Failure in Machine Unlearning and How to Guarantee Deletion
$$
\newcommand{\dif}[1]{\mathrm{d} #1}
\newcommand{\der}[2]{\frac{\dif{#1}}{\dif{#2}}}
\newcommand{\doh}[2]{\frac{\partial #1}{\partial #2}}
\newcommand{\graD}[1]{\nabla #1}
\newcommand{\divR}[1]{\mathrm{div} \left(#1\right)}
\newcommand{\lapL}[1]{\Delta #1}
\newcommand{\hesS}[1]{\nabla^2 #1}
\newcommand{\jacO}[1]{\mathbf{J} #1}
\newcommand{\tra}[1]{\textsf{Tr}\left(#1\right)}
\newcommand{\dotP}[2]{\left\langle#1,#2\right\rangle}
\newcommand{\detR}{\mathrm{det}}
\newcommand{\norm}[1]{\left\Vert #1 \right\Vert_2}
\newcommand{\ve}{\ensuremath{\mathbf v}}
\newcommand{\V}{V}
% Probability related macros
\newcommand{\prob}[2]{\underset{#1}{\mathbb{P}}\left[#2\right]}
\newcommand{\pspace}{\mathcal{P}}
\newcommand{\lap}[1]{\text{Lap}\left(#1\right)}
\newcommand{\expec}[2]{\underset{#1}{\mathbb{E}}\left[#2\right]}
\newcommand{\Gaus}[2]{\mathcal{N}\left(#1, #2\right)}
\newcommand{\Id}{\mathbb{I}_\dime}
\newcommand{\noise}{\sigma}
\newcommand{\Z}{\mathbf{Z}}
\newcommand{\forget}{u}
\newcommand{\Out}{O}
\newcommand{\Outb}{\bar{\Out}}
\newcommand{\Ze}{\mathbf{W}}
\newcommand{\indic}[1]{\mathbbm{1}\left\{#1\right\}}
\newcommand{\W}{\mathbf{W}}
\newcommand{\pI}{\uppi} % Asmyptotic distribution
\newcommand{\psI}{\psi}
\newcommand{\Gen}{\mathcal G} % Generator of Langevin diffusion
\newcommand{\carre}{\Gamma}
\newcommand{\Ent}{\mathrm{Ent}}
\newcommand{\entropy}{\textrm H}
\newcommand{\p}{p}
\newcommand{\nU}{\upnu}
\newcommand{\mU}{\upmu}
\newcommand{\rhO}{\uprho}
% ERM
\newcommand{\X}{\mathcal{X}} % Data space
\newcommand{\Y}{\mathcal{Y}} % Output space
\newcommand{\C}{\mathcal{O}} % Output/parameter space
\newcommand{\dime}{d} % Dimension of parameters
\newcommand{\domain}{\R^\dime} % Parameter space for deep learning
\newcommand{\R}{\mathbb{R}} % Real numbers
\newcommand{\N}{\mathbb{N}} % Natural numbers
\newcommand{\Pub}{\Phi} % space of publishable outcomes
\newcommand{\pub}{\phi} % publishable outcomes
\newcommand{\D}{\mathcal{D}} % Database
\newcommand{\n}{n} % Number of records in database
\newcommand{\Lrn}{\mathrm{A}}
\newcommand{\Unlrn}{\bar{\Lrn}} % Unlearning algorithm
\newcommand{\Nsgd}{\text{Noisy-GD}}
\newcommand{\Pgd}{\text{PGD}}
\newcommand{\x}{\mathbf{x}} % Single datapoint from data universe
\newcommand{\thet}{\theta} % Parameter value
\newcommand{\Thet}{\Theta} % Parameter random variable
\newcommand{\loss}{\boldsymbol{\ell}} % Loss function on a datapoint
\newcommand{\rloss}{\bar\loss}
\newcommand{\reg}{\mathbf{r}} % Regularizer
\newcommand{\ltwo}{L2} % L2 norm
\newcommand{\Loss}{\mathcal{L}} % Loss function on a database
\newcommand{\rLoss}{\Loss} % Regularized loss function on a database
\newcommand{\err}{\mathrm{err}} % Empirical risk
\newcommand{\risk}{\alpha}
\newcommand{\q}{q} % Renyi divergence order
\newcommand{\eps}{\varepsilon} % Privacy/indistinguishability budget parameter
\newcommand{\epsdp}{\eps_{\mathrm{dp}}} % RDP budget parameter
\newcommand{\epsdd}{\eps_{\mathrm{dd}}} % Data deletion budget parameter
\newcommand{\del}{\delta} % Probability of breach in Privacy/indistinguishability
\newcommand{\cost}{C} % Computational cost
\newcommand{\step}{\eta} % Step size
\newcommand{\K}{K} % Number of steps
\newcommand{\ze}{\zeta} % mapping iteration k to dataset i
\newcommand{\batch}{\mathcal{B}} % subsampled batch
\newcommand{\bsize}{b} % batch size
\newcommand{\h}{h} % subgaussian
\newcommand{\Sam}{\mathcal{S}} % sampling mechanism
\newcommand{\cvx}{\lambda}
\newcommand{\lip}{L}
\newcommand{\Clip}{\mathrm{Clip}}
\newcommand{\Proj}{\mathrm{Proj}}
\newcommand{\smh}{\beta}
\newcommand{\G}{G} % Sub-Gaussian
\newcommand{\B}{B} % bound on loss
