Release 2 (8.1.6)
Part Number A76994-01
Library |
Product |
Contents |
Index |
| Oracle8i Data Warehousing Guide Release 2 (8.1.6) Part Number A76994-01 |
|
![]()
![]()
The following topics provide information about how to improve analytical SQL queries in a data warehouse:
Oracle has enhanced SQL's analytical processing power along several paths:
The CUBE and ROLLUP extensions to SQL make querying and reporting easier in data warehousing environments. ROLLUP creates subtotals at increasing levels of aggregation, from the most detailed up to a grand total. CUBE is an extension similar to ROLLUP, enabling a single statement to calculate all possible combinations of subtotals. CUBE can generate the information needed in cross-tabulation reports with a single query.
Analytic functions enable rankings, moving window calculations, and lead/lag analysis. Ranking functions include cumulative distributions, percent rank, and N-tiles. Moving window calculations allow you to find moving and cumulative aggregations, such as sums and averages. Lead/lag analysis enables direct inter-row references so you can calculate period-to-period changes.
Other enhancements to SQL include a family of regression functions and the CASE expression. Regression functions offer a full set of linear regression calculations. CASE expressions provide if-then logic useful in many situations.
These CUBE and ROLLUP extensions and analytic functions are part of the core SQL processing. To enhance performance, CUBE, ROLLUP, and analytic functions can be parallelized: multiple processes can simultaneously execute all of these statements. These capabilities make calculations easier and more efficient, thereby enhancing database performance, scalability, and simplicity.
One of the key concepts in decision support systems is multi-dimensional analysis: examining the enterprise from all necessary combinations of dimensions. We use the term dimension to mean any category used in specifying questions. Among the most commonly specified dimensions are time, geography, product, department, and distribution channel, but the potential dimensions are as endless as the varieties of enterprise activity. The events or entities associated with a particular set of dimension values are usually referred to as facts. The facts may be sales in units or local currency, profits, customer counts, production volumes, or anything else worth tracking.
Here are some examples of multidimensional requests:
All the requests above involve multiple dimensions. Many multidimensional questions require aggregated data and comparisons of data sets, often across time, geography or budgets.
To visualize data that has many dimensions, analysts commonly use the analogy of a data cube, that is, a space where facts are stored at the intersection of n dimensions. Figure 17-1 shows a data cube and how it could be used differently by various groups. The cube stores sales data organized by the dimensions of Product, Market, and Time.
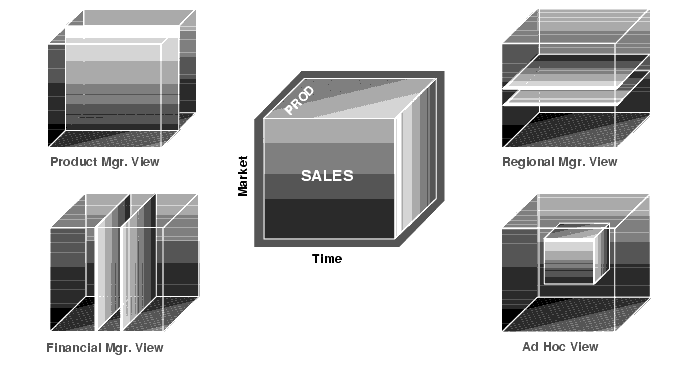
We can retrieve slices of data from the cube. These correspond to cross-tabular reports such as the one shown in Table 17-1. Regional managers might study the data by comparing slices of the cube applicable to different markets. In contrast, product managers might compare slices that apply to different products. An ad hoc user might work with a wide variety of constraints, working in a subset cube.
Answering multidimensional questions often involves accessing and querying huge quantities of data, sometimes millions of rows. Because the flood of detailed data generated by large organizations cannot be interpreted at the lowest level, aggregated views of the information are essential. Subtotals across many dimensions are vital to multidimensional analyses. Therefore, analytical tasks require convenient and efficient data aggregation.
Not only multidimensional issues, but all types of processing can benefit from enhanced aggregation facilities. Transaction processing, financial and manufacturing systems--all of these generate large numbers of production reports needing substantial system resources. Improved efficiency when creating these reports will reduce system load. In fact, any computer process that aggregates data from details to higher levels needs optimized performance.
Oracle8i extensions provide aggregation features and bring many benefits, including:
Oracle8i provides all these benefits with the new CUBE and ROLLUP extensions to the GROUP BY clause. These extensions adhere to the ANSI and ISO proposals for SQL3, a draft standard for enhancements to SQL.
To illustrate CUBE and ROLLUP queries, this chapter uses a hypothetical videotape sales and rental company. All the examples given refer to data from this scenario. The hypothetical company has stores in several regions and tracks sales and profit information. The data is categorized by three dimensions: Time, Department, and Region. The time dimension members are 1996 and 1997, the departments are Video Sales and Video Rentals, and the regions are East, West, and Central.
Table 17-1 is a sample cross-tabular report showing the total profit by region and department in 1999:
|
1999 |
|||
| Region |
Department |
||
| Video Rental Profit | Video Sales Profit | Total Profit | |
| Central |
82,000 |
85,000 |
167,000 |
| East |
101,000 |
137,000 |
238,000 |
| West |
96,000 |
97,000 |
193,000 |
| Total |
279,000 |
319,000 |
598,000 |
Consider that even a simple report like Table 17-1, with just twelve values in its grid, generates five subtotals and a grand total. The subtotals are the shaded numbers. Half of the values needed for this report would not be calculated with a query that used standard SUM() and GROUP BY operations. Database commands that offer improved calculation of subtotals bring major benefits to querying, reporting, and analytical operations.
ROLLUP enables a SELECT statement to calculate multiple levels of subtotals across a specified group of dimensions. It also calculates a grand total. ROLLUP is a simple extension to the GROUP BY clause, so its syntax is extremely easy to use. The ROLLUP extension is highly efficient, adding minimal overhead to a query.
ROLLUP appears in the GROUP BY clause in a SELECT statement. Its form is:
SELECT ... GROUP BY ROLLUP(grouping_column_reference_list)
ROLLUP's action is straightforward: it creates subtotals which roll up from the most detailed level to a grand total, following a grouping list specified in the ROLLUP clause. ROLLUP takes as its argument an ordered list of grouping columns. First, it calculates the standard aggregate values specified in the GROUP BY clause. Then, it creates progressively higher-level subtotals, moving from right to left through the list of grouping columns. Finally, it creates a grand total.
ROLLUP creates subtotals at n+1 levels, where n is the number of grouping columns. For instance, if a query specifies ROLLUP on grouping columns of Time, Region, and Department (n=3), the result set will include rows at four aggregation levels.
This example of ROLLUP uses the data in the video store database, the same database as was used in Table 17-1, "Simple Cross-Tabular Report, with Subtotals Shaded".
SELECT Time, Region, Department, SUM(Profit) AS Profit FROM sales GROUP BY ROLLUP(Time, Region, Dept);
As you can see in Output 15-1, this query returns the following sets of rows:
ROLLUP Aggregation across Three Dimensions
Time Region Department Profit ---- ------ ---------- ------ 1996 Central VideoRental 75,000 1996 Central VideoSales 74,000 1996 Central NULL 149,000 1996 East VideoRental 89,000 1996 East VideoSales 115,000 1996 East NULL 204,000 1996 West VideoRental 87,000 1996 West VideoSales 86,000 1996 West NULL 173,000 1996 NULL NULL 526,000 1997 Central VideoRental 82,000 1997 Central VideoSales 85,000 1997 Central NULL 167,000 1997 East VideoRental 101,000 1997 East VideoSales 137,000 1997 East NULL 238,000 1997 West VideoRental 96,000 1997 West VideoSales 97,000 1997 West NULL 193,000 1997 NULL NULL 598,000 NULL NULL NULL 1,124,000
NULLs returned by ROLLUP and CUBE are not always the traditional null meaning value unknown. Instead, a NULL may indicate that its row is a subtotal. For instance, the first NULL value shown in Output 15-1 is in the Department column. This NULL means that the row is a subtotal for "All Departments" for the Central region in 1996. To avoid introducing another non-value in the database system, these subtotal values are not given a special tag.
See the section "GROUPING Function" for details on how the NULLs representing subtotals are distinguished from NULLs stored in the data.
You can also ROLLUP so that only some of the sub-totals will be included. This partial rollup uses the following syntax:
GROUP BY expr1, ROLLUP(expr2, expr3);
In this case, ROLLUP creates subtotals at (2+1=3) aggregation levels. That is, at level (expr1, expr2, expr3), (expr1, expr2), and (expr1). It does not produce a grand total.
