Waterfall @ EMNLP 2024
Scalable Framework for Robust Text Watermarking and Provenance for LLMs
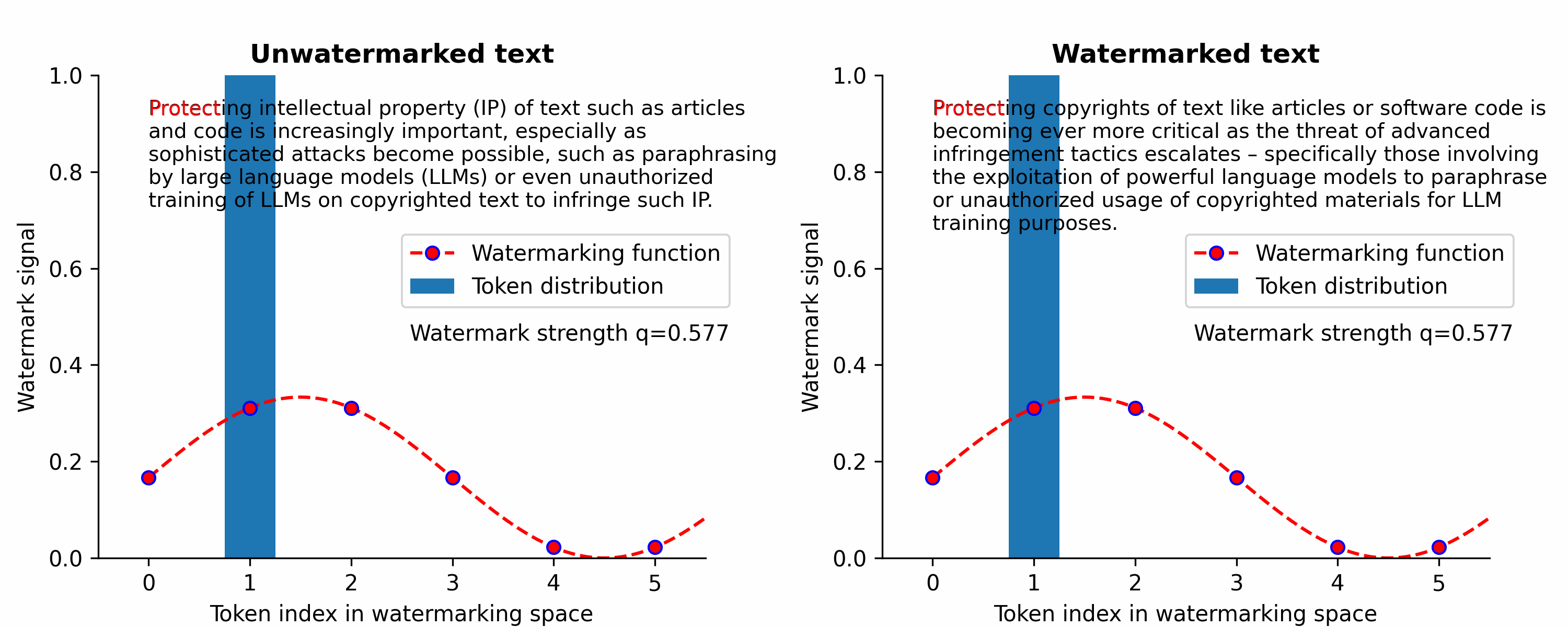