\newcommand{\conv}{\circledast}
\newcommand{\grad}{\mathbf{g}} % stochastic gradient
% Unlearning
\newcommand{\y}{\mathbf{y}} % Single datapoint from data universe
\newcommand{\up}{u} % Database update request
\newcommand{\Up}{U} % Database update request random variable
\newcommand{\ind}{\mathrm{ind}}
\newcommand{\U}{\mathcal{U}} % Database update reqeust space
\newcommand{\reps}{r} % Max number of records edited
\newcommand{\delete}{\mathbf{I}_d}
\newcommand{\append}{\D_a}
\newcommand{\sen}{S}
\newcommand{\prox}{\mathrm{prox}}
\newcommand{\publish}{f_{\mathrm{pub}}}
\newcommand{\updreq}{\mathcal{Q}}
% Data-deletion
\newcommand{\pubs}{p}
% Unlearning vs. Data-deletion notations
\newcommand{\query}{h} % Notation for count query
\newcommand{\median}{\mathrm{med}} % Notation for median
% LSI
\newcommand{\LS}{\mathrm{LS}}
\newcommand{\lsi}{c} % LSI constant
\newcommand{\T}{T} % bijective map
% \newcommand{\alp}{\alpha}
% \newcommand{\bet}{\beta}
\newcommand{\eqdef}{\stackrel{\text{def}}{=}}
% divergence measures
\newcommand{\approxDP}[1]{\overset{#1}{\approx}} % (\eps, \del)-indistinguishability
\newcommand{\KL}[2]{\mathrm{KL}\left(#1\middle\Vert#2\right)} % KL divergence
\newcommand{\Fis}[2]{\mathrm{I}\left(#1\middle\Vert#2\right)} % Fisher information
\newcommand{\Was}[2]{\mathrm{W}_2\left(#1,#2\right)}
\newcommand{\Ren}[3]{\mathrm{R}_{#1}\left(#2\middle\Vert#3\right)} % Renyi divergence
\newcommand{\Eren}[3]{\mathrm{E}_{#1}\left(#2\middle\Vert#3\right)} % qth moment of likelihood ratio
\newcommand{\Gren}[3]{\mathrm{I}_{#1}\left(#2\middle\Vert#3\right)} % qth moment of likelihood ratio
\newcommand{\TV}[1]{\mathbf{TV}\left(#1\right)}
\newcommand{\Test}{\text{Test}}
\newcommand{\Testb}{\overline{\text{Test}}}
$$
Unlearning algorithms aim to remove deleted data’s influence from trained models at a cost lower than full retraining. However, we show that existing Machine Unlearning definitions don’t protect the privacy of deleted records in the real world. The primary reason is that when users request deletion as a function of models trained on their data, records in a database become interdependent—past records influence what future records might be present. So, even retraining a fresh model after deletion of a record doesn’t ensure its privacy because by looking at the current behavior due to present records, an attacker can infer the kinds of records that existed in the past, even if they were since deleted. Secondly, we show that unlearning algorithms that cache partial computations to speed up the processing can leak deleted information over a series of releases, violating the privacy of deleted records in the long run. To address these, we propose a sound deletion guarantee and show that the privacy of existing records is necessary for the privacy of deleted records in the future. Under this notion, we propose an accurate, computationally efficient, and secure machine unlearning algorithm based on Noisy Gradient Descent. Check out our work’s full version > (edit: or my PhD thesis >).
Machine Unlearning
Machine Unlearning is a relatively new notion of deletion privacy that is becoming increasingly important. The need for deletion arises from an evolved understanding that data privacy requires a strong commitment to self-determinism, which is the power of individuals to decide if, to what extent, and how their personal information is collected, used, and shared. Modern day privacy policies, such as General Data Protection Regulation (GDPR) in the European Union and California Consumer Protection Act (CCPA) in the United States, enforces the principle of self-determination by granting individuals the right to rectify or erase their data.
