 Exploratory Hypothesis Testing and Analysis
Exploratory Hypothesis Testing and Analysis
Participants:
Andre Suchitra, Haojun Zhang, Wei Zhong Toh,
Mengling Feng, Guimei Liu,
Limsoon Wong.
Click here for a non-technical ppt of the project.
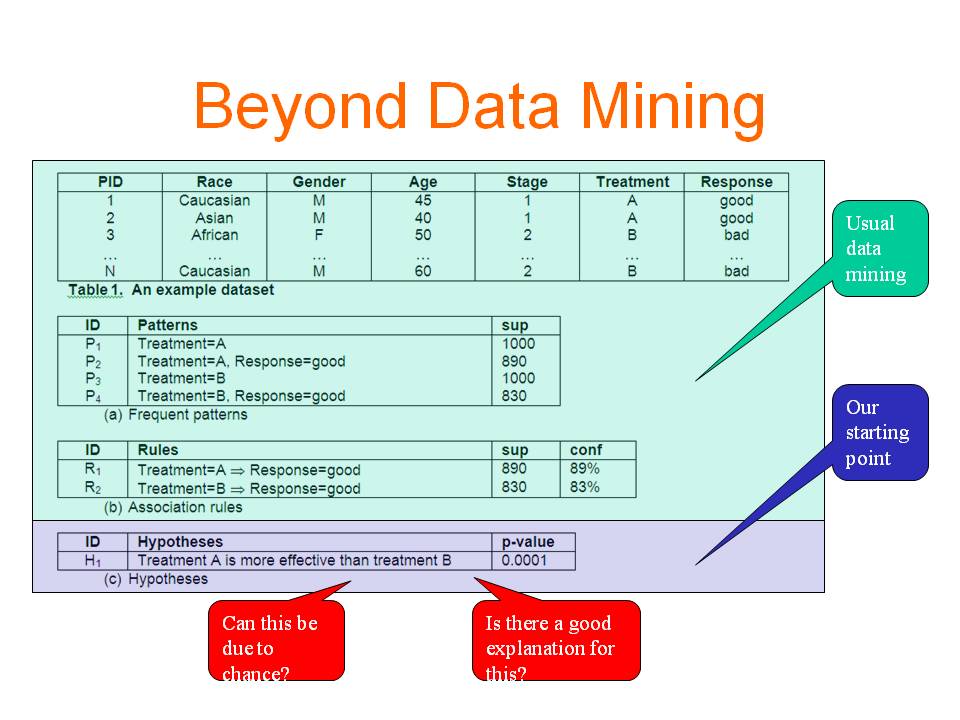
Background
More and more data have been accumulated and stored in digital format
in various applications. These data provide rich sources for making
new discoveries. Data mining has become an important tool to transform
data into knowledge. Finding useful and actionable knowledge is the
main objective of diagnostic data mining. Most existing works tackle
the problem by discovering patterns and rules and then studying their
interestingness; see our past project
on pattern spaces. In this work, we use a different paradigm which
represents the discovered knowledge in the form of hypotheses.
A hypothesis involves a comparison of two or more samples, which is
more or less similar to how human obtain knowledge. Compared with
patterns and rules, hypotheses provide the context in which a piece
of information is interesting, thus hypotheses are more intuitive and
informative than patterns and rules. More importantly, users can take
actions more easily based on what a hypothesis indicates. We further
analyse the discovered significant hypotheses and identify the reasons
behind them so that users not only get to know what is happening but
also have some rough ideas on when or why it is happening.
This new data mining paradigm has the potential to make diagnostic
data mining as successful as predictive data mining in real-life applications.
In the proposed research, we will
(1) formulate the problem and identify the issues that need to be addressed;
(2) develop algorithms to solve the problem;
(3) visualize the discovered knowledge to make the system easy to use;
(4) interact and cooperate with domain experts in the biomedical area or
other areas, and use the developed techniques to solve real-life problems.
Objectives
The main objective of the proposed work is to build a diagnostic data
mining system that can:
- Help users understand their data and gain new insights. The proposed
system enables users to use computational methods to examine large amounts
of data automatically. It summarizes data in a comparative way, which makes
it easier for users to identify interesting information and the context
in which the information is interesting.