Example:
This example of partial ROLLUP uses the data in the video store database.
SELECT Time, Region, Department, SUM(Profit) AS Profit FROM sales GROUP BY Time, ROLLUP(Region, Dept);
As you can see in Output 15-2, this query returns the following sets of rows:
Partial ROLLUP
Time Region Department Profit ---- ------ ---------- ------ 1996 Central VideoRental 75,000 1996 Central VideoSales 74,000 1996 Central NULL 149,000 1996 East VideoRental 89,000 1996 East VideoSales 115,000 1996 East NULL 204,000 1996 West VideoRental 87,000 1996 West VideoSales 86,000 1996 West NULL 173,000 1996 NULL NULL 526,000 1997 Central VideoRental 82,000 1997 Central VideoSales 85,000 1997 Central NULL 167,000 1997 East VideoRental 101,000 1997 East VideoSales 137,000 1997 East NULL 238,000 1997 West VideoRental 96,000 1997 West VideoSales 97,000 1997 West NULL 193,000 1997 NULL NULL 598,000
The result set in Table 17-1 could be generated by the UNION of four SELECT statements, as shown below. This is a subtotal across three dimensions. Notice that a complete set of ROLLUP-style subtotals in n dimensions would require n+1 SELECT statements linked with UNION ALL.
SELECT Time, Region, Department, SUM(Profit) FROM Sales GROUP BY Time, Region, Department UNION ALL SELECT Time, Region, '' , SUM(Profit) FROM Sales GROUP BY Time, Region UNION ALL SELECT Time, '', '', SUM(Profits) FROM Sales GROUP BY Time UNION ALL SELECT '', '', '', SUM(Profits) FROM Sales;
The approach shown in the SQL above has two shortcomings compared with the ROLLUP operator. First, the syntax is complex, requiring more effort to generate and understand. Second, and more importantly, query execution is inefficient because the optimizer receives no guidance about the user's overall goal. Each of the four SELECT statements above causes table access even though all the needed subtotals could be gathered with a single pass. The ROLLUP extension makes the desired result explicit and gathers its results with just one table access.
The more columns used in a ROLLUP clause, the greater the savings compared to the UNION ALL approach. For instance, if a four-column ROLLUP replaces a UNION of five SELECT statements, the reduction in table access is four-fifths or 80%.
Some data access tools calculate subtotals on the client side and thereby avoid the multiple SELECT statements described above. While this approach can work, it places significant loads on the computing environment. For large reports, the client must have substantial memory and processing power to handle the subtotaling tasks. Even if the client has the necessary resources, a heavy processing burden for subtotal calculations may slow down the client in its performance of other activities.
Use the ROLLUP extension in tasks involving subtotals.
The subtotals created by ROLLUP represent only a fraction of possible subtotal combinations. For instance, in the cross-tabulation shown in Table 17-1, the departmental totals across regions (279,000 and 319,000) would not be calculated by a ROLLUP(Time, Region, Department) clause. To generate those numbers would require a ROLLUP clause with the grouping columns specified in a different order: ROLLUP(Time, Department, Region). The easiest way to generate the full set of subtotals needed for cross-tabular reports such as those needed for Table 17-1 is to use the CUBE extension.
CUBE enables a SELECT statement to calculate subtotals for all possible combinations of a group of dimensions. It also calculates a grand total. This is the set of information typically needed for all cross-tabular reports, so CUBE can calculate a cross-tabular report with a single SELECT statement. Like ROLLUP, CUBE is a simple extension to the GROUP BY clause, and its syntax is also easy to learn.
CUBE appears in the GROUP BY clause in a SELECT statement. Its form is:
SELECT ... GROUP BY CUBE (grouping_column_reference_list)
CUBE takes a specified set of grouping columns and creates subtotals for all possible combinations of them. In terms of multi-dimensional analysis, CUBE generates all the subtotals that could be calculated for a data cube with the specified dimensions. If you have specified CUBE(Time, Region, Department), the result set will include all the values that would be included in an equivalent ROLLUP statement plus additional combinations. For instance, in Table 17-1, the departmental totals across regions (279,000 and 319,000) would not be calculated by a ROLLUP(Time, Region, Department) clause, but they would be calculated by a CUBE(Time, Region, Department) clause. If n columns are specified for a CUBE, there will be 2n combinations of subtotals returned. Output 15-3 gives an example of a three-dimension CUBE.
This example of CUBE uses the data in the video store database.
SELECT Time, Region, Department, SUM(Profit) AS Profit FROM sales GROUP BY CUBE (Time, Region, Dept);
Output 15-3 shows the results of this query.
CUBE Aggregation across Three Dimensions
Time Region Department Profit ---- ------ ---------- ------ 1996 Central VideoRental 75,000 1996 Central VideoSales 74,000 1996 Central NULL 149,000 1996 East VideoRental 89,000 1996 East VideoSales 115,000 1996 East NULL 204,000 1996 West VideoRental 87,000 1996 West VideoSales 86,000 1996 West NULL 173,000 1996 NULL VideoRental 251,000 1996 NULL VideoSales 275,000 1996 NULL NULL 526,000 1997 Central VideoRental 82,000 1997 Central VideoSales 85,000 1997 Central NULL 167,000 1997 East VideoRental 101,000 1997 East VideoSales 137,000 1997 East NULL 238,000 1997 West VideoRental 96,000 1997 West VideoSales 97,000 1997 West NULL 193,000 1997 NULL VideoRental 279,000 1997 NULL VideoSales 319,000 1997 NULL NULL 598,000 NULL Central VideoRental 157,000 NULL Central VideoSales 159,000 NULL Central NULL 316,000 NULL East VideoRental 190,000 NULL East VideoSales 252,000 NULL East NULL 442,000 NULL West VideoRental 183,000 NULL West VideoSales 183,000 NULL West NULL 366,000 NULL NULL VideoRental 530,000 NULL NULL VideoSales 594,000 NULL NULL NULL 1,124,000
Partial cube resembles partial rollup in that you can limit it to certain dimensions. In this case, subtotals of all possible combinations are limited to the dimensions within the cube list (in parentheses).
GROUP BY expr1, CUBE(expr2, expr3)
The above syntax example calculates 2*2, or 4, subtotals. That is:
Using the video store database, we can issue the following statement:
SELECT Time, Region, Department, SUM(Profit) AS Profit FROM sales GROUP BY Time CUBE(Region, Dept);
Output 15-4 shows the results of this query.
Partial CUBE
Time Region Department Profit ---- ------ ---------- ------ 1996 Central VideoRental 75,000 1996 Central VideoSales 74,000 1996 Central NULL 149,000 1996 East VideoRental 89,000 1996 East VideoSales 115,000 1996 East NULL 204,000 1996 West VideoRental 87,000 1996 West VideoSales 86,000 1996 West NULL 173,000 1996 NULL VideoRental 251,000 1996 NULL VideoSales 275,000 1996 NULL NULL 526,000 1997 Central VideoRental 82,000 1997 Central VideoSales 85,000 1997 Central NULL 167,000 1997 East VideoRental 101,000 1997 East VideoSales 137,000 1997 East NULL 238,000 1997 West VideoRental 96,000 1997 West VideoSales 97,000 1997 West NULL 193,000 1997 NULL VideoRental 279,000 1997 NULL VideoSales 319,000 1997 NULL NULL 598,000
Just as for ROLLUP, multiple SELECT statements combined with UNION ALL statements could provide the same information gathered through CUBE. However, this might require many SELECT statements. For an n-dimensional cube, 2n SELECT statements are needed. In our three-dimension example, this would mean issuing eight SELECTS linked with UNION ALL.
Consider the impact of adding just one more dimension when calculating all possible combinations: the number of SELECT statements would double to 16. The more columns used in a CUBE clause, the greater the savings compared to the UNION ALL approach. For instance, if a four-column CUBE replaces UNION ALL of 16 SELECT statements, the reduction in table access is fifteen-sixteenths or 93.75%.
The examples in this chapter show ROLLUP and CUBE used with the SUM() function. While this is the most common type of aggregation, these extensions can also be used with all other functions available to the GROUP BY clause, for example, COUNT, AVG, MIN, MAX, STDDEV, and VARIANCE. COUNT, which is often needed in cross-tabular analyses, is likely to be the second most helpful function.
