Release 3 (8.1.7)
Part Number A85455-01
Library |
Product |
Contents |
Index |
| Oracle8i Documentation Addendum Release 3 (8.1.7) Part Number A85455-01 |
|
![]()
![]()
This chapter introduces the Character Set Scanner Utility, a National Language Support utility in release 8.1.7 for checking data before migrating character sets. The topics in this chapter include:
Choosing the appropriate database character set for your database is an important decision and requires taking into account many factors. Some of these factors are:
A related topic is choosing a new character set for an existing database, which is called migrating character sets. Migrating from one database character set to another involves additional considerations beyond those of simply choosing a character set. In particular, it is a complex planning process with the goal of minimizing the possibility of losing data because of data truncation and character set conversions during the migration.
|
See Also:
Oracle8i National Language Support Guide for further details regarding choosing character sets |
The sizes of character data types CHAR and VARCHAR2 are specified in bytes, not characters. Hence, the specification CHAR(20) in a table definition allows 20 bytes for storing character data. This is acceptable when the database character set uses a single-byte character encoding scheme because the number of characters will be equivalent to the number of bytes. If the database character set uses a multi-byte character encoding scheme, however, there is no such correspondence. That is, the number of bytes no longer equals the number of characters because a character can consist of one or more bytes. This situation can cause problems.
During migration to a new character set, it is important to verify the column widths of existing CHAR and VARCHAR columns because they might need to be extended to support encoding that requires multi-byte storage. If the character set width differs during the import process, truncation of data can occur if conversion causes expansion of data. Figure 3-1 shows a typical case of data expansion with single-byte characters becoming multibyte. In it, ä (a with an umlaut) is a single-byte character in WE8MSWIN1252, but it becomes a double-byte character in UTF8. Also, the Euro symbol goes from one byte to three bytes in this conversion.
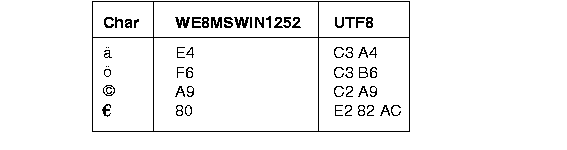
The maximums for CHAR and VARCHAR2 data types are 2000 and 4000 bytes respectively. If the data columns in the new destination character set require more than 2000 and 4000 bytes, you will need to change your schema.
Here are some known restrictions caused by data truncation.
CHAR data contains characters that will be expanded after migration to a new character set, space padding will not be removed during database export by default. This means that these rows will be rejected upon import into the database with the new character set. The workaround is to set the initialization parameter BLANK_TRIMMING to TRUE prior to the import.
When migrating to a new database character set, the Export and Import utilities can handle character set conversions from the original database character set to the new database character set. However, character set conversions can sometimes cause data loss or data corruption. For example, if you are migrating from character set A to character set B, the destination character set B should be a superset of character set A. Characters that are not available in character set B will be converted to replacement characters, which are usually specified as '?' or '¿' or other linguistically-related characters. For example, ä (a with an umlaut) will be converted to 'a'. Replacement characters are defined by the target character set. Figure 3-2 shows a sample conversion where the copyright and Euro symbols are converted to '?' and ä to 'a'.
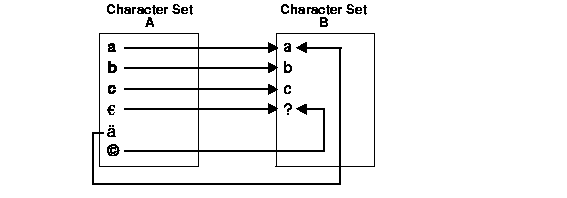
To reduce the risk of losing data, consider selecting a destination character set with similar character repertoires if possible. Migrating to Unicode can be an attractive option because UTF8 contains characters from most legacy character sets.
Another scenario that can cause the loss of data is migrating a database containing data of a different character set from that of the database character set. Users can insert data into the database from another character set if the client NLS_LANG character set setting is the same as the database character set. When these settings are the same, Oracle assumes that the data being sent or received is of the same character set, so no validations or conversions are performed.
This can lead to two possible data inconsistency problems. One is when a database contains data from another character set but the same codepoints exist in both character sets. For example, if the database character set is WE8ISO8859P1 and the end user Chinese Windows NT client's NLS_LANG setting is SIMPLIFIED CHINESE_CHINA.WE8ISO8859P1, then all multi-byte Chinese data (from the ZHS16GBK character set) is stored as multiples of single-byte WE8ISO8859P1 data. This means that Oracle will treat these characters as single-byte WE8ISO8859P1 characters, hence all SQL string manipulation functions such as SUBSTR or LENGTH will be based on bytes rather than characters. All bytes constituting ZHS16GBK data are legal WE8ISO8859P1 codes. If such a database is migrated to another character set, for example, UTF8, character codes will be converted as if they were in WE8ISO8859P1. This way, each of the two bytes of a ZHS16GBK character will be converted separately, yielding garbage values in UTF8. Figure 3-3 shows an example of this incorrect character set replacement.
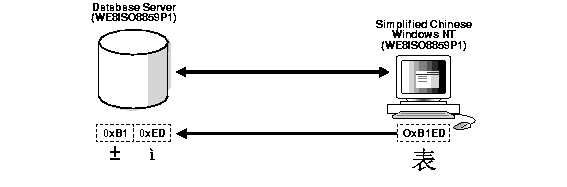
The second possibility is having data from mixed character sets inside the database. For example, if the data character set is WE8MSWIN1252, and two separate Windows clients using German and Greek are both using the NLS_LANG character set setting as WE8MSWIN1252, then the database will contain a mixture of German and Greek characters. Figure 3-4 shows how different clients can use different character sets in the same database.
