Release 2 (8.1.6)
Part Number A76959-01
Library |
Product |
Contents |
Index |
| Oracle8i Replication Release 2 (8.1.6) Part Number A76959-01 |
|
![]()
![]()
This chapter describes several advanced techniques that you can use in implementing an Oracle replicated database environment:
Procedural replication can offer performance advantages for large batch-oriented operations operating on large numbers of rows that can be run serially within a replicated environment.
A good example of an appropriate application is a purge operation, also referred to as an archive operation, that you run infrequently (for example, once per quarter) during off hours to remove old data, or data that was "logically" deleted from the online database. An example using procedural replication to purge deleted rows is described in "Avoiding Delete Conflicts".
All parameters for a replicated procedure must be IN parameters; OUT and IN/OUT modes are not supported. The datatypes supported for these parameters are: NUMBER, DATE, VARCHAR2, CHAR, ROWID, RAW, BLOB, CLOB, NCHAR, NVARCHAR, and NCLOB.
Oracle cannot detect update conflicts produced by replicated procedures. Replicated procedures must detect and resolve conflicts themselves. Because of the difficulties involved in writing your own conflict resolution routines, it is best to simply avoid the possibility of conflicts altogether.
Adhering to the following guidelines helps you ensure that your tables remain consistent at all sites when you plan to use procedural replication.
For example, if you have a procedure named SAL_RAISE in master group A on master site DB1, you cannot execute the SAL_RAISE procedure if master group B on master site DB1 is quiesced, even if master group A is replicating normally.
Serial execution ensures that your data remains consistent. The replication facility propagates and executes replicated transactions one at a time. For example, assume that you have two procedures, A and B, that perform updates on local data. Now assume that you perform the following actions, in order:
The replicas of A and B on the other nodes are executed completely serially, in the same order that they were committed at the originating site. If A and B execute concurrently at the originating site, however, they may produce different results locally than they do remotely. Executing A and B serially at the originating site ensures that all sites have identical results. Propagating the transaction serially ensures that A and B are executing in serial order at the target site in all cases.
Alternatively, you could write the procedures carefully, to ensure serialization. For example, you could use SELECT... FOR UPDATE for queries to ensure serialization at the originating site and at the target site if you are using parallel propagation.
You must disable row-level replication support at the start of your procedure, and then re-enable support at the end. This ensures that any updates that occur as a result of executing the procedure are not propagated to other sites. Row-level replication is enabled and disabled by calling the following procedures, respectively:
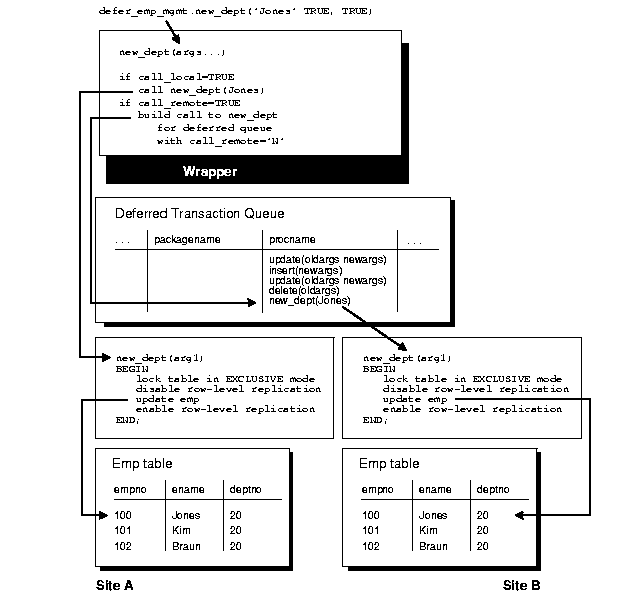
When you generate replication support for your replicated package, Oracle creates a wrapper package in the schema of the replication propagator.