Two challenges arise with the use of ROLLUP and CUBE. First, how can we programmatically determine which result set rows are subtotals, and how do we find the exact level of aggregation of a given subtotal? We will often need to use subtotals in calculations such as percent-of-totals, so we need an easy way to determine which rows are the subtotals we seek. Second, what happens if query results contain both stored NULL values and "NULL" values created by a ROLLUP or CUBE? How does an application or developer differentiate between the two?
To handle these issues, Oracle 8i provides a function called GROUPING. Using a single column as its argument, GROUPING returns 1 when it encounters a NULL value created by a ROLLUP or CUBE operation. That is, if the NULL indicates the row is a subtotal, GROUPING returns a 1. Any other type of value, including a stored NULL, returns a 0.
GROUPING appears in the selection list portion of a SELECT statement. Its form is:
SELECT ... [GROUPING(dimension_column)...] ... GROUP BY ... {CUBE | ROLLUP} (dimension_column)
This example uses GROUPING to create a set of mask columns for the result set shown in Output 15-3. The mask columns are easy to analyze programmatically.
SELECT Time, Region, Department, SUM(Profit) AS Profit, GROUPING (Time) as T, GROUPING (Region) as R, GROUPING (Department) as D FROM Sales GROUP BY ROLLUP (Time, Region, Department);
Output 15-5 shows the results of this query.
Use of GROUPING Function:
Time Region Department Profit T R D ---- ------ ---------- ------ - - - 1996 Central VideoRental 75,000 0 0 0 1996 Central VideoSales 74,000 0 0 0 1996 Central NULL 149,000 0 0 1 1996 East VideoRental 89,000 0 0 0 1996 East VideoSales 115,000 0 0 0 1996 East NULL 204,000 0 0 1 1996 West VideoRental 87,000 0 0 0 1996 West VideoSales 86,000 0 0 0 1996 West NULL 173,000 0 0 1 1996 NULL NULL 526,000 0 1 1 1997 Central VideoRental 82,000 0 0 0 1997 Central VideoSales 85,000 0 0 0 1997 Central NULL 167,000 0 0 1 1997 East VideoRental 101,000 0 0 0 1997 East VideoSales 137,000 0 0 0 1997 East NULL 238,000 0 0 1 1997 West VideoRental 96,000 0 0 0 1997 West VideoSales 97,000 0 0 0 1997 West NULL 193,000 0 0 1 1997 NULL VideoRental 598,000 0 1 1 NULL NULL NULL 1,124,000 1 1 1
A program can easily identify the detail rows above by a mask of "0 0 0" on the T, R, and D columns. The first level subtotal rows have a mask of "0 0 1", the second level subtotal rows have a mask of "0 1 1", and the overall total row has a mask of "1 1 1".
Output 15-6 shows an ambiguous result set created using the CUBE extension.
Distinguishing Aggregate NULL from Stored NULL Value:
Time Region Profit ---- ------ ------ 1996 East 200,000 1996 NULL 200,000 NULL East 200,000 NULL NULL 190,000 NULL NULL 190,000 NULL NULL 190,000 NULL NULL 390,000
In this case, four different rows show NULL for both Time and Region. Some of those NULLs must represent aggregates due to the CUBE extension, and others must be NULLs stored in the database. How can we tell which is which? GROUPING functions, combined with the NVL and DECODE functions, resolve the ambiguity so that human readers can easily interpret the values.
We can resolve the ambiguity by using the GROUPING and other functions in the code below.
SELECT decode(grouping(Time), 1, 'All Times', Time) AS Time, decode(grouping(region), 1, 'All Regions', 0, null)) AS Region, sum(Profit) AS Profit FROM Sales group by CUBE(Time, Region);
This code generates the result set in Output 15-7. These results include text values clarifying which rows have aggregations.
Grouping Function used to Differentiate Aggregate-based "NULL" from Stored NULL Values.
Time Region Profit ---- ------ ------ 1996 East 200,000 1996 All Regions 200,000 All Times East 200,000 NULL NULL 190,000 NULL All Regions 190,000 All Times NULL 190,000 All Times All Regions 390,000
To explain the SQL statement above, we will examine its first column specification, which handles the Time column. Look at the first line of the SQL code above, namely,
decode(grouping(Time), 1, 'All Times', Time) as Time,
The Time value is determined with a DECODE function that contains a GROUPING function. The GROUPING function returns a 1 if a row value is an aggregate created by ROLLUP or CUBE, otherwise it returns a 0. The DECODE function then operates on the GROUPING function's results. It returns the text "All Times" if it receives a 1 and the time value from the database if it receives a 0. Values from the database will be either a real value such as 1996 or a stored NULL. The second column specification, displaying Region, works the same way.
The GROUPING function is not only useful for identifying NULLs, it also enables sorting subtotal rows and filtering results. In the next example (Output 15-8), we retrieve a subset of the subtotals created by a CUBE and none of the base-level aggregations. The HAVING clause constrains columns which use GROUPING functions.
SELECT Time, Region, Department, SUM(Profit) AS Profit, GROUPING (Time) AS T, GROUPING (Region) AS R, GROUPING (Department) AS D FROM Sales GROUP BY CUBE (Time, Region, Department) HAVING (GROUPING(Department)=1 AND GROUPING(Region)=1 AND GROUPING(Time)=1) OR (GROUPING(Region)=1 AND (GROUPING(Department)=1) OR (GROUPING(Time)=1 AND GROUPING(department)=1);
Output 15-8 shows the results of this query.
Example of GROUPING Function Used to Filter Results to Subtotals and Grand Total:
Time Region Department Profit ---- ------ ---------- ------ 1996 NULL NULL 526,000 1997 NULL NULL 598,000 NULL Central NULL 316,000 NULL East NULL 442,000 NULL West NULL 366,000 NULL NULL NULL 1,124,000
Compare the result set of Output 15-8 with that in Output 15-3 to see how Output 15-8 is a precisely specified group: it contains only the yearly totals, regional totals aggregated over time and department, and the grand total.
This section discusses the following topics.
The ROLLUP and CUBE extensions work independently of any hierarchy metadata in your system. Their calculations are based entirely on the columns specified in the SELECT statement in which they appear. This approach enables CUBE and ROLLUP to be used whether or not hierarchy metadata is available. The simplest way to handle levels in hierarchical dimensions is by using the ROLLUP extension and indicating levels explicitly through separate columns. The code below shows a simple example of this with months rolled up to quarters and quarters rolled up to years.
SELECT Year, Quarter, Month, SUM(Profit) AS Profit FROM sales GROUP BY ROLLUP(Year, Quarter, Month)
This query returns the rows in Output 15-9.
Example of ROLLUP across Time Levels:
Year Quarter Month Profit ---- ------- ----- ------ 1997 Winter January 55,000 1997 Winter February 64,000 1997 Winter March 71,000 1997 Winter NULL 190,000 1997 Spring April 75,000 1997 Spring May 86,000 1997 Spring June 88,000 1997 Spring NULL 249,000 1997 Summer July 91,000 1997 Summer August 87,000 1997 Summer September 101,000 1997 Summer NULL 279,000 1997 Fall October 109,000 1997 Fall November 114,000 1997 Fall December 133,000 1997 Fall NULL 356,000 1997 NULL NULL 1,074,000
CUBE and ROLLUP do not restrict the GROUP BY clause column capacity. The GROUP BY clause, with or without the extensions, can work with up to 255 columns. However, the combinatorial explosion of CUBE makes it unwise to specify a large number of columns with the CUBE extension. Consider that a 20-column list for CUBE would create 220 combinations in the result set. A very large CUBE list could strain system resources, so any such query needs to be tested carefully for performance and the load it places on the system.
The HAVING clause of SELECT statements is unaffected by the use of ROLLUP and CUBE. Note that the conditions specified in the HAVING clause apply to both the subtotal and non-subtotal rows of the result set. In some cases a query may need to exclude the subtotal rows or the non-subtotal rows from the HAVING clause. This can be achieved by using the GROUPING function together with the HAVING clause. See Output 15-8 and its associated SQL for an example.
The ORDER BY clause of a SELECT statement is unaffected by the use of ROLLUP and CUBE. Note that the conditions specified in the ORDER BY clause apply to both subtotal and non-subtotal rows of the result set. In some cases, a query may need to order the rows in a certain way. This can be achieved by using a grouping function in the ORDER BY clause.
The SQL language, while extremely capable in many areas, has never provided strong support for analytic tasks. Basic business intelligence calculations such as moving averages, rankings, and lead/lag comparisons have required extensive programming outside of standard SQL, often with performance problems. Oracle8i now provides a new set of functions which address this longstanding need. These functions are referred to as analytic functions because they are useful in all types of analyses. The analytic functions improve performance. In addition, the functions are now under review by ANSI for addition to the SQL standard during 2000.