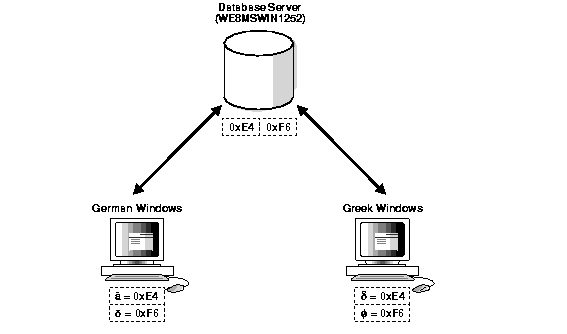
For database character set migration to be successful, both of these cases require manual intervention because Oracle cannot determine the character sets of the data being stored.
Database character set migration has two distinct stages:
Before you actually migrate your character set, you need to identify areas of possible database character set conversions and truncation of data. This step is called data scanning.
Data scanning identifies the amount of effort required to migrate data into the new character encoding scheme prior to the change of the database character set. Some examples of what are found during a data scan are the number of schema objects where the column widths need to be expanded and the extent of the data that does not exist in the target repertoire. This information will assist in determining the best approach for the conversion of the database character set.
There are generally three approaches in migrating data from one database character set to another, provided the database does not contain any of the inconsistencies described in "Character Set Conversions". A description of methods to migrate databases with such inconsistencies is out of the scope of this document. For more information, contact Oracle Consulting Services for assistance.
In most cases, a full export or import is recommended to properly convert all data to a new character set. It is important to be aware of data truncation issues because character data type columns might need to be extended prior to import to handle the increase in size required. Existing PL/SQL code should be reviewed to ensure all byte-based SQL functions such as LENGTHB, SUBSTRB, and INSTRB, and PL/SQL CHAR and VARCHAR2 declarations are still valid. However, if, and only if, the new character set is a strict superset of the current character set, you can use the ALTER DATABASE CHARACTER SET statement to expedite migration to a new database character set. The target character set is a strict superset if, and only if, each and every codepoint in the source character set is available in the target character set with the same corresponding codepoint value. For instance, because US7ASCII is a strict subset of UTF8, then an ALTER DATABASE CHARACTER SET statement can be used to upgrade the database character set from US7ASCII to UTF8. Refer to "Subsets and Supersets" for a listing of all superset character sets in release 8.1.7.
The syntax is:
ALTER DATABASE [<db_name>] CHARACTER SET <new_character_set>; ALTER DATABASE [<db_name>] NATIONAL CHARACTER SET <new_NCHAR_character_set>;
The database name is optional. The character set name should be specified without quotes. For example:
ALTER DATABASE CHARACTER SET UTF8;
To change the database character set, perform the following step:
SHUTDOWN IMMEDIATE; -- or NORMAL <do a full backup> STARTUP MOUNT; ALTER SYSTEM ENABLE RESTRICTED SESSION; ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0; ALTER SYSTEM SET IAQ_TM_PROCESSES=0; ALTER DATABASE OPEN; ALTER DATABASE CHARACTER SET <new_character_set_name>; SHUTDOWN IMMEDIATE; -- or NORMAL STARTUP;
To change the national character set, replace the ALTER DATABASE CHARACTER SET statement with the ALTER DATABASE NATIONAL CHARACTER SET statement. You can issue both statements together if desired.
|
See Also:
Oracle8i National Language Support Guide and Oracle8i SQL Reference for the syntax of the |
When using Oracle Parallel Server (OPS), make sure no other Oracle background processes are running, with the exception of the one session through which a user is connected before attempting to issue the ALTER DATABASE CHARACTER SET statement. Use the following SQL statement to verify your environment:
SELECT SID, SERIAL#, PROGRAM FROM V$SESSION;
Setting the initialization parameter PARALLEL_SERVER to FALSE allows the character set change to go through. This is required in an OPS environment, as an exclusive startup is not sufficient.
The last approach is to perform an ALTER DATABASE CHARACTER SET statement followed by selective imports. This method is best suited for when the distributions of convertible data are known and they are stored within a small number of tables. A full export and import will be too expensive in this scenario. For example, a 100GB database with over 300 tables but only 3 tables requires character set conversions and the rest of the data is of the same encoding as the destination character set. The 3 tables can be exported and imported back to the new database after issuing the ALTER DATABASE CHARACTER SET statement.
Incorrect data conversion can lead to the corruption of your data, so a full backup of your database must be performed before attempting to migrate your data to a new character set.
The Character Set Scanner provides an assessment of the feasibility and potential issues in migrating an Oracle database to a new database character set. The Scanner checks all character data in the database and tests for the effects and problems of changing the character set encoding. At the end of the scan, it generates a summary report of the database scan. This report provides estimates of the amount of work required to convert the database to a new character set.
Based on the information in the summary report, you will be able to decide on the most appropriate method to migrate the database's character set. The methods are:
ALTER DATABASE CHARACTER SET statement
ALTER DATABASE CHARACTER SET with selective Export and Import
The Scanner reads the character data and tests for the following conditions on each data cell:
The Scanner reads and tests for data in CHAR, VARCHAR2, LONG, CLOB, NCHAR, NVARCHAR2, and NCLOB columns only. The Scanner does not perform post-conversion column size testing for LONG, CLOB, and NCLOB columns.