The wrapper package has the same name as the original package, but its name is prefixed with the string you supply when you generate replication support for the procedure. If you do not supply a prefix, Oracle uses the default prefix, "defer_". The wrapper procedure has the same parameters as the original, along with two additional parameters: CALL_LOCAL and CALL_REMOTE. These two boolean parameters determine where the procedure gets executed. When CALL_LOCAL is TRUE, the procedure is executed locally. When CALL_REMOTE is TRUE, the procedure will ultimately be executed at all other master sites in the replicated environment.
The remote procedures are called directly if you are propagating changes synchronously. Or calls to these procedures are added to the deferred transaction queue if you are propagating changes asynchronously. By default, CALL_LOCAL is FALSE, and CALL_REMOTE is TRUE.
Oracle generates replication support for a package in two phases. The first phase creates the package specification at all sites. Phase two generates the package body at all sites. These two phases are necessary to support synchronous replication.
For example, suppose you create the package EMP_MGMT containing the procedure NEW_DEPT, which takes one argument, ENAME. To replicate this package to all master sites in your system, you can use Replication Manager to add the package to a master group and then generate replication support for the object. See the Replication Manager online help for more information about managing master groups and replicated objects using Replication Manager. After completing these steps, an application can call procedure in the replicated package as follows:
defer_emp_mgmt.new_dept( ename => 'Jones', call_local => TRUE, call_remote => TRUE);
As shown in Figure 6-1, the logic of the wrapper procedure ensures that the procedure is called at the local site and subsequently at all remote sites. The logic of the wrapper procedure also ensures that when the replicated procedure is called at the remote sites, CALL_REMOTE is FALSE, ensuring that the procedure is not further propagated.
If you are operating in a mixed replicated environment with static partitioning of data ownership (that is, if you are not preventing row-level replication), the replication facility preserves the order of operations at the remote node, because both row-level and procedural replication use the same asynchronous queue.
Survivability provides the capability to continue running applications despite system or site failures. Survivability allows you to run applications on a fail over system, accessing the same, or very nearly the same, data as these systems accessed on the primary system when it failed. As shown in Figure 6-2, the Oracle server provides two different technologies for accomplishing survivability: the Oracle Parallel Server and the replication facility.
The Oracle Parallel Server supports fail over to surviving systems when a system supporting an instance of the Oracle Server fails. The Oracle Parallel Server requires a cluster or massively parallel hardware platform, and thus is applicable for protection against processor system failures in the local environment where the cluster or massively parallel system is running.
In these environments, the Oracle Parallel Server is the ideal solution for survivability -- supporting high transaction volumes with no lost transactions or data inconsistencies in the event of an instance failure. If an instance fails, a surviving instance of the Oracle Parallel Server automatically recovers any incomplete transactions. Applications running on the failed system can execute on the fail over system, accessing all data in the database.
The Oracle Parallel Server does not, however, provide survivability for site failures (such as flood, fire, or sabotage) that render an entire site, and thus the entire cluster or massively parallel system, inoperable. To provide survivability for site failures, you can use the replication facility to maintain a replica of a database at a geographically remote location.
Should the local system fail, the application can continue to execute at the remote site. Replication, however, cannot guarantee the protection of all transactions. Also, special care must be taken to prevent data inconsistencies when recovering the primary site.
|
Note: You can also configure a standby-database to protect an Oracle database from site failures. For more information about Oracle's standby database feature, see the Oracle8i Backup and Recovery Guide. |
If you choose to use the replication facility for survivability, you should consider the following issues:
Suppose, for example, you are running an order-entry system that uses replication to maintain a remote fail over order-entry system, and the primary system fails.
At the time of the failure, there were two transactions recently executed at the primary site that did not have their changes propagated and applied at the fail over site. The first of these was a transaction that entered a new order, and the second was a transaction that cancelled an existing order.
In the first case, someone may notice the absence of the new order when processing continues on the fail over system, and re-enter it. In the second case, the cancellation of the order may not be noticed, and processing of the order may proceed; that is, the canceled item may be shipped and the customer billed.
What happens when you restore the primary site? If you simply push all of the changes executed on the fail over system back to the primary system, you will encounter conflicts.