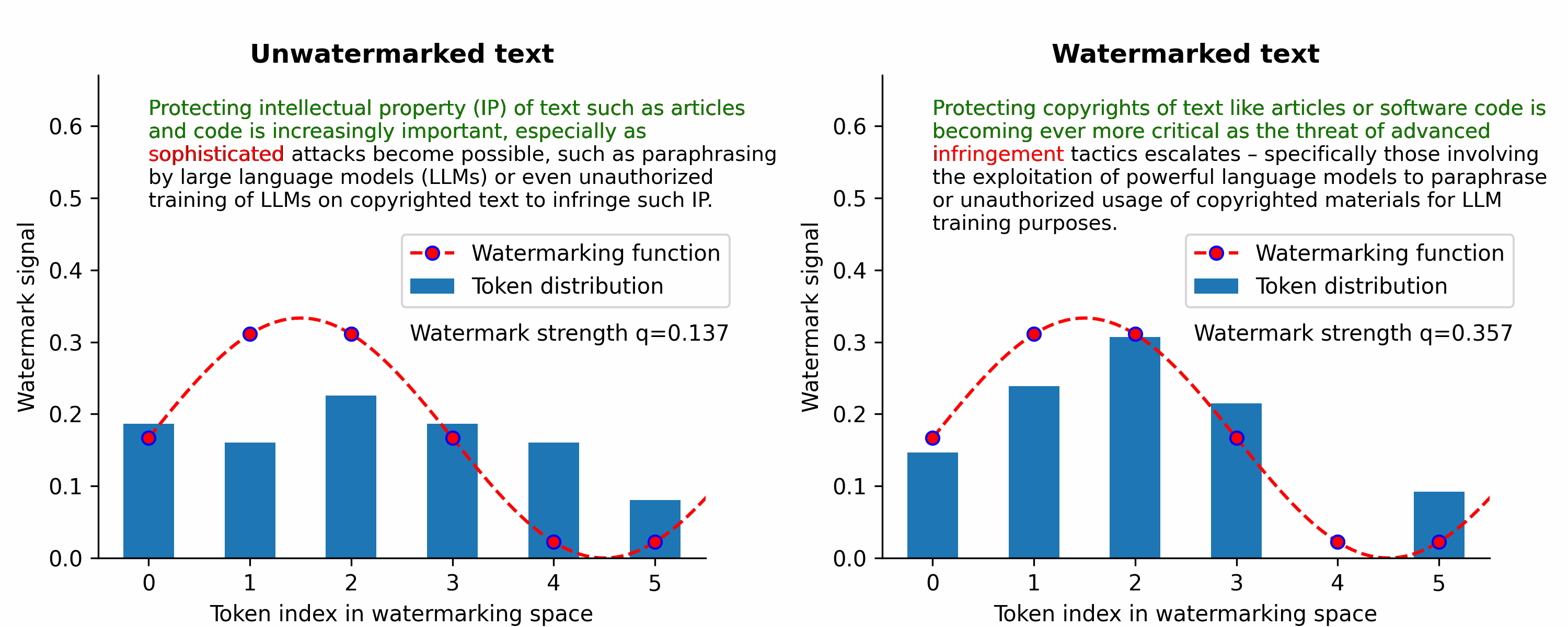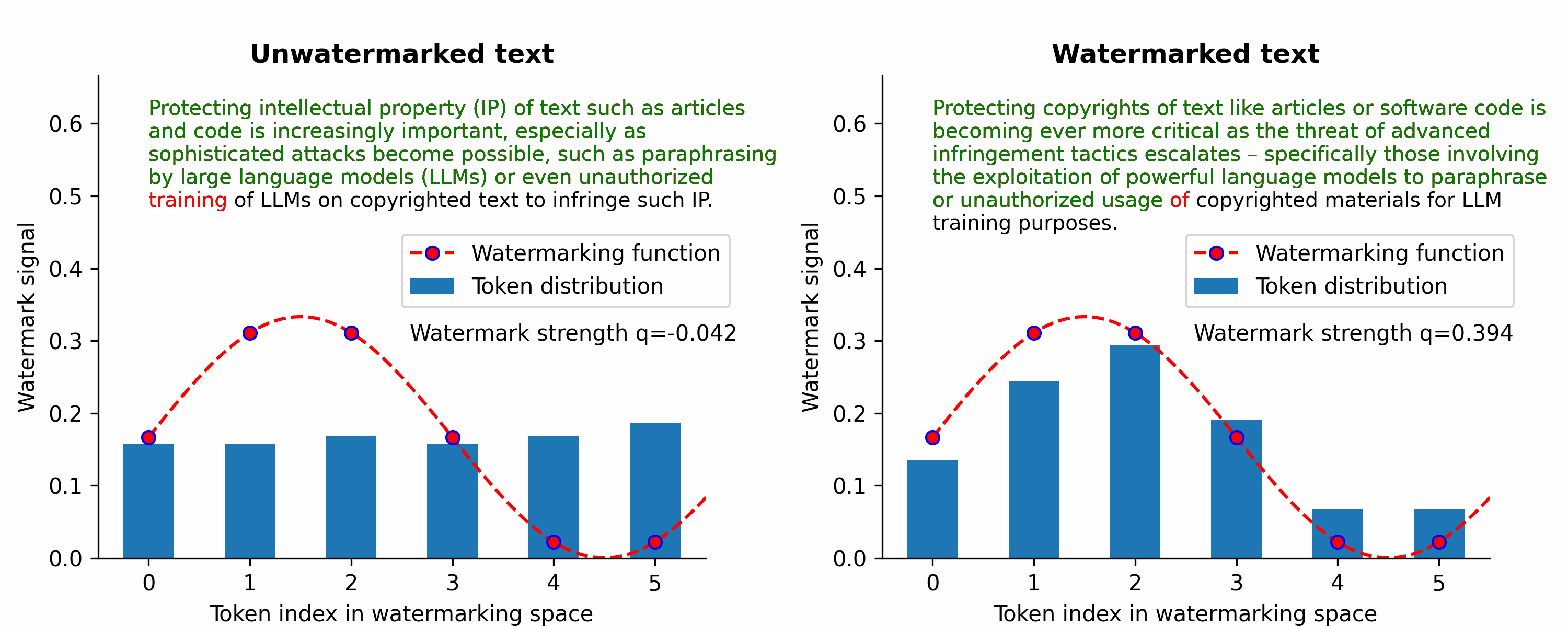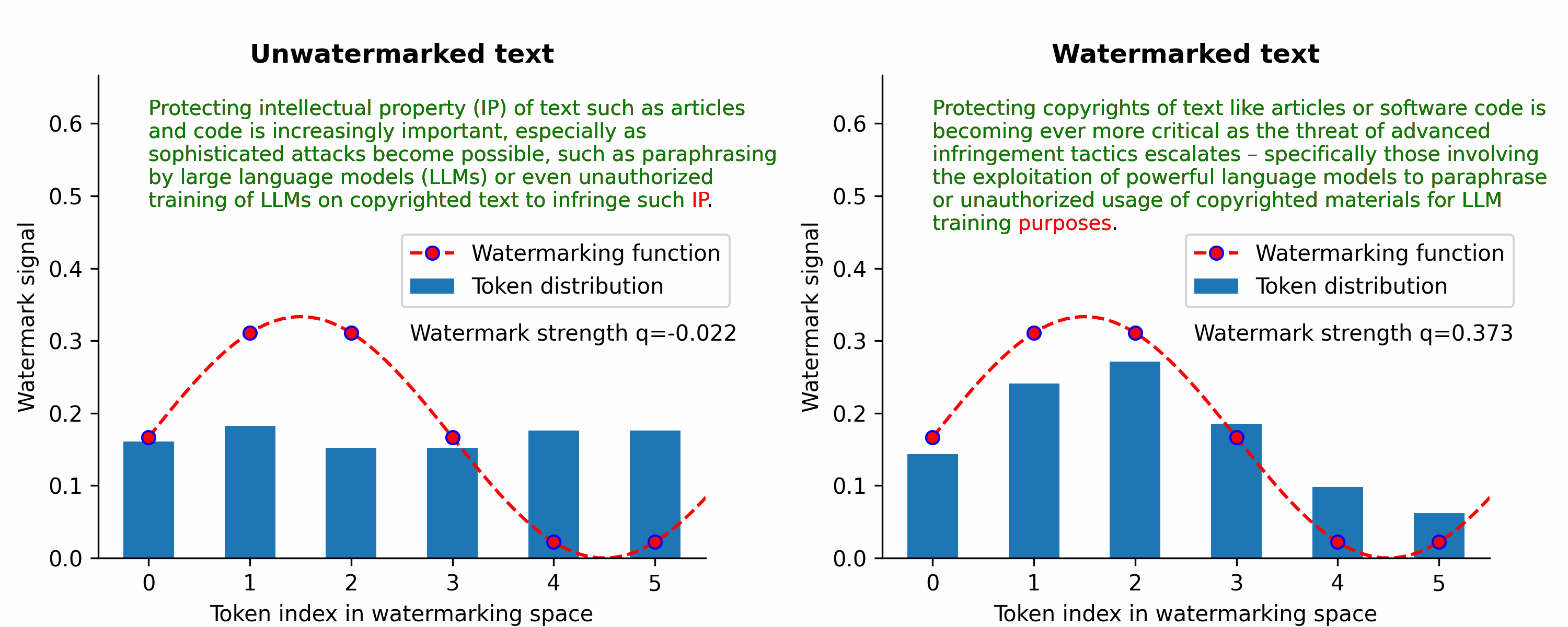
Waterfall is the first training-free framework for text watermarking & LLM data provenance that is scalable, robust to LLM attacks, and applicable to multiple text types (e.g., articles, code).