To use the Scanner, you must have DBA privileges on the Oracle database.
All the character-based data in CHAR, VARCHAR2, LONG, and CLOB columns is stored in the same character set, which is the database character set specified with the CREATE DATABASE statement when the database was first created. However, in some configurations, it is possible to store data in a different character set from the database character set either intentionally or unintentionally. This happens most often when the NLS_LANG character set is the same as the database character set, because in such cases Oracle sends and receives data as is, without any conversion or validation. But it can also happen if one of the two character sets is a superset of the other, in which case many of the codes appear as if they were not converted. For example, if NLS_LANG is set to WE8ISO8859P1 and the database character set is WE8MSWIN1252, all codes except the range 128-159 are preserved through the client/server conversion.
Although a database that contains data not in its database character set cannot be converted to another character set by the three methods described in "What is the Character Set Scanner Utility?", you can still use the Scanner in the way described below to test the effect of the conversion that would take place if the data was in the database character set.
If a database contains data from more than one character set, the Scanner cannot accurately test the effects of changing the database character set on the database because it cannot differentiate character sets properly. If the data can be divided into two separate tables, one for each language, then the Scanner can perform two single table scans to verify the validity of the data.
For each scan, a different value of the FROMCHAR parameter can be used to tell the Scanner to treat all CHAR, VARCHAR2, LONG, and CLOB columns in the table as if they were in the specified character set.
If a database contains data not in the database character set, but still in only one character set, the Scanner can perform a full database scan. Use the FROMCHAR parameter to tell the Scanner what character set the data is in.
The Character Set Scanner provides three modes of database scan:
The Scanner reads and verifies the character data of all tables belonging to all users in the database including the data dictionary (SYS user), and it reports on the effects of the simulated migration to the new database character set. It scans all schema objects including stored packages, procedures and functions, and object names.
To understand the feasibility of migration to a new database character set, you need to perform a full database scan.
The Scanner reads and verifies character data of all tables belonging to the specified user and reports on the effects of changing the character set on them.
The Scanner does not test for table definitions such as table names and column names. To see the effects on the schema definitions, you need to perform a full database scan.
The Scanner reads and verifies the character data of the specified table, and reports the effects on changing the character set of them.
The Scanner does not test for table definitions such as table name and column name. To see the effects on the schema definitions, you need to perform a full database scan.
This section describes how to use the Scanner, including the steps you need to perform before scanning and the procedures on how to invoke the Scanner. The topics discussed are:
To use the Scanner, you must run the script CSMINST.SQL on the database that you plan to scan. CSMINST.SQL needs to be run only once, so it is not necessary to run it each time you scan the database. The script performs the following tasks to prepare the database for scanning:
CSMIG
CSMIG
CSMIG
CSMIG
CSMIG
The SYSTEM tablespace is assigned to CSMIG by default, so you need to ensure there is sufficient storage space available in the SYSTEM tablespace before scanning the database. The amount of space required depends on the type of scan and the nature of the data in the database. For information on storage considerations, refer to "Storage and Performance Considerations in the Scanner".
You can modify the default tablespace for CSMIG by editing the script CSMINST.SQL. Modify the following statement in CSMINST.SQL to assign your preferred tablespace to CSMIG as follows:
SQL> ALTER USER CSMIG default tablespace PREFERRED_TABLESPACE;
Then run CSMINST.SQL using this command string:
% cd $ORACLE_HOME/rdbms/admin % sqlplus SQL> CONNECT system/manager SQL> START csminst.sql
The Scanner is certified with Oracle databases on any platforms running under the same release except you cannot mix ASCII- and EBCDIC-based platforms. For example, the release 8.1.7 versions of the Scanner on any ASCII-based client platforms are certified to run with any release 8.1.7 Oracle databases on any ASCII-based platforms, while EBCDIC-based clients are certified to run with any release 8.1.7 Oracle database on EBCDIC platforms.
Oracle recommends you run the Scanner tool in the same Oracle Home as the database when possible.
You can invoke the Scanner by one of three methods:
PARFILE is a file containing the Scanner parameters you typically use.
csscan system/manager full=y tochar=utf8 array=10240 process=3
csscan system/manager
In an interactive session, the Scanner prompts you for only the following parameters:
If you want to specify parameters that are not listed above, you need to invoke the Scanner using either the parameter file or the command line.
The Scanner provides online help. Enter csscan help=y on the command line to invoke the help screen.
Character Set Scanner: Release 8.1.7.0.0 - Production (c) Copyright 2000 Oracle Corporation. All rights reserved. You can let Scanner prompt you for parameters by entering the CSSCAN command followed by your username/password: Example: CSSCAN SYSTEM/MANAGER Or, you can control how Scanner runs by entering the CSSCAN command followed by various parameters. To specify parameters, you use keywords: Example: CSSCAN SYSTEM/MANAGER FULL=y TOCHAR=utf8 ARRAY=102400 PROCESS=3 Keyword Default Prompt Description ---------- ------- ------ ------------------------------------------------- USERID yes username/password FULL N yes scan entire database USER yes user name of the table to scan TABLE yes table name to scan TOCHAR yes new database character set name FROMCHAR current database character set name TONCHAR new NCHAR character set name FROMNCHAR current NCHAR character set name ARRAY 10240 yes size of array fetch buffer PROCESS 1 yes number of scan process MAXBLOCKS split table if larger than MAXBLOCKS CAPTURE N capture convertible data SUPPRESS suppress error log by N per table FEEDBACK feedback progress every N rows BOUNDARIES list of column size boundaries for summary report LASTRPT N generate report of the last database scan LOG scan base name of log files PARFILE parameter file name HELP N show help screen (this screen) ---------- ------- ------ ------------------------------------------------- Scanner terminated successfully.