In the era of Deep Learning, information in modern ML models, such as neural networks, is no longer encoded in human interpretable way, making it extremely challenging to selectively edit. The conventional (and fool-proof) way is to modify the underlying dataset and retrain the models from scratch to reflect the changes. However, retraining fresh ML models from scratch every time the dataset changes is computationally expensive. Therefore there is a growing interest in designing cheap machine unlearning algorithms for erasing the influence of deleted data from already trained models. To quantify how well an unlearning algorithm erases the requested information in the worst-case, propose a DP like $(\eps, \del)$-indistinguishability between the unlearning algorithm’s output and that of fresh retraining.
($(\eps, \del)$-unlearning).
For a fixed dataset $\D \in \X^*$, remove set $\forget \subset \D$, a randomized learning algorithm $\Lrn$ and a publish function $\publish$, an unlearning algorithm $\Unlrn$ is $(\eps, \del)$-unlearning with respect to $(\D, \forget, \Lrn)$ if for all $S \subset \Y$ where $\Y$ denotes the output space, we have:
$$
\begin{align*}
\prob{}{\publish(\Unlrn(\D, \forget, \Lrn(\D))) \in S}&\leq e^\eps \cdot \prob{}{\publish(\Lrn(\D \setminus \forget)) \in S} + \del, \quad \text{and} \\\\
\prob{}{\publish(\Lrn(\D \setminus \forget)) \in S} &\leq e^\eps \cdot \prob{}{\publish(\Unlrn(\D, \forget, \Lrn(\D))) \in S} + \del.
\end{align*}
$$
The idea behind this definition is very simple. If there is no way to distinguish the published observable $\publish(\cdot)$ of an unlearned model $\Unlrn(\D, \forget, \Lrn(\D))$ from that of a fresh model $\Lrn(\D \setminus \forget)$ trained without the deleted data-points, then the unlearned model must not contain any information about the deleted records anymore. Several unlearning certifications, that follow the same intuition, have since been proposed and used to certify numerous unlearning algorithms that belong to the family of iterative first-order gradient methods.
Almost all real-world applications of machine unlearning need to handle streaming addition/deletion requests, first studied by Neel et al., 2021. In this setting, a stream of edit requests, comprised of a batch of addition, deletion or replacement operations, arrives sequentially.
(Edit request).
A replacement operation $\langle \ind, \y \rangle \in [\n] \times \X$ on a database ${\D = (\x_1, \cdots, \x_n) \in \X^\n}$ performs the following modification:
$$
\begin{equation}
\D \circ \langle \ind, \y \rangle = (\x_1, \cdots, \x_{\ind-1}, \y, \x_{\ind+1}, \cdots, \x_\n).
\end{equation}
$$
An edit request $\up = \{\langle \ind_1, \y_1\rangle, \cdots, \langle \ind_\reps, \y_\reps\rangle \}$ on $\D$ is defined as batch of $\reps \leq \n$ replacement operations modifying distinct indices atomically, i.e.
$$
\begin{equation}
\D \circ \up = \D \circ \langle \ind_1, \y_1\rangle \circ \cdots \circ \langle \ind_\reps, \y_\reps\rangle,
\end{equation}
$$
where $\ind_i \neq \ind_j$ for all $i \neq j$.
Depiction of an edit request modifying a dataset.
The data curator, characterized by a pair of learning and unlearning algorithms $(\Lrn, \Unlrn)$, executes the learning algorithm $\Lrn$ on the initial dataset $\D_0$ during the setup stage before the arrival of the first edit request to generate the initial model $\Theta_0 = \Lrn(\D_0)$. Thereafter, at any edit step $i \geq 1$, to reflect an edit request $\forget_i$ that transforms the dataset $\D_{i-1} \circ \forget_i \rightarrow \D_i$, the curator runs the unlearning algorithm $\Unlrn$ to get the next model $\Theta_i = \Unlrn(\Theta_{i-1}, \forget_i, \D_{i-1})$. Furthermore, the curator keeps the (un)learned models $(\Thet_i)_{i\geq0}$ secret, only releasing corresponding publishable objects $\pub_i = \publish(\Thet_i)$, generated using some publish function $\publish$. Such publishable objects could be model predictions on an external dataset, noisy model releases, or any downstream model use.
Detailed visualization of the streaming unlearning setup.
Adaptive Unlearning
In real world, deletion requests are often adaptive in nature, influenced by the behavior of prior published outcomes. For instance, security researchers may demonstrate privacy attacks targeting a minority subpopulation on publicly available models, causing people in that subpopulation to request deletion of their information from training data. Gupta et al., 2021 model such an interactive environment through an adaptive update requester. We provide the following generalized definition of Gupta et al., 2021’s update requester and describe its interaction with a data curator in Algorithm 1.