Deepmind’s recent Nature paper on watermarking LLM outputs highlights how watermarking methods are increasingly important in the era of LLMs.

In fact, we’ve worked on a text watermarking framework since last year (presented at ICML 2024 Workshops on Foundation Models in the Wild & Generative AI and Law and appearing in EMNLP 2024 (main conference) soon) that shares similarities but addresses a further challenge of scaling up to a large number of watermarked IDs and possibly concurrent watermarks in the same text.

Instead of LLM-centric watermarking, we’ve focused on the broader problem of text watermarking (including watermarking of text data that may be used to train LLMs without authorization) to protect IP/copyrights of text.
Deepmind’s paper highlighted limitations of existing LLM watermarking works in handling open-source models.
Instead, our Waterfall framework can watermark LLM training data to create persistent detectable watermarks in LLM outputs without intervening during token generation. So, our Waterfall framework can be applied to even decentralized open-source models. Furthermore, our watermark verification method doesn't require the LLM in question — just the LLM text output and a CPU is sufficient for verification in a matter of milliseconds!
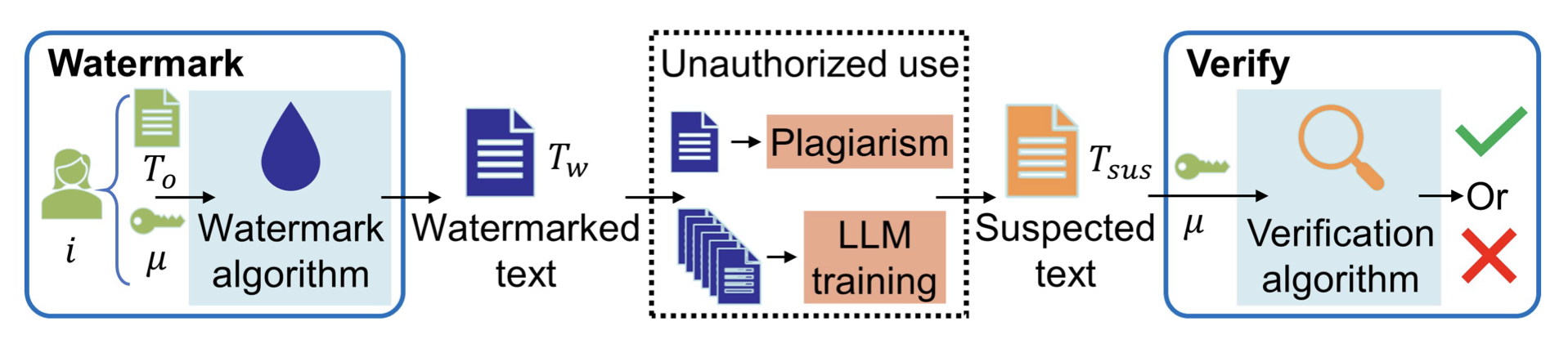
We hope that more will explore and build on our Waterfall framework, which allows content creators to watermark their works once before publishing and be able to detect the watermark in the future for both direct plagiarism & unauthorised LLM training.