The parameter file allows you to specify Scanner parameters in a file where they can be easily modified or reused. Create a parameter file using any flat file text editor. The command line option PARFILE=filename tells the Scanner to read the parameters from a specified file rather than from the command line. For example:
csscan parfile=filename
or
csscan username/password parfile=filename
The syntax for parameter file specifications is one of the following:
KEYWORD=value KEYWORD=(value1, value2, ...)
The following is an example of a parameter file:
USERID=system/manager USER=SCOTT # scan SCOTT's tables TOCHAR=utf8 ARRAY=40960 PROCESS=2 # use two concurrent scan processes FEEDBACK=1000
You can add comments to the parameter file by preceding them with the pound (#) sign. All characters to the right of the pound sign are ignored.
This section describes each of the Scanner parameters.
The formula below gives an approximation of number of rows fetched at a time:
(rows in array) = (ARRAY buffer size) / (sum of the CHAR and VARCHAR2column sizes of a given table)
If the summation of CHAR and VARCHAR2 column sizes exceeds the array buffer size, the Scanner fetches only one row at a time. Tables with LONG, CLOB, or NCLOB columns are fetched only one row at a time.
This parameter affects the duration of a database scan. In general, the larger the size of the array buffer, the shorter the duration time. Each scan process will allocate the specified size of array buffer.
For example, if you specify a BOUNDARIES value of (10, 100, 1000), the application data conversion summary report will produce a breakdown of the CHAR data into the following groups by their column length, CHAR(1..10), CHAR(11..100) and CHAR(101..1000), likewise for the VARCHAR2, NCHAR, and NVARCHAR2 datatypes.
For example, if you specify FEEDBACK=1000, the Scanner displays a dot for every 1000 rows scanned. The FEEDBACK value applies to all tables being scanned, so it cannot be set on a per-table basis.
Use this parameter to override the default database character set definition for CHAR, VARCHAR2, LONG, and CLOB data in the database.
Use this parameter to override the default database character set definition for NCHAR, NVARCHAR2, and NCLOB data in the database.
For more information on full database scans, refer to "Scan Modes in the Scanner".
For more information, see "Getting Online Help".
If LASTRPT=Y is specified, the Scanner does not scan the database, but creates the report files using the information left by the previous database scan session instead.
If LASTRPT=Y is specified, only the USERID, BOUNDARIES, and LOG parameters take effect.
By default, the Scanner generates the three text files, scan.txt, scan.err, and scan.out in the current directory.
For example, if the MAXBLOCKS parameter is set to 1000, then any tables that are greater than 1000 blocks in size will be divided into n chunks, where n=CEIL(table block size/1000).
Dividing large tables into smaller pieces will be beneficial only when the number of processes set with PROCESS is greater than 1. If the MAXBLOCKS parameter is not set, the Scanner attempts to split up large tables based on the its own optimization rules.
For more information on using a parameter file, see "The Parameter File".
The Scanner inserts individual exceptional record information into the CSM$ERRORS table when an exception is found in a data cell. The table grows depending on the number of exceptions reported.
This parameter is used to suppress the logging of individual exception information after a specified number of exceptions are inserted per table. For example, if SUPPRESS is set to 100, then the Scanner records a maximum of 100 exception records per table.
For more information, see "Storage Considerations".
When specified, Scanner scans the specified table only. For example, the command below scans an emp table that belongs to the user scott:
csscan system/manager USER=SCOTT TABLE=EMP ...
If you do not specify a value for TONCHAR, the Scanner does not scan NCHAR, NVARCHAR2, and NCLOB data.
If the parameter USER is specified, the Scanner scans all tables belonging to the user. If TABLE is specified, the Scanner scans only the table specified by TABLE that belongs to the user. For example, the following statement scans all tables belonging to the user scott:
csscan system/manager USER=scott ...
The following examples are all valid:
username/password username/password@connect_string username username@connect_string
The following examples show you how to use the command line and parameter file methods to use Full Database, User Tables, and Single Table scan modes.
The following example shows how to scan the full database to see the effects on migrating it to UTF8. This example assumes the current database character set is WE8ISO8859P1 (or anything other than UTF8).
% csscan system/manager parfile=param.txt
The param.txt file contains the following information:
full=y tochar=utf8 array=40960 process=4
% csscan system/manager full=y tochar=utf8 array=40960 process=4 Scanner Messages Database Scanner: Release 8.1.7.0.0 - Production (c) Copyright 2000 Oracle Corporation. All rights reserved. Connected to: Oracle8 Enterprise Edition Release 8.1.7.0.0 - Production With the Objects option PL/SQL Release 8.1.7.0.0 - Production Enumerating tables to scan... . process 1 scanning SYSTEM.REPCAT$_RESOLUTION . process 1 scanning SYS.AQ$_MESSAGE_TYPES . process 1 scanning SYS.ARGUMENT$ . process 2 scanning SYS.AUD$ . process 3 scanning SYS.ATTRIBUTE$ . process 4 scanning SYS.ATTRCOL$ . process 2 scanning SYS.AUDIT_ACTIONS . process 2 scanning SYS.BOOTSTRAP$ . process 2 scanning SYS.CCOL$ . process 2 scanning SYS.CDEF$ : : . process 3 scanning SYSTEM.REPCAT$_REPOBJECT . process 1 scanning SYSTEM.REPCAT$_REPPROP . process 2 scanning SYSTEM.REPCAT$_REPSCHEMA . process 3 scanning MDSYS.MD$DIM . process 1 scanning MDSYS.MD$DICTVER . process 2 scanning MDSYS.MD$EXC . process 3 scanning MDSYS.MD$LER . process 1 scanning MDSYS.MD$PTAB . process 2 scanning MDSYS.MD$PTS . process 3 scanning MDSYS.MD$TAB Creating Database Scan Summary Report... Creating Individual Exception Report... Scanner terminated successfully.