(Update requester).
At any step $i \in \N$, an update requester $\updreq$ inputs a subset of interaction history $(\phi_0, \up_1, \phi_1, \cdots, \up_{i-1}, \phi_{i-1})$ between themself and the curator $(\Lrn, \Unlrn)$ to generate the subsequent edit request $\up_i$. That is, for an ordered set of integers $(s_1, \cdots, s_j) \subset [i]$ denoting all the steps before $i$ that requester $\updreq$ can observe, the edit request $\up_i$ generated by $\updreq$ on interaction with the curator is given by
$$
\begin{equation}
\up_i = \updreq(\underbrace{\pub_{s_1}, \pub_{s_2}, \cdots, \pub_{s_j}}_{\eqdef \pub_{\vec{s} < i}}; \underbrace{\up_1, \up_2, \cdots, \up_{i-1}}_{\eqdef \up_{< i}}).
\end{equation}
$$
It is useful to consider the sequence of indices $\vec{s}$ as the planned versions of publishable outcomes to be released as and when generated by the curator. Outcomes at these time steps will have an influence on the world, which in-turn will affect the subsequent requests and corresponding releases.
Visualization of an adaptive edit requester $\updreq$ that looks at a (subset of) past outcome releases to (stochastically) determine the next edit request to issue.
The above figure depicts an example of an adaptive requester $\updreq$ modelling the interactive nature of the real-world edit requests inserting, deleting, or replacing entries in response to past outcomes released by the curator $(\Lrn, \Unlrn, \publish)$.
We refer to a requester $\updreq$ that never gets to see any of the past releases (i.e., $\pub_{\vec{s} <i} = \emptyset$ for all $i \in \N$) as being non-adaptive. Similarly, we consider a requester that gets to see all the past releases (i.e., $\pub_{\vec{s} < i} = (\pub_0, \cdots, \pub_{i-1})$) as being fully-adaptive. A middle-ground is an update requester that gets to see at most $\pubs$ releases ever (i.e., $\vert\vec{s}\vert \leq \pubs$), which we say is $\pubs$-adaptive.
(Adaptive Machine unlearning).
We say that an algorithm $\Unlrn$ is a non-adaptive $(\eps, \del)$-unlearning algorithm for $\Lrn$ under a publish function $\publish$, if for all initial datasets $\D_0 \in \X^\n$ and all non-adaptive requesters $\updreq$, the following condition holds. For every edit step $i \geq 1$, and for all generated edit sequences ${\up_{\leq i} \eqdef (\up_1, \cdots, \up_i)}$,
$$
\begin{equation}
\label{eqn:unlearn_neel}
\publish(\Unlrn(\D_{i-1}, \up_i, \Theta_{i-1})) \big|_{\up_{\leq i}} \approxDP{\eps,\del} \publish(\Lrn(\D_i)),
\end{equation}
$$
where $X\approxDP{\eps,\del}Y$, for any two random variables $X, Y$, denotes $(\eps, \del)$-DP like indistinguishability between them. If the above equations holds for all fully-adaptive requesters $\updreq$, we say that $\Unlrn$ is an $(\eps, \del)$-adaptive-unlearning algorithm for $\Lrn$.
Flaws in Unlearning
"The controller shall have the obligation to erase personal data without undue delay where ... the data subject withdraws consent ..."
— Right to be Forgotten, Article 17(1)(b), GDPR.
Now we expose some critical limitations of prior unlearning certifications when it comes to upholding the ``Right to be Forgotten’’. These limitations manifest under a threat model that is actualized in reality. We highlight multiple reasons why both adaptive and non-adaptive machine unlearning, as described in its definition, are inadequate in addressing the following threat model.
Threat Model
The RTBF guidelines in GDPR and CCPA require permanent deletion of personal information, regardless of its form, and without undue delay after receipt of a legitimate deletion request from the user. Considering that data curators are given a grace period to process deletion requests, we must assume in our threat model that an attacker targeting a record deleted at the $i^\mathrm{th}$ step can only observe releases by the curator after deletion. In other words, the attacker sees all post-deletion releases ${\pub_{\geq i} \eqdef (\pub_i, \pub_{i+1}, \cdots)}$.
Furthermore, we make another assumption about the attacker that makes it considerably stronger—the attacker has arbitrary knowledge about how some users may react to certain published outcomes. This assumption is central to the attack vector arising due to the adaptive nature of the real-world. Even though our attacker can only see published objects after the deletion request has been processed, she can try and deduce what was deleted by looking for patterns among other data records arising due to the original presence of the deleted data based on her understanding of the world. That is to say, our attacker knows a little about how people react to things in general, without actually knowing what they reacted to and how in this specific interactions with the curator. Since $\updreq$ encapsulates all the interactions the entire collection of users can have with the curator, our assumption is simple—attacker knows $\updreq$.