Analytic functions are classified in the following categories:
They are used as follows:
To perform these operations, the analytic functions add several new elements to SQL processing. These elements build on existing SQL to allow flexible and powerful calculation expressions. The processing flow is represented in Figure 17-2.

Here are the essential concepts used in the analytic functions:
A window can be set as large as all the rows in a partition. On the other hand, it could be just a sliding window of 1 row within a partition.

A ranking function computes the rank of a record with respect to other records in the dataset based on the values of a set of measures. The types of ranking function are:
The RANK and DENSE_RANK functions allow you to rank items in a group, for example, finding the top 3 products sold in California last year. There are two functions that perform ranking, as shown by the following syntax:
RANK() OVER ( [PARTITION BY <value expression1> [, ...]] ORDER BY <value expression2> [collate clause] [ASC|DESC] [NULLS FIRST|NULLS LAST] [, ...] ) DENSE_RANK() OVER ( [PARTITION BY <value expression1> [, ...]] ORDER BY <value expression2> [collate clause] [ASC|DESC] [NULLS FIRST|NULLS LAST] [, ...] )
The difference between RANK and DENSE_RANK is that DENSE_RANK leaves no gaps in ranking sequence when there are ties. That is, if we were ranking a competition using DENSE_RANK and had three people tie for second place, we would say that all three were in second place and that the next person came in third. The RANK function would also give three people in second place, but the next person would be in fifth place.
Some relevant points about RANK:
The following example shows how the [ASC | DESC] option changes the ranking order.
SELECT s_productkey, s_amount, RANK() OVER (ORDER BY s_amount) AS default_rank, RANK() OVER (ORDER BY s_amount DESC NULLS LAST) AS custom_rank FROM sales;
This statement gives:
S_PRODUCTKEY S_AMOUNT DEFAULT_RANK CUSTOM_RANK ------------ -------- ------------ ----------- SHOES 130 6 1 JACKETS 95 5 2 SWEATERS 80 4 3 SHIRTS 75 3 4 PANTS 60 2 5 TIES 45 1 6
Note: While the data in this result is ordered on the measure s_amount, in general, it is not guaranteed by the RANK function that the data will be sorted on the measures. If you want the data to be sorted on s_amount in your result, you must specify it explicitly with an ORDER BY clause, at the end of the SELECT statement.
Ranking functions need to resolve ties between values in the set. If the first expression cannot resolve ties, the second expression is used to resolve ties and so on. For example, to rank products based on their dollar sales within each region, breaking ties with the profits, we would say:
SELECT r_regionkey, p_productkey, s_amount, s_profit, RANK() OVER (ORDER BY s_amount DESC, s_profit DESC) AS rank_in_east FROM region, product, sales WHERE r_regionkey = s_regionkey AND p_productkey = s_productkey AND r_regionkey = 'east';
The result would be:
R_REGIONKEY S_PRODUCTKEY S_AMOUNT S_PROFIT RANK_IN_EAST ----------- ------------ -------- -------- ------------ EAST SHOES 130 30 1 EAST JACKETS 100 28 2 EAST PANTS 100 24 3 EAST SWEATERS 75 24 4 EAST SHIRTS 75 24 4 EAST TIES 60 12 6 EAST T-SHIRTS 20 10 7
For jackets and pants, the s_profit column resolves the tie in the s_amount column. But for sweaters and shirts, s_profit cannot resolve the tie in s_amount column. Hence, they are given the same rank.
The difference between RANK() and DENSE_RANK() functions is illustrated below:
SELECT s_productkey, SUM(s_amount) as sum_s_amount, RANK() OVER (ORDER BY SUM(s_amount) DESC) AS rank_all, DENSE_RANK() OVER (ORDER BY SUM(s_amount) DESC) AS rank_dense FROM sales GROUP BY s_productkey;
This statement produces this result:
S_PRODUCTKEY SUM_S_AMOUNT RANK_ALL RANK_DENSE ------------ ------------ -------- ---------- SHOES 100 1 1 JACKETS 100 1 1 SHIRTS 89 3 2 SWEATERS 75 4 3 SHIRTS 75 4 3 TIES 66 6 4 PANTS 66 6 4
Note that, in the case of DENSE_RANK(), the largest rank value gives the number of distinct values in the dataset.
The RANK function can be made to operate within groups, that is, the rank gets reset whenever the group changes. This is accomplished with the PARTITION BY option. The group expressions in the PARTITION BY subclause divide the dataset into groups within which RANK operates. For example, to rank products within each region by their dollar sales, we say:
SELECT r_regionkey, p_productkey, SUM(s_amount), RANK() OVER (PARTITION BY r_regionkey ORDER BY SUM(s_amount) DESC) AS rank_of_product_per_region FROM product, region, sales WHERE r_regionkey = s_regionkey AND p_productkey = s_productkey GROUP BY r_regionkey, p_productkey;
A single query block can contain more than one ranking function, each partitioning the data into different groups (that is, reset on different boundaries). The groups can be mutually exclusive. The following query ranks products based on their dollar sales within each region (rank_of_product_per_region) and over all regions (rank_of_product_total).
SELECT r_regionkey, p_productkey, SUM(s_amount) AS SUM_S_AMOUNT, RANK() OVER (PARTITION BY r_regionkey ORDER BY SUM(s_amount) DESC) AS rank_of_product_per_region, RANK() OVER (ORDER BY SUM(s_amount) DESC) AS rank_of_product_total FROM product, region, sales WHERE r_regionkey = s_regionkey AND p_productkey = s_productkey GROUP BY r_regionkey, p_productkey ORDER BY r_regionkey;
The query produces this result:
R_REGIONKEY P_PRODUCTKEY SUM_S_AMOUNT RANK_OF_PRODUCT_PER_REGION RANK_OF_PRODUCT_TOTAL ----------- ------------ ------------ -------------------------- --------------------- EAST SHOES 130 1 1 EAST JACKETS 95 2 4 EAST SHIRTS 80 3 6 EAST SWEATERS 75 4 7 EAST T-SHIRTS 60 5 11 EAST TIES 50 6 12 EAST PANTS 20 7 14 WEST SHOES 100 1 2 WEST JACKETS 99 2 3 WEST T-SHIRTS 89 3 5 WEST SWEATERS 75 4 7 WEST SHIRTS 75 4 7 WEST TIES 66 6 10 WEST PANTS 45 7 13
Analytic functions, RANK for example, can be reset based on the groupings provided by a CUBE or ROLLUP operator.