The following example shows how to scan the user tables to see the effects on migrating them to UTF8. This example assumes the current database character set is US7ASCII, but the actual data stored is in Western European WE8MSWIN1252 encoding.
% csscan system/manager parfile=param.txt
The param.txt file contains the following information:
user=scott fromchar=we8mswin1252 tochar=utf8 array=40960 process=1
% csscan system/manager user=scott fromchar=we8mswin1252 tochar=utf8 array=40960 process=1
Database Scanner: Release 8.1.7.0.0 - Production (c) Copyright 2000 Oracle Corporation. All rights reserved. Connected to: Oracle8 Enterprise Edition Release 8.1.7.0.0 - Production With the Objects option PL/SQL Release 8.1.7.0.0 - Production Enumerating tables to scan... . process 1 scanning SCOTT.BONUS . process 1 scanning SCOTT.DEPT . process 1 scanning SCOTT.EMP Creating Database Scan Summary Report... Creating Individual Exception Report... Scanner terminated successfully.
The following example shows how to scan a single table to see the effects on migrating it to WE8MSWIN1252. This example assumes the current database character set is in US7ASCII.
% csscan system/manager parfile=param.txt
The param.txt file contains the following information:
user=scott table=emp tochar=we8mswin1252 array=40960 process=1 supress=100
% csscan system/manager user=scott table=emp tochar=we8mswin1252 array=40960 process=1 supress=100 Scanner Messages Database Scanner: Release 8.1.7.0.0 - Production (c) Copyright 1999 Oracle Corporation. All rights reserved. Connected to: Oracle8 Enterprise Edition Release 8.1.7.0.0 - Production With the Objects option PL/SQL Release 8.1.7.0.0 - Production . process 1 scanning SCOTT.EMP Creating Database Scan Summary Report... Creating Individual Exception Report... Scanner terminated successfully.
The Scanner generates two reports per scan:
A Database Scan Summary Report consists of the following sections. The information available for each section depends on the type of scans and the parameters you select.
This section describes the parameters selected and the type of scan you chose. The following is an example:
Parameter Value ---------------------------------------- ------------------------------ Scan type Full database Scan CHAR data? YES Current database character set WE8ISO8859P1 New database character set UTF8 Scan NCHAR data? NO Array fetch buffer size 102400 Number of processes 4 ---------------------------------------- ------------------------------
This section describes the current database size. The following is an example:
TABLESPACE Total(MB) Used(MB) Free(MB) ----------------------------- --------------- --------------- --------------- APPS_DATA 1,340.000 1,331.070 8.926 CTX_DATA 30.000 3.145 26.852 INDEX_DATA 140.000 132.559 7.438 RBS_DATA 310.000 300.434 9.563 SYSTEM_DATA 150.000 144.969 5.027 TEMP_DATA 160.000 159.996 TOOLS_DATA 35.000 22.148 12.848 USERS_DATA 220.000 142.195 77.801 ----------------------------- --------------- --------------- --------------- Total 2,385.000 2,073.742 311.227
This indicates the feasibility of the database character set migration. There are two basic criteria that determine the feasibility of the character set migration of the database. One is the condition of the data dictionary and the other is the condition of the application data.
The Scan Summary section consists of two status lines. Depending on the scan mode and the result returned, the following statuses are printed:
For the data dictionary
For application data
When all data remains the same in the new character set, it means that the data encoding of the original character set is identical to the target character set. In this case, the character set can be migrated using the ALTER DATABASE CHARACTER SET statement.
If all the data is convertible to the new character set, it means that the data can be safely migrated using the Export and Import utilities. However, the migrated data may or may not have the same encoding as the original character set.
The following is sample output:
All character type data in the data dictionary remains the same in the new character set All character type application data remains the same in the new character set
This section contains the statistics on the conversion summary of the data dictionary. The granularity of this report is per datatype. The following statuses are available:
If the numbers in both the Convertible and Exceptional columns are zero, it means that all the data in the data dictionary will remain the same in the new character set.
If the numbers in the Exceptional column are zero and some numbers in the Convertible columns are non-zero, it means all data in the data dictionary is convertible to the new character set. During import, the relevant data will be converted.
If the numbers in the Exceptional column are non-zero, it means there is data in the data dictionary that is not convertible. Therefore, it is not feasible to migrate the current database to the new character because the export and import process cannot convert the data into the new character set. For example, you might have a table name with invalid characters or a PL/SQL procedure where a comment line includes data that can not be mapped to the new character set. These changes to schema objects must be corrected manually prior to migration to a new character set.