The goal of the attacker is to figure out what was deleted at step $i$ by the request $\up_i$.
Failure under Adaptivity
Machine Unlearning guarantees are not trustworthy when the addition/deletion requests are adaptive. Before we dive into the technical reasons, let’s look at a couple of illustrative examples to identify the root cause of the failure.
Consider the case of Sam Yang, a renowned Canadian digital illustrator with hundreds of artworks posted on Instagram and a follower count exceeding 2.1 million. Figure (a) below shows an original artwork by Sam titled "Night scene with Kara."
A real-life example where even retraining does not ensure total deletion.
Recently, a Redditor utilized Stability AI, a deep-learning platform for creating custom generative models, to train a stable-diffusion model—denoted as $\Theta_0$—using a dataset $\D_0$ exclusively comprised of Sam's artworks. The Redditor then posted examples of generated images online (denoted as $\pub_0$), such as the one shown in Figure (b) above. Soon after, internet users began generating and posting stylistic copies on Reddit.
Infuriated by this, Sam Yang, along with several other illustrators, filed a class-action lawsuit against Stability AI and Midjourney for copyright infringement. Since the uploads of stylistic copies and the deletion of original artworks occurred almost simultaneously, let's refer to these actions collectively as a single batched edit request $\up_1$. In response to the lawsuit, an anonymous Redditor curated a dataset $\D_1 = \D_0 \circ \up_1$ that contained only the stylistic copies, excluding Sam's originals, to circumvent copyright infringement. Figure (c) above depicts a second-generation stylistic copy $\pub_1$ produced by a model $\Theta_1 = \Lrn(\D_1)$ trained solely on synthetic images. It is evident that Sam's distinctive art style persists, even after retraining from scratch without his original works!
To understand the cause of this problem under adaptivity more analytically, let’s consider a simplified variant of this problem.
For a data domain $\X = \{-2, -1, 1, 2\}$, consider the following learning and unlearning algorithms $(\Lrn, \Unlrn)$. For any dataset $\D \subset \X$ and any subset $S \subset \D$ of records to be deleted,
$$
\begin{equation}
\Lrn(\D) = \sum_{\x \in \D} \x, \quad \text{and} \quad \Unlrn(\D, S, \Lrn(\D)) = \sum_{\x \in \D \setminus S} \x,
\end{equation}
$$
Note that the unlearning algorithm $\Unlrn$ perfectly imitates the learning algorithm $\Lrn$ as for any deletion request $\up \subset \D$, we have $\Unlrn(\D, \up, \Lrn(\D)) = \Lrn(\D \setminus \up)$. Now consider two neighboring datasets $\D_{-1} = \{-2, -1, 2\}$, $\D_{1} = \{-2, 1, 2\}$ and the following dependence between the learned model $\Lrn(\D)$ and deletion request $\up$:
$$
\begin{equation}
\up = \begin{cases} \{\x \in \X | \x < 0\} &\text{if}\ \Lrn(\D) < 0, \\ \{\x \in \X | \x \geq 0\} &\text{otherwise.}\end{cases}
\end{equation}
$$
Knowing this dependence, an attacker can distinguish whether $\D$ is $\D_{-1}$ or $\D_{1}$ by looking solely at $\Unlrn(\D, \x, \Lrn(\D))$. This is because if $\D = \D_{-1}$, then the output after deletion is positive, and if $\D = \D_{1}$ the output is negative. Note that even though $\Unlrn$ perfectly imitates retraining via $\Lrn$ and the attacker does not observe either the model $\Lrn(\D)$ or the request $\up$, she can still ascertain the identity ($-1$ or $1$) of a deleted record. This example demonstrates two things:
A) Adaptive requests can cause the curator's dataset to have patterns specific to the identity of a target record being deleted.
B) An attacker knowing the relationship between unobserved releases and deletion requests can infer the identity of the target record by observing only the unlearned model, even if the curator did full retraining.
Given the adaptive nature of the real-world interactions, several data deletion definitions in the literature, such as those proposed by , , and , that quantify data-deletion based on indistinguishability from retraining do not provide reliable certifications for the “Right to be Forgotten”. Even the Adaptive unlearning definition, which was specifically designed to ensure RTBF under adaptive deletion requests, fails catastrophically under adaptivity!
Failure with Hidden-States
Both adaptive and non-adaptive unlearning guarantees are bounds on information leakage about a deleted record through a single released output. However, a real-world adversary would most likely observe multiple (potentially all) releases $\phi_{>i}$ after deletion. This can lead to another violation of RTBF, even when edit requests are non-adaptive.
