Release 2 (8.1.6)
Part Number A76934-01
Library |
Product |
Contents |
Index |
| Oracle8i Parallel Server Setup and Configuration Guide Release 2 (8.1.6) Part Number A76934-01 |
|
![]()
![]()
This chapter describe additional configuration issues not covered by the database creation process.
Specific topics discussed are:
The client should be configured with a net service name for the database. This entry should have an address list of all the listeners in the cluster. Additionally, the connect-time failover and client load balancing options should be set.
Connect-time failover instructs the client to failover to the next listener in the address list if the first one fails. Client load balancing instructs the client to randomly select a listener address. This randomization serves to distribute the load so as not to overburden a single listener. Together, these options instruct the client to choose an address randomly. If the chosen address fails, the connection request is failed over to the next address. This way, if an instance should go down, the client can still connect by way of another instance.
To control how the client executes these connection attempts, configure multiple listening addresses and use FAILOVER=ON and LOAD_BALANCE=ON for the address list. For example:
op.us.acme.com= (description= (load_balance=on) (failover=on)(address=(protocol=tcp)(host=idops1)(port=1521))(address=(protocol=tcp)(host=idops2)(port=1521)) (connect_data= (service_name=op.us.acme.com)))
To ensure the files are configured correctly:
SQL> CONNECT internal/password@net_service_name
Oracle displays a "Connected" message.
If there is a connection error, troubleshoot your installation. Typically, this is a result of a problem with the IP address, host name, service name, or instance name.
SQL> UPDATE empset sal = sal + 1000 where ename = 'miller';commit;
SQL> SELECT * from emp;
MILLER's salary should now be $2,300, indicating that all the instances can see the database.
An initialization parameter file is an ASCII text file containing a list of parameters.
In Oracle Parallel Server, some initialization parameters must be identical across all instances. Other parameters, however, can have unique values within each instance. Oracle accommodates both common and unique parameter settings by grouping these parameters into two files, the common (initdb_name.ora) and instance-specific (initsid.ora file) parameter files. If you used Oracle Database Configuration Assistant, these file are already established.
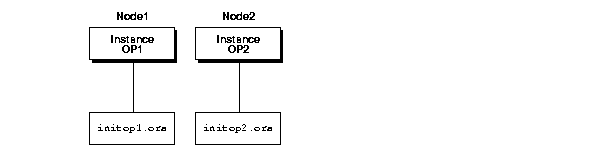
The initsid.ora file uses the IFILE parameter to point to the initdb_name.ora file for common parameters. The initsid.ora file defines the following for each instance:
The sid is the value of the DB_NAME parameter in the initdb_name.ora file and the thread ID. For instance, if the DB_NAME is op, and the first instance has a thread ID of 1, its SID is op1; the second instance uses the SID op2 to identify its instance; and so on.
Example 4-1 and Example 4-2 show the contents of initsid.ora files for two instances with node numbers of 1 and 2 that Oracle Database Configuration Assistant created:
ifile='C:\OracleSW\admin\op\pfile\initop.ora' rollback_segments=(rbs1_1,rbs1_2) thread=1 parallel_server=true instance_name=op1 remote_login_passwordfile=exclusive
ifile='C:\OracleSW\admin\op\pfile\initop.ora' rollback_segments=(rbs2_1,rbs2_2) thread=2 parallel_server=true instance_name=op2 remote_login_passwordfile=exclusive
The parameters are described in the following table:
The initdb_name.ora file is called by the individual parameter files through the IFILE parameter setting in initsid.ora file.
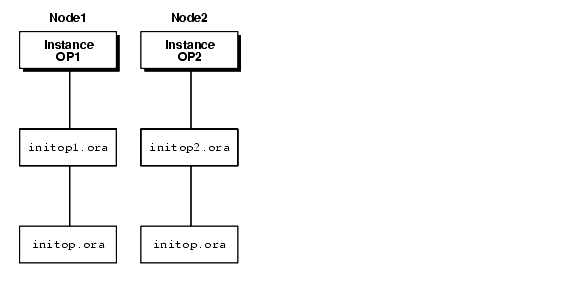
All instances must use the same common file. The instance-specific parameter file is optional. When using the instance-specific parameter file, the IFILE parameter within this file must point to the common file using a complete path name.