- Find actionable knowledge. The proposed system automatically identifies
interesting phenomena from data as well as possible reasons behind the
phenomena, which either suggests possible actions that users can take
or provide clues that users can follow for further investigation. For
example, given a product engineering dataset, the proposed system can
answer the following questions: which product has higher failure rate
than other products? Under which situation, the product is more likely to fail?
- Make it to real-life applications. Most existing diagnostic data
mining systems are not easy to use, and few of them have made it to
real-life applications. The proposed system aims to establish a new
diagnostic data mining paradigm that is easy to use and represents
knowledge in a more intuitive and informative way. This new data mining
paradigm has the potential to make diagnostic data mining as successful
as predictive data mining in real-life applications.
Thus the scope of this project includes:
- Core algorithms. The core algorithms include algorithms
for hypothesis generation and analysis, incremental update of generated
hypotheses and OLAP operations for exploring hypotheses.
- Graphical user interface (GUI). We will design and implement a
GUI for the proposed system, which will support some basic functions
for summarizing and visualizing data, visualization of discovered
knowledge and visualization of OLAP operations.
- Solving real-life problems. We plan to apply the developed techniques
to solve real-life problems. We are particularly interested in solving
problems in the biomedical field since we have good domain expertise;
but we are keen to collaborate on other fields.
Main Results
- Please see this summary poster
for the main technical results of this project.
Selected Publications
- Guimei Liu, Mengling Feng, Yue Wang, Limsoon Wong,
See-Kiong Ng, Tzia Liang Mah, Edmund Jon Deoon Lee.
Towards Exploratory Hypothesis Testing and Analysis.
Proceedings of 27th IEEE International Conference on
Data Engineering (ICDE), pages 745--756,
Hannover, Germany, April 2011.
PDF
- Guimei Liu, Haojun Zhang, Limsoon Wong.
Controlling False Positives in Association Rule Mining.
Proceedings of the VLDB Endowment, 5(2):145--156, October 2011.
PDF,
ARminer Software
- Guimei Liu, Haojun Zhang, Limsoon Wong.
Finding Minimum Representative Pattern Sets.
Proceedings of 18th ACM SIGKDD Conference on Knowledge Discovery
and Data Mining (KDD), pages 51--59, Beijing, China, August 2012.
PDF
- Guimei Liu, Andre Suchitra, Haojun Zhang, Mengling Feng,
See-Kiong Ng, Limsoon Wong.
AssocExplorer: An association rule visualization system for
exploratory data analysis.
Proceedings of 18th ACM SIGKDD Conference on Knowledge Discovery and
Data Mining (KDD), pages 1536--1539, Beijing, China, August 2012.
PDF
- Guimei Liu, Andre Suchitra, Limsoon Wong.
A performance study of three disk-based structures for indexing
and querying frequent itemsets.
Proceedings of the VLDB Endowment, 6(7):505--516, May 2013.
PDF
- Guimei Liu, Haojun Zhang, Limsoon Wong.
A flexible approach to finding representative pattern sets.
IEEE Transactions on Knowledge and Data Engineering,
26(7):1562-1574, July 2014.
- Guimei Liu, Haojun Zhang, Mengling Feng, Limsoon Wong, See-Kiong Ng.
Supporting exploratory hypothesis testing and analysis.
ACM Transactions on Knowledge Discovery from Data,
9(4):Article 31, April 2015.
- Wei Zhong Toh, Kwok Pui Choi, Limsoon Wong.
Redhyte: Towards a self-diagnosing, self-correcting, and helpful
analytic platform.
Proceedings of 8th Asian Conference on
Intelligent Information and Database Systems (ACIIDS), Part II,
pages 3--12, Da Nang, Vietnam, March 2016.
PDF,
Demo,
Github,
Source codes (as of 17/11/2015).
- Wei Zhong Toh, Kwok Pui Choi, Limsoon Wong.
Redhyte: A self-diagnosing, self-correcting, and helpful hypothesis
analysis platform.
Journal of Information and Telecommunication, 1(3):241--258, July 2017.
PDF
- Qian Liu, Jinyan Li, Limsoon Wong, Kotagiri Ramamohanarao.
Efficient mining of pan-correlation patterns from time course data.
Proceedings of 12th International Conference on Advanced Data Mining
and Applications (ADMA),
pages 234--249, Gold Coast, Australia, 12-15 December 2016.
- Limsoon Wong.
Big data and a bewildered lay analyst.