This information is available only when a full database scan is performed. The following is an example:
Datatype Changeless Convertible Exceptional Total --------- ---------------- ---------------- ---------------- ---------------- VARCHAR2 971,300 1 0 971,301 CHAR 7 0 0 7 LONG 60,325 0 0 60,325 CLOB --------- ---------------- ---------------- ---------------- ---------------- Total 1,031,632 1 0 1,031,633
This section contains the statistics on conversion summary of the application data. The granularity of this report is per datatype. The following statuses are available:
The following is sample output:
Datatype Changeless Convertible Exceptional Total ---------- ---------------- ---------------- ---------------- ---------------- VARCHAR2 23,213,745 1,324 0 23,215,069 CHAR 423,430 0 0 423,430 LONG 8,624 33 0 8,657 CLOB 58,839 11,114 28 69,981 ---------- ---------------- ---------------- ---------------- ---------------- Total 23,704,638 12,471 28 23,717,137
This section contains the conversion summary of the CHAR and VARCHAR2 application data. The granularity of this report is per column size boundaries specified by the BOUNDARIES parameter. The following status is available for each datatype and each boundary:
The granularity of this report is per datatype. The following statuses are available:
This information is available only when the BOUNDARIES parameter is specified.
The following is sample output:
Datatype Changeless Convertible Exceptional Total ------------------- ------------- ------------- --------------- ---------------- VARCHAR2(1..10) 1,474,825 0 0 1,474,825 VARCHAR2(11..100) 9,691,520 71 0 9,691,591 VARCHAR2(101..4000) 12,047,400 1,253 0 12,048,653 ------------------- ------------- ------------- --------------- ---------------- CHAR(1..10) 423,413 0 0 423,413 CHAR(11..100) 17 0 0 17 CHAR(101..4000) ------------------- ------------- ------------- --------------- ---------------- Total 23,637,175 1,324 0 23,638,499
This example show how Convertible and Exceptional data is distributed within the database. The granularity of this report is per table. If the list contains only a few rows, it means the Convertible data is localized. If the list contains many rows, it means the Convertible data is spread out in the database.
The following is sample output:
USER.TABLE Convertible Exceptional ------------------------------------------------ ---------------- ---------------- SMG.SOURCE 1 0 SMG.HELP 12 0 SMG.CLOSE_LIST 16 0 SMG.ATTENDEES 8 0 SGT.DR_010_I1T1 7 0 SGT.DR_011_I1T1 7 0 SGT.MRK_SRV_PROFILE 2 0 SGT.MRK_SRV_PROFILE_TEMP 2 0 SGT.MRK_SRV_QUESTION 3 0 ------------------------------------------------ ---------------- ----------------
This example shows how Convertible and Exceptional data is distributed within the database. The granularity of this report is per column. The following is an example:
USER.TABLE|COLUMN Convertible Exceptional ----------------------------------------------- ---------------- ---------------- SMG.SOURCE|SOURCE 1 0 SMG.HELP|INFO 12 0 SMG.CLOSE_LIST|FNAME 1 0 SMG.CLOSE_LIST|LNAME 1 0 SMG.CLOSE_LIST|COMPANY 1 0 SMG.CLOSE_LIST|STREET 8 0 SMG.CLOSE_LIST|CITY 4 0 SMG.CLOSE_LIST|STATE 1 0 SMG.ATTENDEES|ATTENDEE_NAME 1 0 SMG.ATTENDEES|ADDRESS1 3 0 SMG.ATTENDEES|ADDRESS2 2 0 SMG.ATTENDEES|ADDRESS3 2 0 SGT.DR_010_I1T1|WORD_TEXT 7 0 SGT.DR_011_I1T1|WORD_TEXT 7 0 SGT.MRK_SRV_PROFILE|FNAME 1 0 SGT.MRK_SRV_PROFILE|LNAME 1 0 SGT.MRK_SRV_PROFILE_TEMP|FNAME 1 0 SGT.MRK_SRV_PROFILE_TEMP|LNAME 1 0 SGT.MRK_SRV_QUESTION|ANSWER 3 0 ------------------------------------------------ ---------------- ----------------
This generates a list of all the indexes that are affected by the database character set migration. These can be rebuilt upon the import of the data. The following is an example:
USER.INDEX on USER.TABLE(COLUMN) ---------------------------------------------------------------------------- CD2000.COMPANY_IX_PID_BID_NNAME on CD2000.COMPANY(CO_NLS_NAME) CD2000.I_MASHINE_MAINT_CONT on CD2000.MACHINE(MA_MAINT_CONT#) CD2000.PERSON_NEWS_SABUN_CONT_CONT on CD2000.PERSON_NEWS_SABUN_CONT(CONT_BID) CD2000.PENEWSABUN3_PEID_CONT on CD2000.PE_NEWS_SABUN_3(CONT_BID) PMS2000.CALLS_IX_STATUS_SUPPMGR on PMS2000.CALLS(SUPPMGR) PMS2000.MAILQUEUE_CHK_SUB_TOM on PMS2000.MAIL_QUEUE(TO_MAIL) PMS2000.MAILQUEUE_CHK_SUB_TOM on PMS2000.MAIL_QUEUE(SUBJECT) PMS2000.TMP_IX_COMP on PMS2000.TMP_CHK_COMP(COMP_NAME) ----------------------------------------------------------------------------
An Individual Exception Report consists of the following summaries:
This section describes the parameters and the type of scan chosen. The following is an example:
Parameter Value ---------------------------------------- ------------------------------ Scan type Full database Scan CHAR data? YES Current database character set we8mswin1252 New database character set utf8 Scan NCHAR data? NO Array fetch buffer size 102400 Number of rows to heap up for insert 10 Number of processes 1 ---------------------------------------- ------------------------------
This report identifies the data that has exceptions so that this data can then be modified if necessary.
There are two types of exceptions:
The column size should be extended if the maximum column width has been surpassed. If not, data truncation occurs.