Demonstrating the problem with secret states in $(\eps,\del)$-unlearning as defined here. Consider a data-point deleted by first edit request $\up_1$. Secret states $\Theta_1, \Theta_2, \cdots$ can carry unbounded information about this deleted record while $\publish$ ensures each individual release carries no more than $(\eps, \del)$ amount of information about deleted records. Since each future release can reveal this much new information, the total leakage composes without any limits.
This vulnerability arises because many unlearning definitions permit the curator to store secret models while requiring indistinguishability only over the output of a publishing function $\publish$. These secret models may propagate encoded information about records even after their deletion from the dataset. So, every subsequent release by an unlearning algorithm can reveal new information about a record that was purportedly erased multiple edits earlier. That is, an adversary that observes enough future releases may learn everything about the deleted record through the post-deletion releases!
Incompleteness
Finally, the $(\eps, \del)$-unlearning guarantee disregards perfectly valid deletion algorithms. For instance, an algorithm $\Unlrn$ that outputs a fixed untrained model $\theta \in \Y$ in response to any deletion request $\forget$ is a valid deletion algorithm because its output contains no information about the deleted records in $\forget$. However, since its fixed output $\theta$ is easy to tell apart from that of retraining done by any sensible learning algorithm $\Lrn$, the algorithm $\Unlrn$ cannot satisfy this definition, or this definition, or any other unlearning variants in literature. In other words, machine unlearning guarantees are incomplete quantifiers of data deletion.
Trustworthy Data-Deletion
To address these issues with existing notions of unlearning, let’s introduce a new definition of deletion privacy.
($(\eps, \del)$-deletion privacy).
An algorithm pair $(\Lrn, \Unlrn)$ satisfies $(\eps, \del)$-deletion privacy if for all datasets $\D$ and all edit requests $\forget$ (potentially chosen reactively after seeing $\Lrn(\D)$), we have that for all records $\x \in \D$ that gets deleted by $\forget$, there exists a random variable $\Theta_\x$ that is independent of the data-point $\x$ such that
$$
\begin{equation}
\forall S \in \Y, \quad \prob{}{\Unlrn(\D, \forget, \Lrn(\D)) \in S} \leq e^\eps \cdot \prob{}{ \Theta_\x \in S} + \del.
\end{equation}
$$
Firstly, using secret states that depend on deleted records to speed up unlearning can violate RTBF. To prevent such violations, our definition directly quantify deletion for an unlearned model rather than after applying any publish function, i.e., setting $\publish(\theta) = \theta$
Secondly, as demonstrated previously, adaptive requests can encode patterns specific to a target record which persists in the dataset even after deletion of the target record, making indistinguishable-from-retraining based deletion certifications unreliable. Our definition accounts for the worst-case influence adaptive requests by measuring the indistinguishability of an unlearning mechanism’s output from that of some constructed random variable $\Theta_\x$ that must be independent of the deleted record by design.
Soundness of $(\eps, \del)$-deletion privacy. The above definition reliably safeguards the “Right to be Forgotten” as the random variable $\Theta_\x$ stays independent of the deleted record $\x$ by design, even when the update requester $\updreq$ is fully-adaptive. When an attacker aims to identify a record in $\D$ that is being deleted in edit request $\up$, the inequality in the definition ensures that any observer of the unlearned model $\Unlrn(\D, \up, \Lrn(\D))$ cannot be overly certain that the observation was not $\Theta_\x$ instead. Hence, the unlearned model itself must possess minimal information regarding the deleted record $\x$. This argument allows us to establish the following guarantee of soundness.
If the algorithm pair $(\Lrn, \Unlrn)$ satisfies $(\eps, \del)$-deletion privacy guarantee under all $\pubs$-adaptive requesters, then any attacker ${\text{MI}: \Y^* \rightarrow \{0,1\}}$ observing only the post-deletion models $\Theta_{\geq i} = (\Theta_i, \Theta_{i+1}, \cdots) \in \Y^*$ after processing the request $\up_i$ has an advantage
$$
\begin{equation}
\text{Adv}(\mathrm{MI}) \eqdef \prob{}{\mathrm{MI}(\Theta_{\geq i}) = 1 \big| \x} - \prob{}{\mathrm{MI}(\Theta_{\geq i}) = 1 \big| \x'}
\end{equation}
$$
for disambiguating between two possible values $\x, \x' \in \X$ of a record in $\D_{i-1}$ deleted by request $\up_i$ bounded as follows.
$$
\begin{equation}
\label{eqn:adv_sound}
\text{Adv}(\mathrm{MI}) \leq e^\eps - 1 + 2\del.