It is useful to assign ranks to the groups created by CUBE and ROLLUP queries. See the CUBE/ROLLUP section, which includes information about the GROUPING function for further details. A sample query is:
SELECT r_regionkey, p_productkey, SUM(s_amount) AS SUM_S_AMOUNT, RANK() OVER (PARTITION BY GROUPING(r_regionkey), GROUPING(p_productkey) ORDER BY SUM(s_amount) DESC) AS rank_per_cube FROM product, region, sales WHERE r_regionkey = s_regionkey AND p_productkey = s_productkey GROUP BY CUBE(r_regionkey, p_productkey) ORDER BY GROUPING(r_regionkey), GROUPING(p_productkey), r_regionkey;
It produces this result:
R_REGIONKEY P_PRODUCTKEY SUM_S_AMOUNT RANK_PER_CUBE ----------- ------------ ------------ ------------- EAST SHOES 130 1 EAST JACKETS 50 12 EAST SHIRTS 80 6 EAST SWEATERS 75 7 EAST T-SHIRTS 60 11 EAST TIES 95 4 EAST PANTS 20 14 WEST SHOES 100 2 WEST JACKETS 99 3 WEST SHIRTS 89 5 WEST SWEATERS 75 7 WEST T-SHIRTS 75 7 WEST TIES 66 10 WEST PANTS 45 13 EAST NULL 510 2 WEST NULL 549 1 NULL SHOES 230 1 NULL JACKETS 149 5 NULL SHIRTS 169 2 NULL SWEATERS 150 4 NULL T-SHIRTS 135 6 NULL TIES 161 3 NULL PANTS 65 7 NULL NULL 1059 1
NULLs are treated like normal values. Also, for the purpose of rank computation, a NULL value is assumed to be equal to another NULL value. Depending on the ASC | DESC options provided for measures and the NULLS FIRST | NULLS LAST option, NULLs will either sort low or high and hence, are given ranks appropriately. The following example shows how NULLs are ranked in different cases:
SELECT s_productkey, s_amount, RANK() OVER (ORDER BY s_amount ASC NULLS FIRST) AS rank1, RANK() OVER (ORDER BY s_amount ASC NULLS LAST) AS rank2, RANK() OVER (ORDER BY s_amount DESC NULLS FIRST) AS rank3, RANK() OVER (ORDER BY s_amount DESC NULLS LAST) AS rank4 FROM sales;
The query gives the result:
S_PRODUCTKEY S_AMOUNT RANK1 RANK2 RANK3 RANK4 ------------ -------- ----- ----- ---- ----- SHOES 100 6 4 3 1 JACKETS 100 6 4 3 1 SHIRTS 89 5 3 5 3 SWEATERS 75 3 1 6 4 T-SHIRTS 75 3 1 6 4 TIES NULL 1 6 1 6 PANTS NULL 1 6 1 6
If the value for two rows is NULL, the next group expression is used to resolve the tie. If they cannot be resolved even then, the next expression is used and so on till the tie is resolved or else the two rows are given the same rank. For example:
SELECT s_productkey, s_amount, s_quantity, s_profit, RANK() OVER (ORDER BY s_amount NULLS LAST, s_quantity NULLS LAST, s_profit NULLS LAST) AS rank_of_product FROM sales;
would give the result:
S_PRODUCTKEY S_AMOUNT S_QUANTITY S_PROFIT RANK_OF_PRODUCT ------------ -------- ---------- -------- --------------- SHOES 75 6 4 1 JACKETS 75 NULL 4 2 SWEAT-SHIRTS 96 NULL 6 3 SHIRTS 96 NULL 6 3 SWEATERS 100 NULL 1 5 T-SHIRTS 100 NULL 3 6 TIES NULL 1 2 7 PANTS NULL 1 NULL 8 HATS NULL 6 2 9 SOCKS NULL 6 2 9 SUITS NULL 6 NULL 10 JEANS NULL NULL NULL 11 BELTS NULL NULL NULL 11
You can easily obtain top N ranks by enclosing the RANK function in a subquery and then applying a filter condition outside the subquery. For example, to obtain the top four sales items per region, you can issue:
SELECT region, product, sum_s_amount FROM (SELECT r_regionkey AS region, p_ product_key AS product, SUM(s_amount) AS sum_s_amount, RANK() OVER(PARTITION BY r_region_key ORDER BY SUM(s_amount) DESC AS rank1, FROM product, region, sales WHERE r_region_key = s_region_key AND p_product_key = s_product_key GROUP BY r_region_key ORDER BY r_region_key) WHERE rank1 <= 4;
The query produces this result:
R_REGIONKEY P_PRODUCTKEY SUM_S_AMOUNT ----------- ------------ ------------ EAST SHOES 130 EAST JACKETS 95 EAST SHIRTS 80 EAST SWEATERS 75 WEST SHOES 100 WEST JACKETS 99 WEST T-SHIRTS 89 WEST SWEATERS 75 WEST SHIRTS 75
BOTTOM_N is similar to TOP_N except for the ordering sequence within the rank expression. In the previous example, you can order SUM(s_amount) ASC instead of DESC.
The CUME_DIST function (defined as the inverse of percentile in some statistical books) computes the position of a specified value relative to a set of values. The order can be ascending or descending. Ascending is the default. The range of values for CUME_DIST is from greater than 0 to 1. To compute the CUME_DIST of a value x in a set S of size N, we use the formula:
CUME_DIST(x) = number of values (different from, or equal to, x) in S coming before x in the specified order/ N
Its syntax is:
CUME_DIST() OVER ([PARTITION BY <value expression1> [, ...]] ORDER BY <value expression2> [collate clause] [ASC|DESC] [NULLS FIRST | NULLS LAST] [, ...])
The semantics of various options in the CUME_DIST function are similar to those in the RANK function. The default order is ascending, implying that the lowest value gets the lowest cume_dist (as all other values come later than this value in the order). NULLS are treated the same as they are in the RANK function. They are counted towards both the numerator and the denominator as they are treated like non-NULL values. To assign cume_dists to products per region based on their sales and profits, we would say:
SELECT r_regionkey, p_productkey, SUM(s_amount) AS SUM_S_AMOUNT, CUME_DIST() OVER (PARTITION BY r_regionkey ORDER BY SUM(s_amount)) AS cume_dist_per_region FROM region, product, sales WHERE r_regionkey = s_regionkey AND p_productkey = s_productkey GROUP BY r_regionkey, p_productkey ORDER BY r_regionkey, s_amount DESC;
It will produce this result:
R_REGIONKEY P_PRODUCTKEY SUM_S_AMOUNT CUME_DIST_PER_REGION ----------- ------------ ------------ -------------------- EAST SHOES 130 1.00 EAST JACKETS 95 .84 EAST SHIRTS 80 .70 EAST SWEATERS 75 .56 EAST T-SHIRTS 60 .42 EAST TIES 50 .28 EAST PANTS 20 .14 WEST SHOES 100 1.00 WEST JACKETS 99 .84 WEST T-SHIRTS 89 .70 WEST SWEATERS 75 .56 WEST SHIRTS 75 .28 WEST TIES 66 .28 WEST PANTS 45 .14
PERCENT_RANK is very similar to CUME_DIST, but it uses rank values rather than row counts in its numerator. Therefore, it returns the percent rank of a value relative to a group of values. The function is available in many popular spreadsheets. PERCENT_RANK of a row is calculated as:
(rank of row in its partition - 1) / (number of rows in the partition - 1)
PERCENT_RANK returns values in the range zero to one. The first row will have a PERCENT_RANK of zero.
Its syntax is:
PERCENT_RANK() OVER ([PARTITION BY <value expression1> [, ...]] ORDER BY <value expression2> [collate clause] [ASC|DESC] [NULLS FIRST | NULLS LAST] [, ...])
NTILE allows easy calculation of tertiles, quartiles, deciles and other common summary statistics. This function divides an ordered partition into a specified number of groups called buckets and assigns a bucket number to each row in the partition. NTILE is a very useful calculation since it lets users divide a data set into fourths, thirds, and other groupings.
The buckets are calculated so that each bucket has exactly the same number of rows assigned to it or at most 1 row more than the others. For instance, if we have 100 rows in a partition and ask for an NTILE function with four buckets, 25 rows will be assigned a value of 1, 25 rows will have value 2, and so on.
If the number of rows in the partition does not divide evenly (without a remainder) into the number of buckets, then the number of rows assigned per bucket will differ by one at most. The extra rows will be distributed one per bucket starting from the lowest bucket number. For instance, if there are 103 rows in a partition which has an NTILE(5) function, the first 21 rows will be in the first bucket, the next 21 in the second bucket, the next 21 in the third bucket, the next 20 in the fourth bucket and the final 20 in the fifth bucket.
The NTile function has the following syntax:
NTILE(N) OVER ([PARTITION BY <value expression1> [, ...]] ORDER BY <value expression2> [collate clause] [ASC|DESC] [NULLS FIRST | NULLS LAST] [, ...])
where the N in NTILE(N) can be a constant (e.g., 5) or an expression. The expression can include expressions in the PARTITION BY clause. For example, (5*2) or (5*c1) OVER (PARTITION BT c1)).
This function, like RANK and CUME_DIST, has a PARTITION BY clause for per group computation, an ORDER BY clause for specifying the measures and their sort order, and NULLS FIRST | NULLS LAST clause for the specific treatment of NULLs. For example,
SELECT p_productkey, s_amount, NTILE(4) (ORDER BY s_amount DESC NULLS FIRST) AS 4_tile FROM product, sales WHERE p_productkey = s_productkey;
This query would give:
P_PRODUCTKEY S_AMOUNT 4_TILE ------------ -------- ------ SUITS NULL 1 SHOES 100 1 JACKETS 90 1 SHIRTS 89 2 T-SHIRTS 84 2 SWEATERS 75 2 JEANS 75 3 TIES 75 3 PANTS 69 3 BELTS 56 4 SOCKS 45 4
NTILE is a nondeterministic function. Equal values can get distributed across adjacent buckets (75 is assigned to buckets 2 and 3) and buckets '1', '2' and '3' have 3 elements - one more than the size of bucket '4'. In the above table, "JEANS" could as well be assigned to bucket 2 (instead of 3) and "SWEATERS" to bucket 3 (instead of 2), because there is no ordering on the p_PRODUCT_KEY column. To ensure deterministic results, you must order on a unique key.