Example 4-3 shows a initdb_name.ora file (initop.ora) created for a Hybrid database through Oracle Database Configuration Assistant:
db_name="op" db_domain=us.acme.com service_names=op.us.acme.com db_files=1024 # INITIAL control_files=("\\.\op_control1", "\\.\op_control2") open_cursors=100 db_file_multiblock_read_count=8 # INITIAL db_block_buffers=13816 # INITIAL shared_pool_size=19125248 # INITIAL large_pool_size=18087936 java_pool_size=2097152 log_checkpoint_interval=10000 log_checkpoint_timeout=1800 processes=50 # INITIAL parallel_max_servers=5 # SMALL log_buffer=32768 # INITIAL max_dump_file_size=10240 # limit trace file size to 5M each global_names=true oracle_trace_collection_name="" background_dump_dest=C:\OracleSW\admin\op\bdump user_dump_dest=C:\OracleSW\admin\op\udump db_block_size=4096 remote_login_passwordfile=exclusive os_authent_prefix="" distributed_transactions=10 mts_dispatchers="(protocol=TCP)(lis=listeners_op)" compatible=8.1.0 sort_area_size=65536 sort_area_retained_size=65536
Take note of the following parameters:
| Parameter | Description |
|---|---|
|
BACKGROUND_DUMP_DEST |
Specifies the directory path where debugging trace file for background processes (LGWR, DBWRn, and so on) are written during Oracle operations |
|
CONTROL_FILES |
Specifies the control files |
|
DB_NAME |
Specifies the name of the database, |
|
DB_DOMAIN |
Specifies the database domain, |
|
MTS_DISPATCHERS |
Enables multi-threaded server (MTS) for this database MTS_DISPATCHERS may contain many attributes. At a minimum, Oracle Corporation recommends setting the following attributes:
Oracle Corporation recommends setting MTS_DISPATCHERS as follows: mts_dispatchers="(protocol=tcp)(listener=listeners_db_name)"
For example, the MTS_DISPATCHERS parameter can be set as follows in the mts_dispatchers="(protocol=tcp)(listener=listeners_op)"
listeners_op= (description= (address_list= The entry should contain only the listener address, not the service name information in the CONNECT_DATA portion of a connect descriptor. See Also:
|
|
SERVICE_NAMES |
Specifies the names of the database services on the network, It is possible to provide multiple services names (by individual SERVICE_NAMES entries) so that different usages of a instance can be identified separately. Service names can also be used to identify a service that is available from multiple instances through the use of replication. |
|
USER_DUMP_DEST |
Specifies the directory path where the server writes debugging trace files on behalf of a user process |
This section explains how to configure archive logs to enable you to use Recovery Manager (RMAN) for backup and recovery of an Oracle Parallel Server database.
To configure RMAN for Oracle Parallel Server, perform the following tasks as described in this section:
See Also:
To enable RMAN to back up and recover an Oracle Parallel Server database in one step and to use RMAN by way of the Oracle Enterprise Manager Recovery Wizard, all nodes must use the same name for the archive log and must have access to all archive logs. When Oracle generates each archive log, Oracle records the name of the log in the control file or in the recovery catalog. RMAN accesses the archive log files by this name regardless of which node is running RMAN. The easiest way to configure this is to share the archive log directories, as explained under the following headings.
To configure shared archive log destinations on UNIX using NFS (Network File Server), create the same directory structure for the archive logs on every instance. For a three-node cluster, for example, one of the entries is the local archive log destination, and the other two entries are the NFS mounting points for the remote archive logs. Create the following directory structures on each node.
$ORACLE_HOME/admin/db_name/arch1 $ORACLE_HOME/admin/db_name/arch2 $ORACLE_HOME/admin/db_name/arch3
Each instance writes archive logs to its local archive directory and to the remote directories.
arch1 is the local archive log destination for the instance. The other entries for arch2 and arch3 are the mount points for the archive logs for the instances on the second and third nodes.
arch1 is a mount point for the remote archive log on the first node, the second entry for arch2 is the local archive log directory, and the third entry for arch3 is a mount point for the remote archive log on the third node.
arch1 is a mount point for the remote archive log on the first node, the second entry for arch2 is a mount point for the remote archive log on the second node, and the third entry for arch3 is a mount point for the local archive log directory.
Exercise caution when using NFS in Parallel Server environments. If you use "hard NFS" (default), you can block the entire cluster if the remote directories become inaccessible. This might occur as a result of a hardware failure. For this reason, Oracle Corporation strongly recommends that you use NFS implemented for high availability or soft-mounted NFS directories, as explained in the following sections:
The optimal solution is to use a NFS implemented for high availability. This solution uses the exported NFS directory stored on the shared disks of a cluster. One node is the primary node that is used to allow access to the files. If this node fails, a failover process changes the access path to a backup node that also has access to the shared disks. If your hardware supports NFS for high availability, consult your vendor to configure this feature. Otherwise, continue with the procedures under the next heading.
Soft mounting means that a process attempting to access the mounted directory is not blocked until the directory becomes available after a failure.
Contact your hardware vendor if your cluster supports soft mounted NFS directories between the nodes in a cluster. Consult your vendor documentation because the commands to configure this are operating system dependent.