Specifically, there will be duplicate orders for the item originally ordered at the primary system just before it failed. Additionally, there will be data changes resulting from the transactions to ship and bill the order that was originally canceled on the primary system.
You must carefully design your system to deal with these situations. The next section explains this process.
Oracle's replication facility can be used to provide survivability against site failures by using multiple replicated master sites. You must configure your system using one of the following methods. These methods are listed in order of increasing implementation difficulty.
You can use Net8 to configure automatic connect-time failover, which enables Net8 to fail over to a different master site if the first master site fails. You configure automatic connect-time failover in your tnsnames.ora file by setting the FAILOVER option to ON and specifying multiple connect descriptors.
Databases using replication are distributed databases. Follow the guidelines for distributed database backups outlined in the Oracle8i Administrator's Guide when creating backups of replicated databases. Follow the guidelines for coordinated distributed recovery in the Oracle8i Administrator's Guide when recovering a replication database.
If you fail to follow the coordinated distributed recovery guidelines, there is no guarantee that your replication databases will be consistent. For example, a restored master site may have propagated different transactions to different masters. You may need to perform extra steps to correct for an incorrect recovery operation. One such method is to drop and recreate all replicated objects in the recovered database.
After performing an export/import of a replicated object or an object used by the replication facility (for example, the DBA_REPSITES view), you should run the REPCAT_IMPORT_CHECK procedure in the DBMS_REPCAT package.
In the following example, the procedure checks the objects in the ACCT replicated object group at a snapshot site to ensure that they have the appropriate object identifiers and status values:
DBMS_REPCAT.REPCAT_IMPORT_CHECK( gname => 'acct', master => FALSE);
|
See Also:
The REPCAT_IMPORT_CHECK procedure in the Oracle8i Replication Management API Reference book for details |
This section describes a more advanced method of designing your applications to avoid conflicts. This method, known as token passing, is similar to the workflow method described below. Although this section describes how to use this method to control the ownership of an entire row, you can use a modified form of this method to control ownership of the individual column groups within a row.
Both workflow and token passing allow dynamic ownership of data. With dynamic ownership, only one site at a time is allowed to update a row, but ownership of the row can be passed from site to site. Both workflow and token passing use the value of one or more "identifier" columns to determine who is currently allowed to update the row.
With workflow partitioning, you can think of data ownership as being "pushed" from site to site. Only the current owner of the row is allowed to push the ownership of the row to another site, by changing the value of the "identifier" columns.
Take the simple example of separate sites for ordering, shipping, and billing. Here, the identifier columns are used to indicate the status of an order. The status determines which site can update the row. After a user at the ordering site has entered the order, he or she updates the status of this row to SHIP. Users at the ordering site are no longer allowed to modify this row -- ownership has been pushed to the shipping site.
After shipping the order, the user at the shipping site updates the status of this row to BILL, thus pushing ownership to the billing site, and so on.
To successfully avoid conflicts, applications implementing dynamic data ownership must ensure that the following conditions are met:
With workflow partitioning, only the current owner of the row can push the ownership of the row to the next site by updating the "identifier" columns. No site is given ownership unless another site has given up ownership; thus ensuring there is never more than one owner.
Because the flow of work is ordered, ordering conflicts can be resolved by applying the change from the site that occurs latest in the flow of work. Any ordering conflicts can be resolved using a form of the PRIORITY conflict resolution method, where the priority value increases with each step in the work flow process.
The PRIORITY conflict resolution method successfully converges for more than one master as long as the priority value is always increasing.
Token passing uses a more generalized approach to meeting these criteria. To implement token passing, instead of the "identifier" columns, your replicated tables must have owner and epoch columns. The owner column stores the global database name of the site currently believed to own the row.
Once you have designed a token passing mechanism, you can use it to implement a variety of forms of dynamic partitioning of data ownership, including workflow.
You should design your application to implement token passing for you automatically. You should not allow the owner or epoch columns to be updated outside this application.