The ROW_NUMBER function assigns a unique number (sequentially, starting from 1, as defined by ORDER BY) to each row within the partition. It has the following syntax:
ROW_NUMBER() OVER ([PARTITION BY <value expression1> [, ...]] ORDER BY <value expression2> [collate clause] [ASC|DESC] [NULLS FIRST | NULLS LAST] [, ...])
As an example, consider this query:
SELECT p_productkey, s_amount, ROW_NUMBER() (ORDER BY s_amount DESC NULLS LAST) AS srnum FROM product, sales WHERE p_productkey = s_productkey;
It would give:
P_PRODUCTKEY S_AMOUNT SRNUM ------------ -------- ----- SHOES 100 1 JACKETS 90 2 SHIRTS 89 3 T-SHIRTS 84 4 SWEATERS 75 5 JEANS 75 6 TIES 75 7 PANTS 69 8 BELTS 56 9 SOCKS 45 10 SUITS NULL 11
Sweaters, jeans and ties each with s_amount of 75 are assigned different row number (5, 6, 7). Like NTILE, ROW_NUMBER is a non-deterministic function, so "SWEATERS" could as well be assigned a rownumber of 7 (instead of 5) and "TIES" a rownumber of 5 (instead of 7). To ensure deterministic results, you must order on a unique key.
Windowing functions can be used to compute cumulative, moving, and centered aggregates. They return a value for each row in the table, which depends on other rows in the corresponding window. These functions include moving sum, moving average, moving min/max, cumulative sum, as well as statistical functions. They can be used only in the SELECT and ORDER BY clauses of the query. Two other functions are available: FIRST_VALUE, which returns the first value in the window; and LAST_VALUE, which returns the last value in the window. These functions provide access to more than one row of a table without a self-join. The syntax of the windowing functions is:
{SUM|AVG|MAX|MIN|COUNT|STDDEV|VARIANCE|FIRST_VALUE|LAST_VALUE} ({<value expression1> | *}) OVER ([PARTITION BY <value expression2>[,...]] ORDER BY <value expression3> [collate clause>] [ASC| DESC] [NULLS FIRST | NULLS LAST] [,...] ROWS | RANGE {{UNBOUNDED PRECEDING | <value expression4> PRECEDING} | BETWEEN {UNBOUNDED PRECEDING | <value expression4> PRECEDING} AND{CURRENT ROW | <value expression4> FOLLOWING}}
where:
Window functions' NULL semantics match the NULL semantics for SQL aggregate functions. Other semantics can be obtained by user-defined functions, or by using the DECODE or a CASE expression within the window function.
A logical offset can be specified with constants such as "RANGE 10 PRECEDING", or an expression that evaluates to a constant, or by an interval specification like "RANGE INTERVAL N DAYS/MONTHS/YEARS PRECEDING" or an expression that evaluates to an interval. With logical offset, there can only be one expression in the ORDER BY expression list in the function, with type compatible to NUMERIC if offset is numeric, or DATE if an interval is specified.
Some examples of windowing functions follow:
The following is an example of a cumulative balance per account ordered by deposit date.
SELECT Acct_number, Trans_date, Trans_amount, SUM(Trans_amount) OVER (PARTITION BY Acct_number ORDER BY Trans_date ROWS UNBOUNDED PRECEDING) AS Balance FROM Ledger ORDER BY Acct_number, Trans_date; Acct_number Trans_date Trans_amount Balance ----------- ---------- ------------ ------- 73829 1998-11-01 113.45 113.45 73829 1998-11-05 -52.01 61.44 73829 1998-11-13 36.25 97.69 82930 1998-11-01 10.56 10.56 82930 1998-11-21 32.55 43.11 82930 1998-11-29 -5.02 38.09
In this example, the analytic function SUM defines, for each row, a window that starts at the beginning of the partition(UNBOUNDED PRECEDING) and ends, by default, at the current row.
Here is an example of a time-based window that shows, for each transaction, the moving average of transaction amount for the preceding 7 days of transactions:
SELECT Account_number, Trans_date, Trans_amount, AVG (Trans_amount) OVER (PARTITION BY Account_number ORDER BY Trans_date RANGE INTERVAL '7' DAY PRECEDING) AS mavg_7day FROM Ledger; Acct_number Trans_date Trans_amount mavg_7day ----------- ---------- ------------ --------- 73829 1998-11-03 113.45 113.45 73829 1998-11-09 -52.01 30.72 73829 1998-11-13 36.25 -7.88 73829 1998-11-14 10.56 -1.73 73829 1998-11-20 32.55 26.45 82930 1998-11-01 100.25 100.25 82930 1998-11-10 10.01 10.01 82930 1998-11-25 11.02 11.02 82930 1998-11-26 100.56 55.79 82930 1998-11-30 -5.02 35.52
Calculating windowing aggregate functions centered around the current row is straightforward. This example computes for each account a centered moving average of the transaction amount for the 1 month preceding the current row and 1 month following the current row including the current row as well.
SELECT Account_number, Trans_date, Trans_amount, AVG (Trans_amount) OVER (PARTITION BY Account_number ORDER BY Trans_date RANGE BETWEEN INTERVAL '1' MONTH PRECEDING AND INTERVAL '1' MONTH FOLLOWING) as c_avg FROM Ledger;
The following example illustrates how window aggregate functions compute values in the presence of duplicates.
SELECT r_rkey, p_pkey, s_amt SUM(s_amt) OVER (ORDER BY p_pkey RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) AS current_group_sum FROM product, region, sales WHERE r_rkey = s_rkey AND p_pkey = s_pkey AND r_rkey = 'east' ORDER BY r_rkey, p_pkey; R_RKEY P_PKEY S_AMT CURRENT_GROUP_SUM /*Source numbers for the current_group_sum column*/ ------ ------ ----- ----------------- /*------- */ EAST 1 130 130 /* 130 */ EAST 2 50 180 /*130+50 */ EAST 3 80 265 /*50+(80+75+60) */ EAST 3 75 265 /*50+(80+75+60) */ EAST 3 60 265 /*50+(80+75+60) */ EAST 4 20 235 /*80+75+60+20 */
Values within parentheses indicate ties.
Let us consider the row with the output of "EAST, 3, 75" from the above table. In this case, all the other rows with p_pkey of 3 (ties) are considered to belong to one group. So, it should include itself (that is, 75) to the window and its ties (that is, 80, 60); hence the result 50 + (80 + 75 + 60). This is only true because you used RANGE rather than ROWS. It is important to note that the value returned by the window aggregate function with logical offsets is deterministic in all the cases. In fact, all the windowing functions (except FIRST_VALUE and LAST_VALUE) with logical offsets are deterministic.
Assume that you want to calculate the moving average of stock price over 3 working days. If the data is dense (that is, you have data for all working days) then you can use a physical window function. However, if there are holidays and no data is available for those days, here is how you can calculate moving average under those circumstances.
SELECT t_timekey, AVG(stock_price) OVER (ORDER BY t_timekey RANGE fn(t_timekey ) PRECEDING) av_price FROM stock, time WHERE st_timekey = t_timekey ORDER BY t_timekey;
Here, fn could be a PL/SQL function with the following specification:
fn(t_timekey) returns
If any of the previous days are holidays, it adjusts the count appropriately.
Note that, when window is specified using a number in a window function with ORDER BY on a date column, then it is implicitly the number of days. We could have also used the interval literal conversion function, as:
NUMTODSINTERVAL(fn(t_timekey), 'DAY')
instead of just
fn(t_timekey)
to mean the same thing.
For windows expressed in physical units (ROWS), the ordering expressions should be unique to produce deterministic results. For example, the query below is not deterministic since t_timekey is not unique.
SELECT t_timekey, s_amount, FIRST_VALUE(s_amount) OVER (ORDER BY t_timekey ROWS 1 PRECEDING) AS LAG_physical, SUM(s_amount) OVER (ORDER BY t_timekey ROWS 1 PRECEDING) AS MOVINGSUM, FROM sales, time WHERE sales.s_timekey = time.t_timekey ORDER BY t_timekey;
It can yield either of the following:
T_TIMEKEY S_AMOUNT LAG_PHYSICAL MOVINGSUM --------- -------- ----------- --------- 92-10-11 1 1 1 92-10-12 4 1 5 92-10-12 3 4 7 92-10-12 2 3 5 92-10-15 5 2 7 T_TIMEKEY S_AMOUNT LAG_PHYSICAL MOVINGSUM --------- -------- ----------- --------- 92-10-11 1 1 1 92-10-12 3 1 4 92-10-12 4 3 7 92-10-12 2 4 6 92-10-15 5 2 7
The FIRST_VALUE and LAST_VALUE functions help users derive full power and flexibility from the window aggregate functions. They allow queries to select the first and last rows from a window. These rows are specially valuable since they are often used as the baselines in calculations. For instance, with a partition holding sales data ordered by day, we might ask "How much was each day's sales compared to the first sales day (FIRST_VALUE) of the period?" Or we might wish to know, for a set of rows in increasing sales order, "What was the percentage size of each sale in the region compared to the largest sale (LAST_VALUE) in the region?"