The data must be corrected before migrating to the new character set, or else the invalid characters will be converted to a replacement character. Replacement characters are usually specified as '?' or '¿' or a similar linguistically-related character.
The following is an example of an individual exception report that illustrates some possible problems when changing the database character set from WE8ISO8859P1 to UTF8:
User: SCOTT Table: PRODUCT Column: NAME Type: VARCHAR2(10) Number of Exceptions: 2 Max Post Conversion Data Size: 11 ROWID Exception Type Size Cell Data(first 30 bytes) ------------------ ------------------ ----- ------------------------------ AAAA2fAAFAABJwQAAg exceed column size 11 Ährenfeldt AAAA2fAAFAABJwQAAu lossy conversion órâclë8TM AAAA2fAAFAABJwQAAu exceed column size 11 órâclë8TM ------------------ ------------------ ----- ------------------------------
The values Ährenfeldt and órâclë8TM exceed the column size (10 bytes) because each of the characters Ä, ó, â, and ë occupies one byte in WE8ISO8859P1 but two bytes in UTF8. The value órâclë8TM has lossy conversion to UTF8 because the trademark sign TM (code 153) is not a valid WE8ISO8859P1 character. It is a WE8MSWIN1252 character, which is a superset of WE8ISO8859P1.
You can view the data that has an exception by issuing a SELECT statement:
SELECT name FROM scott.product WHERE ROWID='AAAA2fAAFAABJwQAAu';
You can modify the data that has the exception by issuing an UPDATE statement:
UPDATE scott.emp SET ename = 'Oracle8 TM' WHERE ROWID='AAAA2fAAFAABJwQAAu';
This section describes the sizing and the growth of the Scanner's system tables, and explains the approach to maintain them. There are three system tables that can increase rapidly depending on the nature of the data stored in the database.
The Scanner enumerates all tables that need to be scanned into the table CSM$TABLES. Therefore, CSM$TABLES contains as many rows as the number of tables in the database.
You might want to assign a large tablespace to the user CSMIG by amending the CSMINST.SQL script. By default, the SYSTEM tablespace is assigned to the user CSMIG.
You can look up the number of tables in the database by issuing the following SQL statement:
SELECT COUNT(*) FROM DBA_TABLES;
The Scanner stores statistical information for each column scanned into the table CSM$COLUMNS. Therefore, CSM$COLUMNS contains as many rows as the number of character-type columns in the database.
You might want to assign a large tablespace to the user CSMIG by amending the CSMINST.SQL script. By default, the SYSTEM tablespace is assigned to CSMIG user.
You can look up the number of character type columns in the database by issuing the following SQL statement:
SELECT COUNT(*) FROM DBA_TAB_COLUMNS WHERE DATA_TYPE IN ('CHAR', 'VARCHAR2', 'LONG', 'CLOB');
When exceptions are detected with cell data, the Scanner inserts individual exception information into the table CSM$ERRORS. This information then appears in the Individual Exception Report and facilitates identifying records to be modified if necessary.
If your database contains a lot of data that is signaled as Exceptional or Convertible (when the parameter CAPTURE=Y is set), the table CSM$ERRORS can grow too large. You can prevent the CSM$ERRORS table from growing unnecessarily large by using the SUPPRESS parameter.
The SUPPRESS parameter applies to each table. The Scanner suppresses inserting individual Exceptional information after the specified number of exceptions is inserted. Limiting the number of exceptions to be recorded may not be useful if the exceptions are spread over different tables.
You might want to assign a large tablespace to the user CSMIG by amending the CSMINST.SQL script.
This section describes ways to increase performance when scanning the database.
If you plan to scan a relatively large database, for example, over 50GB, you might want to consider using multiple scan processes. This shortens the duration time of database scans by utilizing hardware resources such as CPU and memory available on the machine.
The Scanner fetches multiple rows at a time when an array fetch is allowed. Generally, you will improve performance by letting the Scanner use a bigger array fetch buffer.
The Scanner inserts individual Exceptional and Convertible (when CAPTURE=Y) information into the table CSM$ERRORS. In general, insertion into the CSM$ERRORS table is more costly than data fetching. If your database has a lot of data that is signaled as Exceptional or Convertible, the Scanner issues many insert statements, causing performance degradation. Oracle recommends setting a limit on the number of exception rows to be recorded using the SUPRESS parameter.
This section contains the following reference material:
The Scanner uses the following tables.
This table contains Scanner parameters specified by the user.
| Column | Datatype | NULL | Description |
|---|---|---|---|
|
|
|
|
Parameter name |
|
|
|
|
Parameter value |
This table contains information about database tables to be scanned. The Scanner enumerates all tables to be scanned into this table.
This table contains statistical information of columns that were scanned.
This table contains individual exception information of cell data and object definitions.
The Scanner has the following error messages:
CSC-00100 failed to allocate memory size of number
Cause: An attempt was made to allocate memory with size 0 or bigger than the maximum size.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00101 failed to release memory
Cause: An attempt was made to release memory with invalid pointer.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00102 failed to release memory, null pointer given
Cause: An attempt was made to release memory with null pointer.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00105 failed to parse BOUNDARIES parameter
Cause: BOUNDARIES parameter was specified in an invalid format.
Action: Refer to the manual for the correct syntax.
CSC-00106 failed to parse SPLIT parameter
Cause: SPLIT parameter was specified in an invalid format.
Action: Refer to the manual for the correct syntax.
CSC-00107 CSM$* tables not found
Cause: CSM$VERSION table not found in the database.
Action: Run CSMINST.SQL on the database.