Whenever you attempt to update a row, your application should:
For example, Figure 6-3 illustrates how ownership of employee 100 passes from the ACCT_SF database to the ACCT_NY database.
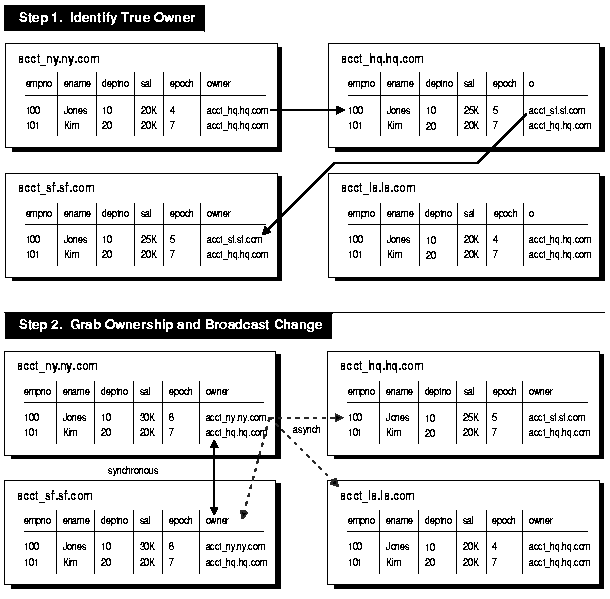
To obtain ownership, the ACCT_NY database uses a simple recursive algorithm to locate the owner of the row. The pseudo code for this algorithm is shown below:
-- Pseudo code for locating the token owner. -- This is for a table TABLE_NAME with primary key PK. -- Initial call should initialize loc_epoch to 0 and loc_owner -- to the local global name. get_owner(PK IN primary_key_type, loc_epoch IN OUT NUMBER, loc_owner IN OUT VARCHAR2) { -- use dynamic SQL (dbms_sql) to perform a select similar to -- the following: SELECT owner, epoch into rmt_owner, rmt_epoch FROM TABLE_NAME@loc_owner WHERE primary_key = PK FOR UPDATE; IF rmt_owner = loc_owner AND rmt_epoch >= loc_epoch THEN loc_owner := rmt_owner; loc_epoch := rmt_epoch; RETURN; ELSIF rmt_epoch >= loc_epoch THEN get_owner(PK, rmt_epoch, rmt_owner); loc_owner := rmt_owner; loc_epoch := rmt_epoch; RETURN; ELSE raise_application_error(-20000, 'No owner for row'); END IF; }
After locating the owner of the row, the ACCT_NY site gets ownership from the ACCT_SF site by completing the following steps:
When the SF changes (that were in the deferred queue in Step 2 above) are ultimately propagated to the NY site, the NY site ignores them because they have a lower epoch number than the epoch number at the NY site for the same data.
As another example, suppose the HQ site received the SF changes after receiving the NY changes, the HQ site would ignore the SF changes because the changes applied from the NY site would have the greater epoch number.
You should design your application to implement this method of token passing for you automatically whenever you perform an update. You should not allow the owner or epoch columns to be updated outside this application. The lock that you grab when you change ownership is released when you apply your actual update. The changed information, along with the updated owner and epoch information, are asynchronously propagated to the other sites in the usual manner.
You may encounter a situation where you need to modify a replicated object, but you do not want this modification replicated to the other sites in the replicated environment. For example, you might want to disable replication in the following situations:
You might need to do this, for example, if you need to correct the state of a record at one site so that a conflicting replicated update will succeed when you re-execute the error transaction. Or you might use an unreplicated modification to undo the effects of a transaction at its origin site because the transaction could not be applied at the destination site. In this example, you can use Replication Manager to delete the conflicting transaction from the destination site.
To modify tables without replicating the modifications, use the REPLICATION_ON and REPLICATION_OFF procedures in the DBMS_REPUTIL package. These procedures take no arguments and are used as flags by the generated replication triggers.