\end{equation}
$$
Link to Differential Privacy
A differential privacy guarantee on $\Lrn$ and $\Unlrn$ sets a limit on the information present in an unlearned model regarding individual records that remain in the dataset. However, our concept of deletion privacy specifically restricts the information concerning only the deleted records. These two notions are orthogonal—an algorithm pair $(\Lrn, \Unlrn)$ can satisfy $(\epsdd,\del)$-deletion privacy without providing $(\epsdp,\del)$-differential privacy for any $\infty > \epsdp > 0$. These two notions are also compatible—an algorithm pair $(\Lrn, \Unlrn)$ can simultaneously satisfy $(\epsdp,\del)$-differential privacy and $(\epsdd, \del)$-deletion privacy with $\epsdd \ll \epsdp$ for non-adaptive update requesters $\updreq$.
However, the two types of privacy certifications are connected—an $(\epsdp,\del)$-differential privacy is both a necessary and a sufficient condition to ensure that a non-adaptive $(\epsdd, \del)$-deletion privacy guarantee for $(\Lrn, \Unlrn)$ extends to adaptive settings (which is significantly more challenging) with a graceful degradation in deletion certification.
Sufficiency
For the sufficient part, note that when $\Lrn$ and $\Unlrn$ are both differentially private, they prevent an adaptive requester from establishing dependencies between records in the curator’s dataset. By leveraging this property, we establish a reduction from adaptive to non-adaptive deletion privacy only assuming that $\Lrn$ and $\Unlrn$ also satisfy $(\epsdp,\del)$-differential privacy.
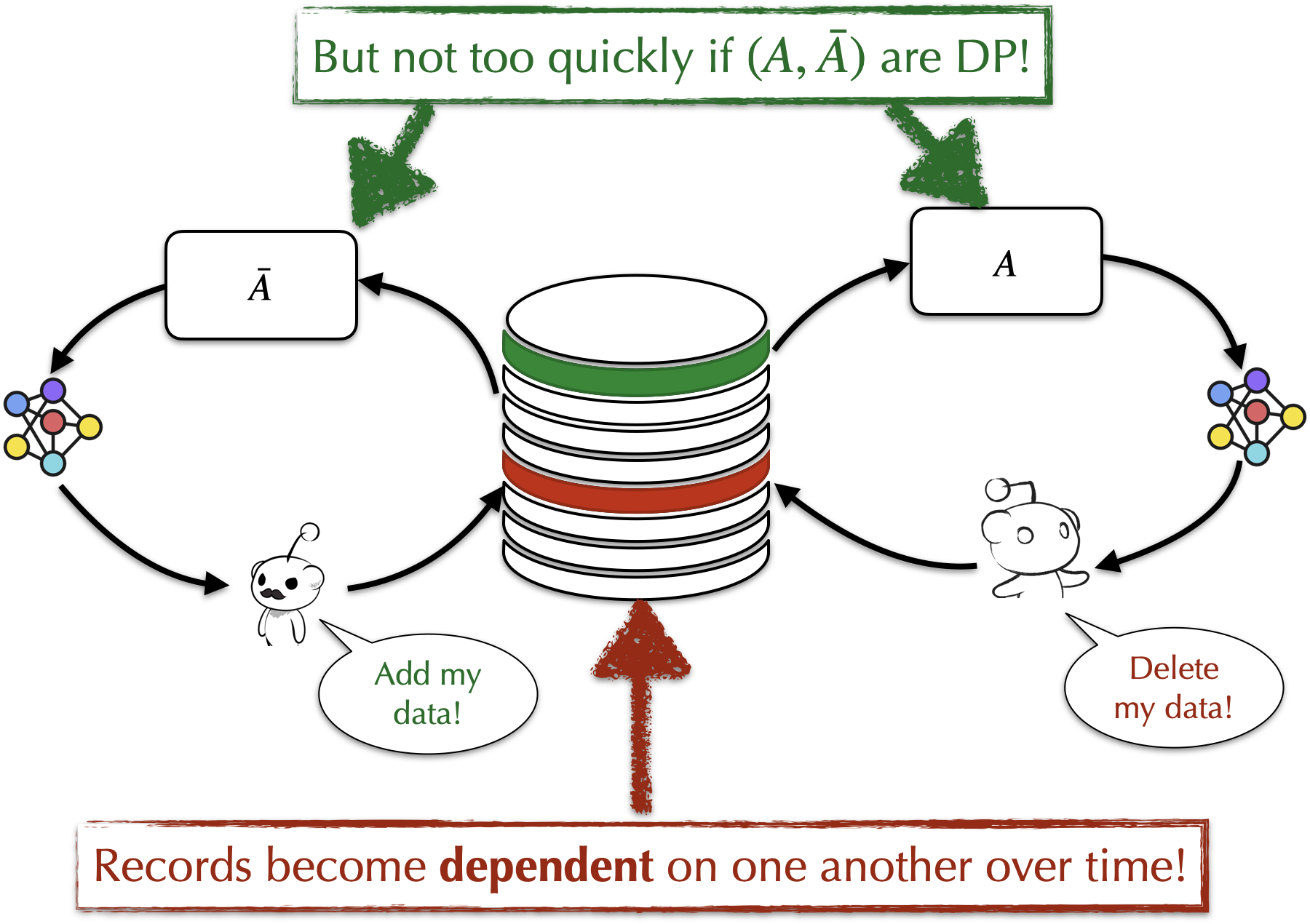
Differential privacy guarantee controls how much inter-dependence an adaptive userbase can introduce between the entries in the dataset over a period of time (or, in our case, number of planned releases $\pubs$).