CSC-00108 incompatible CSM$* tables
Cause: Incompatible CSM$* tables found in the database.
Action: Run CSMINST.SQL on the database.
CSC-00110 failed to parse userid
Cause: USERID parameter was specified in an invalid format.
Action: Refer to the manual for the correct syntax.
CSC-00111 failed to get RDBMS version
Cause: Failed to retrieve the value of the Version of the database.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00112 database version not supported
Cause: The database version is older than release 8.0.5.0.0.
Action: Upgrade the database to release 8.0.5.0.0 or later, then try again.
CSC-00113 user %s is not allowed to access data dictionary
Cause: The specified user cannot access the data dictionary.
Action: Set O7_DICTIONARY_ACCESSIBILITY parameter to TRUE, or use SYS user.
CSC-00114 failed to get database character set name
Cause: Failed to retrieve value of NLS_CHARACTERSET or NLS_NCHAR_CHARACTERSET parameter from NLS_DATABASE_PARAMETERS view.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00115 invalid character set name %s
Cause: The specified character set is not a valid Oracle character set.
Action: Refer to the National Language Support Guide for the correct character set name.
CSC-00116 failed to reset NLS_LANG/NLS_NCHAR parameter
Cause: Failed to force NLS_LANG character set to be same as database character set.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00117 failed to clear previous scan log
Cause: Failed to delete all rows from CSM$* tables.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00118 failed to save command parameters
Cause: Failed to insert rows into CSM$PARAMETERS table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00119 failed to save scan start time
Cause: Failed to insert a row into CSM$PARAMETERS table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00120 failed to enumerate tables to scan
Cause: Failed to enumerate tables to scan into CSM$TABLES table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00121 failed to save scan complete time
Cause: Failed to insert a row into CSM$PARAMETERS table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00122 failed to create scan report
Cause: Failed to create database scan report.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00123 failed to check if user %s exist
Cause: Select statement that checks if the specified user exists in the database failed.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00124 user %s not found
Cause: The specified user does not exist in the database.
Action: Check the user name.
CSC-00125 failed to check if table %s.%s exist
Cause: Select statement that checks if the specified table exists in the database failed.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00126 table %s.%s not found
Cause: The specified table does not exist in the database.
Action: Check the user name and table name.
CSC-00127 user %s does not have DBA privilege
Cause: The specified user does not have DBA privileges, which are required to scan the database.
Action: Choose a user with DBA privileges.
CSC-00128 failed to get server version string
Cause: Failed to retrieve the version string of the database.
Action: None.
CSC-00130 failed to initialize semaphore
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00131 failed to spawn scan process %d
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00132 failed to destroy semaphore
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00133 failed to wait semaphore
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00134 failed to post semaphore
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00140 failed to scan table (tid=%d, oid=%d)
Cause: Data scan on this particular table failed.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00141 failed to save table scan start time
Cause: Failed to update a row in the CSM$TABLES table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00142 failed to get table information
Cause: Failed to retrieve various information from user id and object id of the table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00143 failed to get column attributes
Cause: Failed to retrieve column attributes of the table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00144 failed to scan table %s.%s
Cause: Data scan on this particular table was not successful.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00145 failed to save scan result for columns
Cause: Failed to insert rows into CSM$COLUMNS table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00146 failed to save scan result for table
Cause: Failed to update a row of CSM$TABLES table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00147 unexpected data truncation
Cause: Scanner allocates the exactly same size of memory as the column byte size for fetch buffer, resulting in unexpected data truncation.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00150 failed to retrieve table information
Cause: Failed to retrieve the specified table information.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00151 failed to enumerate user tables
Cause: Failed to enumerate all tables that belong to the specified user.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00152 failed to enumerate all tables
Cause: Failed to enumerate all tables in the database.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00153 failed to enumerate character type columns
Cause: Failed to enumerate all CHAR, VARCHAR2, LONG, and CLOB columns of tables to scan.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00154 failed to create list of tables to scan
Cause: Failed to enumerate the tables into CSM$TABLES table.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00155 failed to split tables for scan
Cause: Failed to split the specified tables.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00156 failed to get total number of tables to scan
Cause: Select statement that retrieves the number of tables to scan failed.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00157 failed to retrieve list of tables to scan
Cause: Failed to read all table ids into the scanner memory.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00158 failed to retrieve index defined on column
Cause: Select statement that retrieves index defined on the column fails.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00160 failed to open summary report file
Cause: File open function returned error.
Action: Check if you have create/write privilege on the disk and check if the file name specified for the LOG parameter is valid.
CSC-00161 failed to report scan elapsed time
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00162 failed to report database size information
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00163 failed to report scan parameters
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00164 failed to report Scan summary
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00165 failed to report conversion summary
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00166 failed to report convertible data distribution
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00167 failed to open exception report file
Cause: File open function returned error.
Action: Check if you have create/write privilege on the disk and check if the file name specified for LOG parameter is valid.
CSC-00168 failed to report individual exceptions
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00170 failed to retrieve used size of tablespace %s
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00171 failed to retrieve free size of tablespace %s
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00172 failed to retrieve total size of tablespace %s
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00173 failed to retrieve used size of the database
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00174 failed to retrieve free size of the database
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
CSC-00175 failed to retrieve total size of the database
Cause: Unknown.
Action: This is an internal error. Contact Oracle Customer Support.
Table 3-4 lists common subset/superset relationships.
US7ASCII is a special case because so many other character sets are supersets of it. Table 3-5 lists supersets for US7ASCII.
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|