The DBMS_REPUTIL.REPLICATION_OFF procedure sets the state of an internal replication variable for the current session to FALSE. Because all replicated triggers check the state of this variable before queuing any transactions, modifications made to the replicated tables that use row-level replication do not result in any queued deferred transactions.
If you are using procedural replication, you should call REPLICATION_OFF at the start of your procedure, as shown in the following example. This ensures that the replication facility does not attempt to use row-level replication to propagate the changes that you make.
CREATE OR REPLACE PACKAGE update AS PROCEDURE update_emp(adjustment IN NUMBER); END; / CREATE OR REPLACE PACKAGE BODY update AS PROCEDURE update_emp(adjustment IN NUMBER) IS BEGIN -- turn off row-level replication for set update dbms_reputil.replication_off; UPDATE emp . . .; -- re-enable replication dbms_reputil.replication_on; EXCEPTION WHEN OTHERS THEN . . . dbms_reputil.replication_on; END; END;
After resolving any conflicts, or at the end of your replicated procedure, be certain to call DBMS_REPUTIL.REPLICATION_ON to resume normal replication of changes to your replicated tables or snapshots. This procedure takes no arguments. Calling REPLICATION_ON sets the internal replication variable to TRUE.
If you have defined a replicated trigger on a replicated table, you may need to ensure that the trigger fires only once for each change that you make. Typically, you only want the trigger to fire when the change is first made, and you do not want the remote trigger to fire when the change is replicated to the remote site.
You should check the value of the DBMS_REPUTIL.FROM_REMOTE package variable at the start of your trigger. The trigger should update the table only if the value of this variable is FALSE.
Alternatively, you can disable replication at the start of the trigger and re-enable it at the end of the trigger when modifying rows other than the one that caused the trigger to fire. Using this method, only the original change is replicated to the remote sites. Then the replicated trigger fires at each remote site. Any updates performed by the replicated trigger are not pushed to any other sites.
Using this approach, conflict resolution is not invoked. Therefore, you must ensure that the changes resulting from the trigger do not affect the consistency of the data.
To disable all local replication triggers for snapshots at your current site, set the internal refresh variable to TRUE by calling SET_I_AM_A_REFRESH, as shown in the following example:
DBMS_SNAPSHOT.SET_I_AM_A_REFRESH(value => TRUE);
To re-enable the triggers, set the internal refresh variable to FALSE, as shown below:
DBMS_SNAPSHOT.SET_I_AM_A_REFRESH(value => FALSE);
To determine the value of the internal refresh variable, call the I_AM_A_REFRESH function as shown below:
ref_stat := DBMS_SNAPSHOT.I_AM_A_REFRESH;
In a multimaster replication environment, Oracle ensures that transactions propagated to remote sites are never lost and never propagated more than once, even when failures occur.
Protection against failures is provided for both serial and parallel propagation.
Oracle maintains dependency ordering when propagating replicated transactions to remote systems. For example:
Transaction B is dependent on Transaction A because Transaction B sees the committed update cancelling the order (Transaction A) on the local system.
Oracle propagates Transaction B (the refund) after it successfully propagates Transaction A (the order cancellation). Oracle applies the updates that process the refund after it applies the cancellation.
When Oracle on the local system executes a new transaction,
Parallel propagation maintains data integrity in a manner different from that of serial propagation. With serial propagation, Oracle applies all transaction in the same order that they commit on the local system to maintain any dependencies. With parallel propagation, Oracle tracks dependencies and executes them in commit order when dependencies can exist; in parallel when dependencies cannot exist. With both serial and parallel propagation, Oracle preserves the order of execution within a transaction. The deferred transaction executes every remote procedure call at each system in the same order as it was executed within the local transaction.
Certain application conditions can establish dependencies among transactions that force Oracle to serialize the propagation of deferred transactions. When several unrelated transactions modify the same data block in a replicated table, Oracle serializes the propagation of the corresponding transactions to remote destinations.
To minimize transaction dependencies created at the data block level, you should try to avoid situations that concentrate data block modifications into one or a small number of data blocks. For example:
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|
