decision trees favors ordinary bigram language model
• Best performer does
about 80% of human performance on 9-point scale
(.438 / .546, J48 decision tree with bigram language model)

Majority Baseline: 0 Correlation
SVMs (red)

Decision
Trees (blue)
Trees (blue)