If an algorithm pair $(\Lrn, \Unlrn)$ satisfies $(\epsdd, \del)$-deletion privacy under all non-adaptive requesters and is also $(\epsdp, \del)$-differentially private, then pair $(\Lrn, \Unlrn)$ also satisfies $(\epsdd', (\pubs + 2)\del)$-deletion privacy under all $\pubs$-adaptive requesters, for
$$
\begin{equation}
\epsdd' = \epsdd + \pubs \epsdp(e^\epsdp - 1) + \epsdp\sqrt{2\pubs \log(1/\del)}.
\end{equation}
$$
When $\epsdd \ll \epsdp$, note that the adaptive deletion privacy guarantee is barely larger than just the DP bound on the total information revealed about the deleted record through the past releases before the deletion request was issued. That is to say, when $\Lrn, \Unlrn$ are differentially private, any deletion privacy guarantee under non-adaptivity gracefully reduces to deletion-privacy under adaptivity with the worst-case degradation being equivalent to the composition of the two bounds.
The great thing about this theorem is that it simplifies the certification process for unlearning algorithms to ensure RTBF compliance. Under the assumption that deletion requests are independent of previous releases, i.e., non-adaptive, showing that the algorithm pair $(\Lrn, \Unlrn)$ is both differentially private and provides deletion privacy is sufficient!
Necessity
In order to guarantee deletion privacy for erased records in the real-world setting, it is necessary for the unlearning algorithm to uphold the privacy of records that remain undeleted. This is because the only effective means of preventing the adaptive world from reacting to the presence of a target record before deletion is by ensuring it never becomes aware of its existence.
Let $\Test: \Y \rightarrow \{0, 1\}$ be a membership inference test for $\Lrn$ to distinguish between neighboring datasets $\D, \D' \in \X^\n$. Similarly, let $\Testb: \Y \rightarrow \{0, 1\}$ be a membership inference test for $\Unlrn$ to distinguish between $\bar\D, \bar\D' \in \X^\n$. If $\text{Adv}(\Test) > \Delta_\Lrn$ and $\text{Adv}(\Testb) > \Delta_\Unlrn$, then the pair $(\Lrn, \Unlrn)$ cannot satisfy $(\eps, \del)$-deletion privacy under all $1$-adaptive requester for any
$$
\begin{equation}
\eps < \log(1 + \Delta_\Lrn \cdot \Delta_\Unlrn - 2\del).
\end{equation}
$$
This theorem shows that without membership privacy, which is ensured by differential privacy, it isn’t possible to provide any non-trivial deletion privacy guarantees under adaptivity. Therefore, for building reliable unlearning algorithms, we should look towards differentially-private algorithms.
Clarifying the need for Differential Privacy.
It is important to emphasize that we are not advocating for unlearning solely through differentially private mechanisms, as they uniformly limit the information content of all records, whether deleted or not. Instead, an effective unlearning algorithm should offer two distinct information retainment bounds: one for the records currently present in the dataset, provided by a differential privacy guarantee, and a significantly smaller bound for the records previously deleted, ensured through a non-adaptive deletion privacy guarantee. Together, these two bounds ensure privacy of deleted records under adaptivity, thanks to this theorem.
Conclusion
In this blog post, we highlighted that existing unlearning certifications in literature are unreliable in real-world scenarios, mainly due to their failure in handling adaptive deletion requests and because they permit unchecked propagation of deleted information through internal states as they only measure indistinguishability for outputs. To mitigate these, we proposed a new deletion guarantee that safeguards the ``Right to be Forgotten’’ in a provably secure way. We also showed the importance of protecting the privacy of existing records in order to ensure privacy of deleted records under adaptive deletions, and established connections between deletion privacy and differential privacy.



.jpeg)