After a query has been processed, aggregate values like the number of resulting rows or an average value in a column can be easily computed within a partition and made available to other reporting functions. Reporting aggregate functions return the same aggregate value for every row in a partition. Their behavior with respect to NULLs is the same as the SQL aggregate functions. Here is the syntax:
{SUM | AVG | MAX | MIN | COUNT | STDDEV | VARIANCE} ([ALL | DISTINCT] {<value expression1> | *}) OVER ([PARTITION BY <value expression2>[,...]])
where
Reporting functions can appear only in the SELECT clause or the ORDER BY clause. The major benefit of reporting functions is their ability to do multiple passes of data in a single query block. Queries such as "Count the number of salesmen with sales more than 10% of city sales" do not require joins between separate query blocks.
For example, consider the question "For each product, find the region in which it had maximum sales". The equivalent SQL query using the MAX reporting function would look like this:
SELECT s_productkey, s_regionkey, sum_s_amount FROM (SELECT s_productkey, s_regionkey, SUM(s_amount) AS sum_s_amount, MAX(SUM(s_amount)) OVER (PARTITION BY s_productkey) AS max_sum_s_amount FROM sales GROUP BY s_productkey, s_regionkey) WHERE sum_s_amount = max_sum_s_amount;
Given this aggregated (sales grouped by s_productkey and s_regionkey) data for the first three columns below, the reporting aggregate function MAX(SUM(s_amount)) returns:
S_PRODUCTKEY S_REGIONKEY SUM_S_AMOUNT MAX_SUM_S_AMOUNT ------------ ----------- ------------ ---------------- JACKETS WEST 99 99 JACKETS EAST 50 99 PANTS EAST 20 45 PANTS WEST 45 45 SHIRTS EAST 60 80 SHIRTS WEST 80 80 SHOES WEST 100 130 SHOES EAST 130 130 SWEATERS WEST 75 75 SWEATERS EAST 75 75 TIES EAST 95 95 TIES WEST 66 95
The outer query would return:
S_PRODUCTKEY S_REGIONKEY SUM_S_AMOUNT ------------ ----------- ------------ JACKETS WEST 99 PANTS WEST 45 SHIRTS WEST 80 SWEATERS WEST 75 SWEATERS EAST 75 SHOES EAST 130 TIES EAST 95
Here is an example of computing the top 10 items in sales within those product lines which contribute more than 10% within their product category. The first column is the key in each of the tables.
SELECT * FROM ( SELECT item_name, prod_line_name, prod_cat_name, SUM(sales) OVER (PARTITION BY prod_cat_table.cat_id) cat_sales, SUM(sales) OVER (PARTITION BY prod_line_table.line_id) line_sales, RANK(sales) OVER (PARTITION BY prod_line_table.line_id ORDER BY sales DESC NULLS LAST) rnk FROM item_table, prod_line_table, prod_cat_table WHERE item_table.line_id = prod_line_table.line_id AND prod_line_table.cat_id = prod_cat_table.cat_id ) WHERE line_sales > 0.1 * cat_sales AND rnk <= 10;
The RATIO_TO_REPORT function computes the ratio of a value to the sum of a set of values. If the expression value expression evaluates to NULL, RATIO_TO_REPORT also evaluates to NULL, but it is treated as zero for computing the sum of values for the denominator. Its syntax is:
RATIO_TO_REPORT (<value expression1>) OVER ([PARTITION BY <value expression2>[,...]])
where
To calculate RATIO_TO_REPORT of sales per product, we might use the following syntax:
SELECT s_productkey, SUM(s_amount) AS sum_s_amount, SUM(SUM(s_amount)) OVER () AS sum_total, RATIO_TO_REPORT(SUM(s_amount)) OVER () AS ratio_to_report FROM sales GROUP BY s_productkey;
with this result:
S_PRODUCTKEY SUM_S_AMOUNT SUM_TOTAL RATIO_TO_REPORT ------------ ------------ --------- --------------- SHOES 100 520 0.19 JACKETS 90 520 0.17 SHIRTS 80 520 0.15 SWEATERS 75 520 0.14 SHIRTS 75 520 0.14 TIES 10 520 0.01 PANTS 45 520 0.08 SOCKS 45 520 0.08
The LAG and LEAD functions are useful for comparing values in different time periods--for example, March 98 to March 99.
These functions provide access to more than one row of a table at the same time without a self-join. The LAG function provides access to a row at a given offset prior to the position and the LEAD function provides access to a row at a given offset after the current position.
The functions have the following syntax:
{LAG | LEAD} (<value expression1>, [<offset> [, <default>]]) OVER ([PARTITION BY <value expression2>[,...]] ORDER BY <value expression3> [collate clause>] [ASC | DESC] [NULLS FIRST | NULLS LAST] [,...])
<offset> is an optional parameter and defaults to 1. <default> is an optional parameter and is the value returned if the <offset> falls outside the bounds of the table or partition.
If column sales.s_amount contains values 1,2,3,..., then:
SELECT t_timekey, s_amount, LAG(s_amount,1) OVER (ORDER BY t_timekey) AS LAG_amount, LEAD(s_amount,1) OVER (ORDER BY t_timekey) AS LEAD_amount FROM sales, time WHERE sales.s_timekey = time.t_timekey ORDER BY t_timekey;
gives:
T_TIMEKEY S_AMOUNT LAG_AMOUNT LEAD_AMOUNT --------- -------- ---------- ----------- 99-10-11 1 NULL 2 99-10-12 2 1 3 99-10-13 3 2 4 99-10-14 4 4 5 99-10-15 5 2 NULL
Oracle has statistics functions you can use to compute covariance, correlation, and linear regression statistics. Each of these functions operates on an unordered set. They also can be used as windowing and reporting functions. They differ from the aggregate functions (such as AVG(x)) in that most of them take two arguments.
VAR_POP returns the population variance of a set of numbers after discarding the nulls in this set.
The argument is a number expression. The result is of type number and can be null.
For a given expression e, population variance of e is defined as:
(SUM(e*e) - SUM(e)*SUM(e)/COUNT(e))/COUNT(e)
If the function is applied to an empty set, the result is a null value.
VAR_SAMP returns the sample variance of a set of numbers after discarding the NULLs in this set.
The argument is a number expression. The result is of type NUMBER and can be null.
For a given expression e, the sample variance of e is defined as:
(SUM(e*e) - SUM(e)*SUM(e)/COUNT(e))/(COUNT(e)-1)
If the function is applied to an empty set or a set with a single element, the result is a null value.
The VAR_SAMP function is similar to the existing VARIANCE function. The only difference is when the function takes a single argument. In this case, VARIANCE returns 0 and VAR_SAMP returns NULL.
The STDDEV_POP and STDDEV_SAMP functions compute the population standard deviation and the sample standard deviation, respectively.
For both functions, the argument is a number expression. Population standard deviation is simply defined as the square root of population variance. Similarly, sample standard deviation is defined as the square root of sample variance.
COVAR_POP returns the population covariance of a set of number pairs.
Argument values e1 and e2 are number expressions. Oracle applies the function to the set of (e1, e2) pairs after eliminating all pairs for which either e1 or e2 is null. Then Oracle makes the following computation:
(SUM(e1 * e2) - SUM(e2) * SUM(e1) / n) / n
where n is the number of (e1, e2) pairs where neither e1 nor e2 is null.
The function returns a value of type NUMBER. If the function is applied to an empty set, it returns null.
COVAR_SAMP returns the sample variance of a set of number pairs.
Argument values e1 and e2 are number expressions. Oracle applies the function to the set of (e1, e2) pairs after eliminating all pairs for which either e1 or e2 is null. Then Oracle makes the following computation:
(SUM(e1*e2)-SUM(e1)*SUM(e2)/n)/(n-1)
where n is the number of (e1, e2) pairs where neither e1 nor e2 is null.
The function returns a value of type NUMBER.
The CORR function returns the coefficient of correlation of a set of number pairs. The argument values e1 and e2 are number expressions.