On Sun Solaris, for example, create a soft mounted directory using the following commands:
mount -F NFS -o soft,rw,retry=10,timeo=30 node1: /ORACLE_HOME/admin/db_name/arch1 /ORACLE_HOME/admin/db_name/arch1
To ensure that each node generates archive logs in its local partition, set the LOG_ARCHIVE_DEST parameter equal to the path for the local archive log file. Using the previous example, make the following entries in the parameter files for the three instances:
In initop1.ora enter:
log_archive_dest_1="location=/ORACLE_HOME/admin/db_name/arch1"
In initop2.ora enter:
log_archive_dest_1="location=/ORACLE_HOME/admin/db_name/arch2"
In initop3.ora enter:
log_archive_dest_1="location=/ORACLE_HOME/admin/db_name/arch3"
Oracle Corporation recommends mirroring an additional copy or your archived logs from that node to a remote host. This is explained in "Configuring the Archiver to Write to Multiple Log Destinations".
To configure shared archive logs on Windows NT:
idops1, idops2, and idops3, and if drive letters J, K, and L are unused, assign these letters to the nodes as shown in the following table:
| Node Name | Drive Letter |
|---|---|
|
|
J: |
|
|
K: |
|
|
L: |
Each partition will be a local archive log destination for the instance running on that node. To configure this, assign the drive letter owned by that node to the new partition. Continuing with the example in Step 1, on idops1, create a new partition named "J:", on idops2, create a new partition named "K:", and so on. When you create each new partition, also create a directory hierarchy called \archivelogs as shown in the following table:
| Node Name | Command |
|---|---|
|
|
|
|
|
|
|
|
|
net share <db_name>_logs=<drive_letter>:\
using the variables db_name and drive_letter as in the example shown in the following table, where the database name is op:
| Node Name | Command |
|---|---|
|
|
|
|
|
|
|
|
|
net use \\<node_name>\<db_name>_logs <drive_letter>:
For this example, use the variables node_name, db_name, and drive_letter as in the following entries:
On idops1, that has local drive J:, enter
net use \\node2\OP_logs K: net use \\node3\OP_logs L:
On idops2, that has local drive K:, enter:
net use \\node1\OP_logs J: net use \\node3\OP_logs L:
On idops3, that has local drive L:, enter:
net use \\node1\OP_logs J: net use \\node2\OP_logs K:
In initop1.ora enter:
log_archive_dest_1="location=J:\archivelogs"
In initop2.ora enter:
log_archive_dest_1="location=K:\archivelogs"
In initop3.ora enter:
log_archive_dest_1="location=L:\archivelogs"
|
Note: You can use the LOG_ARCHIVE_DEST_n parameter to configure up to 5 log archive destinations. For more information about this parameter, refer to the Oracle8i Reference. |
After you have configured your directories, complete the steps described in this section to configure the archiver so it can write to multiple destinations. Multiple archive log destinations avoid single-points-of-failure by making the archive logs for a failed node available to other nodes for recovery processing.
Configure each node to archive to its local disk and to a remote disk. For the remote destination disk, Oracle Corporation recommends that you arrange your nodes in a circular sequence. Do this to allow the first node to write to second node, the second node to write to the third node, and so on. The last node should write to the first node. This way, each node writes to a remote archive log file as well as to a local file.
Configure your archive log destinations for UNIX or Windows, as described in the following sections:
There are two methods for configuring archive log destinations on UNIX as described under the following headings:
To configure multiple destinations on UNIX using shared archive log destinations, add the following initialization parameters to the previous configuration example for UNIX:
In initop1.ora
log_archive_dest_2="location=/ORACLE_HOME/admin/db_name/arch2"
In initop2.ora
log_archive_dest_2="location=/ORACLE_HOME/admin/db_name/arch3"
In initop3.ora
log_archive_dest_2="location=/ORACLE_HOME/admin/db_name/arch1"
If your cluster hardware does not support shared directories with NFS, back up all local files with RMAN. For recovery, copy all the log files to the node from which you want to begin recovery. To automate this, create a shell script to store the necessary remote copy commands. Then to enable RMAN to find the logs, save the logs in a directory hierarchy with the same name as the source directory. On node 1 use the following script:
#!/bin/sh sqlplus system/manager@node1 @switchlog.sql rcp node2:/ORACLE_HOME/admin/db_name/arch2/* /ORACLE_HOME/admin/db_name/arch2 rcp node3:/ORACLE_HOME/admin/db_name/arch3/* /ORACLE_HOME/admin/db_name/arch3
The switchlog.sql script that is called by the previous script ensures you retrieve all the log files. The contents of switch.sql should be:
#!/bin/sh alter system archive log current; exit
For example, add the following initialization parameters to the "Configuring Shared Archive Log Destinations on Windows NT":
In initop1.ora
log_archive_dest_2="location=K:archivelogs"
In initop2.ora
log_archive_dest_2="location=L:archivelogs"
In initop3.ora
log_archive_dest_2="location=J:archivelogs"
To access remote archive log directories from your database, configure the OracleServicesid to start with a Windows account that has permission to write to this directory. Otherwise, attempts to do so produce the following message:
ORA-9291: sksachk: invalid device specified for archive destination.
To perform a closed, consistent backup with Oracle Enterprise Manager's Backup Wizard, you must shut down all instances except the first node's instance.
|
See Also:
|
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|