Statistics & Probability Letters, 136:73--77, May 2018.
- Qian Liu, Shameek Ghosh, Jinyan Li, Limsoon Wong, Kotagiri Ramamohanarao.
Discovering pan-correlation patterns from time course data sets
by efficient mining algorithms.
Computing, 100(4):421--437, April 2018.
Dissertations
- QIAN Jiangwen.
A hypothesis visualization and query system.
Final Year Project Report, School of Computing,
National University of Singapore, 2011.
- YAP Ying Hui Priscilla.
Supporting big data analytics in computational biology
and public health.
Final Year Project Report, Faculty of Science,
National University of Singapore, 2013.
- Toh Wei Zhong.
Redhyte: An interactive platform for rapid exploration of data and
hypothesis testing.
Final Year Project Report, Faculty of Science,
National University of Singapore, 2015.
- Emile Bres.
eAnalysis: Easier statistical analysis.
MComp thesis, School of Computing,
National University of Singapore, 2016.
Selected Presentations
- Guimei Liu, Andre Suchitra, Haojun Zhang, Mengling Feng, See-Kiong Ng,
Limsoon Wong.
AssocExplorer: An association rule visualization system for
exploratory data analysis.
Demo at 18th ACM SIGKDD Conference on Knowledge Discovery and
Data Mining (KDD),
Beijing, China, August 2012.
PDF
- Limsoon Wong.
Exploratory hypothesis testing and analysis.
Invited talk at 3rd IPM-NUS Workshop on Computer Science,
Institute for Research in Fundamental Sciences (IPM), Tehran, Iran,
26 February 2013.
- Limsoon Wong.
Large-scale bio and medical data mining.
Invited master class at
UTS AAI Big Data Summer School,
Sydney, Australia, 10 April 2013.
- Limsoon Wong.
Mining testable hypothesis from big data.
Invited panel at SNU Bioinformatics Workshop and Biofestival 2013,
Seoul National University, Seoul, Korea, 24 May 2013.
- Limsoon Wong.
More data is not better.
Talk at 3rd South Asia Workshop on Research Frontiers in Computing,
National University of Singapore, 28 May 2013.
- Limsoon Wong.
Some issues that are often overlooked in big data analytics.
Invited talk at ACM International Conference on Information and
Knowledge Management (CIKM), Shanhai, China, 4 November 2014.
PPT
- Limsoon Wong.
Exciting promises and potential pitfalls of big data in
biology and medicine.
Invited keynote at CAS Shenzhen Institute of Advanced Technology
Research Centre for e-Health Opening Ceremony-cum-Workshop,
Shenzhen, China, 29 November 2014.
PPT
- Limsoon Wong.
Some often-overlooked issues in analytics.
Invited talk at Iran University of Science and Technology,
Tehran, Iran, 8 March 2015.
PPT
- Limsoon Wong.
Some issues that are often overlooked in big-data analytics.
Keynote talk at 7th International Conference on Knowledge and
Systems Engineering (KSE2015),
Ho Chi Minh City, Vietnam, 8-10 October 2015.
- Limsoon Wong.
Some issues that are often overlooked in big data analytics.
Invited talk at University of Malaya Symposium on Data Science,
Kuala Lumpur, Malaysia, 25 October 2016.
PPT
- Limsoon Wong.
A logician-engineer's adventures in data science and analytics.
Invited keynote at International Conference on Intelligent Computing,
Instrumentation & Control Technologies,
Vimal Jyothi Engineering College, Kannur, Kerala, India,
6 - 7 July 2017.
PPT
- Limsoon Wong.
Anna Karenina and the careless null hypothesis in omics data analysis.
Invited talk at IPM-Shanghai University Workshop on Systems Biology,
Institute for Research in Fundamental Sciences, Tehran, Iran,
2 - 3 August 2017.
- Limsoon Wong.
Some simple tactics for deriving a deeper analysis of data.
Keynote at 4th International Conference on
Computational Science and Technology,
Kuala Lumpur, Malaysia, 29 - 30 November 2017.
PPT
Acknowledgements
This project is supported in part by
a A*STAR PSF grant (SERC 102 101 0030, 1/8/2010 - 31/7/2013) and
a MOE T2 grant (MOE2012-T2-1-061, 12/10/2012 - 11/10/2015).
Last updated: 25/6/2018, Limsoon Wong.