The datatype of the result is NUMBER and can be null. When not null, the result is between -1 and 1.
The function is applied to the set of (e1, e2) pairs after eliminating all the pairs for which either e1 or e2 is null. Then Oracle makes the following computation:
COVAR_POP(e1, e2)/(STDDEV_POP(e1)*STDDEV_POP(e2))
If the function is applied to an empty set, or if either STDDEV_POP(e1) or STDDEV_POP(e2) is equal to zero after null elimination, the result is a null value.
The regression functions support the fitting of an ordinary-least-squares regression line to a set of number pairs. You can use them as both aggregate functions or windowing or reporting functions.
The functions are:
Oracle applies the function to the set of (e1, e2) pairs after eliminating all pairs for which either of e1 or e2 is null. e1 is interpreted as a value of the dependent variable (a "y value"), and e2 is interpreted as a value of the independent variable (an "x value"). Both expressions must be numbers.
The regression functions are all computed simultaneously during a single pass through the data.
For further information regarding syntax and semantics, see Oracle8i SQL Reference.
REGR_COUNT returns the number of non-null number pairs used to fit the regression line. If applied to an empty set (or if there are no (e1, e2) pairs where neither of e1 or e2 is null), the function returns 0.
REGR_AVGY and REGR_AVGX compute the averages of the dependent variable and the independent variable of the regression line, respectively. REGR_AVGY computes the average of its first argument (e1) after eliminating (e1, e2) pairs where either of e1 or e2 is null. Similarly, REGR_AVGX computes the average of its second argument (e2) after null elimination. Both functions return NULL if applied to an empty set.
The REGR_SLOPE function computes the slope of the regression line fitted to non-null (e1, e2) pairs. For this, it makes the following computation after eliminating (e1, e2) pairs where either of e1 or e2 is null:
COVAR_POP(e1, e2) / VAR_POP(e2)
If VAR_POP(e2) is 0 (a vertical regression line), REGR_SLOPE returns NULL.
The REGR_INTERCEPT function computes the y-intercept of the regression line. For this, it makes the following computation:
REGR_AVGY(e1, e2) - REGR_SLOPE(e1, e2) * REGR_AVGX(e1, e2)
REGR_INTERCEPT returns NULL whenever slope or the regression averages are NULL.
The REGR_R2 function computes the coefficient of determination (also called "R-squared" or "goodness of fit") for the regression line. It computes and returns one of the following values after eliminating (e1, e2) pairs where either e1 or e2 is null:
when VAR_POP(e1) > 0 and VAR_POP(e2) > 0
when VAR_POP(e1) = 0 and VAR_POP(e2) > 0
otherwise
REGR_R2 returns values between 0 and 1 when the regression line is defined (slope of the line is not null), and it returns NULL otherwise.
REGR_SXX, REGR_SYY and REGR_SXY functions are used in computing various diagnostic statistics for regression analysis. After eliminating (e1, e2) pairs where either of e1 or e2 is null, these functions make the following computations:
REGR_SXX: REGR_COUNT(e1,e2) * VAR_POP(e2) REGR_SYY: REGR_COUNT(e1,e2) * VAR_POP(e1) REGR_SXY: REGR_COUNT(e1,e2) * COVAR_POP(e1, e2)
Some common diagnostic statistics that accompany linear regression analysis are given in Table 17-3, "Common Diagnostic Statistics and Their Expressions".
In this example, you can compute an ordinary-least-squares regression line that expresses the bonus of an employee as a linear function of the employee's salary. The values SLOPE, ICPT, RSQR are slope, intercept, and coefficient of determination of the regression line, respectively. The values AVGSAL and AVGBONUS are the average salary and average bonus, respectively, of the employees, and the (integer) value CNT is the number of employees in the department for whom both salary and bonus data are available. The remaining regression statistics are named SXX, SYY, and SXY.
Consider the following Employee table with 8 employees:
SELECT * FROM employee; EMPNO NAME DEPT SALARY BONUS HIREDATE ---------- ---------- ---------- ---------- ---------- --------- 45 SAM SALES 4500 500 20-SEP-97 52 MILES SALES 4300 450 01-FEB-98 41 CLAIRE SALES 5600 800 14-JUN-96 65 MOLLY SALES 3200 07-AUG-99 36 FRANK HARDWARE 6700 1150 01-MAY-95 58 DEREK HARDWARE 3000 350 20-JUL-98 25 DIANA HARDWARE 8200 1860 12-APR-94 54 BILL HARDWARE 6000 900 05-MAR-98 8 rows selected.
We can then calculate:
SELECT REGR_SLOPE(BONUS, SALARY) SLOPE, REGR_INTERCEPT(BONUS, SALARY) ICPT, REGR_R2(BONUS, SALARY) RSQR, REGR_COUNT(BONUS, SALARY) COUNT, REGR_AVGX(BONUS, SALARY) AVGSAL, REGR_AVGY(BONUS, SALARY) AVGBONUS, REGR_SXX(BONUS, SALARY) SXX, REGR_SXY(BONUS, SALARY) SXY, REGR_SYY(BONUS, SALARY) SXY FROM employee GROUP BY dept; SLOPE ICPT RSQR COUNT AVGSAL AVGBONUS SXX SXY SXY -------- -------- -------- ----- ------ --------- -------- ------- ---------- .2759379 -583.729 .9263144 4 5975 1065 14327500 3953500 1177700 .2704082 -714.626 .9998813 3 4800 583.33333 980000 265000 71666.6667
Oracle now supports searched CASE statements. CASE statements are similar in purpose to the Oracle DECODE statement, but they offer more flexibility and logical power. They are also easier to read than traditional DECODE statements, and offer better performance as well. They are commonly used when breaking categories into buckets like age (for example, 20-29, 30-39, etc.). The syntax is:
CASE WHEN <cond1> THEN <v1> WHEN <cond2> THEN <v2> ... [ ELSE <vn+1> ] END
You can specify only 255 arguments and each WHEN...THEN pair counts as two arguments. For a workaround to this limit, see Oracle8i SQL Reference.
Suppose you wanted to find the average salary of all employees in the company. If an employee's salary is less than $2000, then use $2000 instead. Currently, you would have to write this query as follows,
SELECT AVG(foo(e.sal)) FROM emps e;
where foo is a function that returns its input if the input is greater than 2000, and returns 2000 otherwise. The query has performance implications because it needs to invoke a PL/SQL function for each row.
Using CASE expressions natively in the RDBMS, the above query can be rewritten as:
SELECT AVG(CASE when e.sal > 2000 THEN e.sal ELSE 2000 end) FROM emps e;
Because this query does not require a PL/SQL function invocation, it is much faster.
You can use the CASE statement when you want to obtain histograms with user-defined buckets (both in number of buckets and width of each bucket). Below are two examples of histograms created with CASE statements. In the first example, the histogram totals are shown in multiple columns and a single row is returned. In the second example, the histogram is shown with a label column and a single column for totals, and multiple rows are returned.
Given the following dataset, we wish to create a histogram which includes the following four buckets: 70-79, 80-89 and 90-99, 100+.
| Ages |
|---|
|
100 |
|
96 |
|
93 |
|
90 |
|
88 |
|
85 |
|
79 |
|
76 |
|
76 |
|
72 |
Example 1:
SELECT SUM(CASE WHEN age BETWEEN 70 AND 79 THEN 1 ELSE 0 END) as "70-79", SUM(CASE WHEN age BETWEEN 80 AND 89 THEN 1 ELSE 0 END) as "80-89", SUM(CASE WHEN age BETWEEN 90 AND 99 THEN 1 ELSE 0 END) as "90-99", SUM(CASE WHEN age > 99 THEN 1 ELSE 0 END) as "100+" FROM customer;
The output is:
70-79 80-89 90-99 100+ ----- ----- ----- ---- 4 2 3 1
Example 2:
SELECT CASE WHEN age BETWEEN 70 AND 79 THEN '70-79' WHEN age BETWEEN 80 and 89 THEN '80-89' WHEN age BETWEEN 90 and 99 THEN '90-99' WHEN age > 99 THEN '100+' END) as age_group, COUNT(*) as age_count FROM customer GROUP BY CASE WHEN age BETWEEN 70 AND 79 THEN '70-79' WHEN age BETWEEN 80 and 89 THEN '80-89' WHEN age BETWEEN 90 and 99 THEN '90-99' WHEN age > 99 THEN '100+' END);
The output is:
age_group age_count --------- --------- 70-79 4 80-89 2 90-99 3 100+ 1
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|