Release 2 (8.1.6)
Part Number A76994-01
Library |
Product |
Contents |
Index |
| Oracle8i Data Warehousing Guide Release 2 (8.1.6) Part Number A76994-01 |
|
![]()
![]()
This chapter contains:
One of the major benefits of creating and maintaining materialized views is the ability to take advantage of query rewrite, which transforms a SQL statement expressed in terms of tables or views into a statement accessing one or more materialized views that are defined on the detail tables. The transformation is transparent to the end user or application, requiring no intervention and no reference to the materialized view in the SQL statement. Because query rewrite is transparent, materialized views can be added or dropped just like indexes without invalidating the SQL in the application code.
Before the query is rewritten, it is subjected to several checks to determine whether it is a candidate for query rewrite. If the query fails any of the checks, then the query is applied to the detail tables rather than the materialized view. This can be costly in terms of response time and processing power.
The Oracle optimizer uses two different methods to recognize when to rewrite a query in terms of one or more materialized views. The first method is based on matching the SQL text of the query with the SQL text of the materialized view definition. If the first method fails, the optimizer uses the more general method in which it compares join conditions, data columns, grouping columns, and aggregate functions between the query and a materialized view.
Query rewrite operates on queries and subqueries in the following types of SQL statements:
It also operates on subqueries in the set operators UNION, UNION ALL, INTERSECT, and MINUS, and subqueries in DML statements such as INSERT, DELETE, and UPDATE.
Several factors affect whether or not a given query is rewritten to use one or more materialized views:
Query rewrite is available with cost-based optimization. Oracle optimizes the input query with and without rewrite and selects the least costly alternative. The optimizer rewrites a query by rewriting one or more query blocks, one at a time.
If the rewrite logic has a choice between multiple materialized views to rewrite a query block, it will select one to optimize the ratio of the sum of the cardinality of the tables in the rewritten query block to that in the original query block. Therefore, the materialized view selected would be the one which can result in reading in the least amount of data.
After a materialized view has been picked for a rewrite, the optimizer performs the
rewrite, and then tests whether the rewritten query can be rewritten further with another materialized view. This process continues until no further rewrites are possible. Then the rewritten query is optimized and the original query is optimized. The optimizer compares these two optimizations and selects the least costly alternative.
Since optimization is based on cost, it is important to collect statistics both on tables involved in the query and on the tables representing materialized views. Statistics are fundamental measures, such as the number of rows in a table, that are used to calculate the cost of a rewritten query. They are created with the ANALYZE statement or by using the DBMS_STATISTICS package.
Queries that contain in-line or named views are also candidates for query rewrite. When a query contains a named view, the view name is used to do the matching between a materialized view and the query. That is, the set of named views in a materialized view definition should match exactly with the set of views in the query. When a query contains an inline view, the inline view may be merged into the query before matching between a materialized view and the query occurs.
The following presents a graphical view of the cost-based approach.
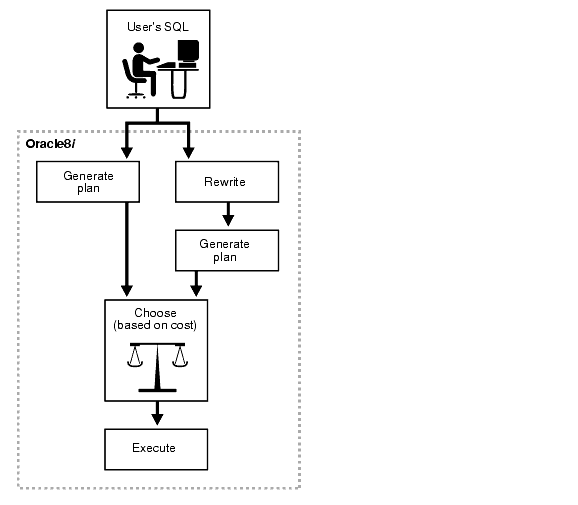
Several steps must be followed to enable query rewrite:
If step 1 has not been completed, a materialized view will never be eligible for query rewrite. ENABLE QUERY REWRITE can be specified either when the materialized view is created, as illustrated below, or via the ALTER MATERIALIZED VIEW statement.
CREATE MATERIALIZED VIEW store_sales_mv ENABLE QUERY REWRITE AS SELECT s.store_name, SUM(dollar_sales) AS sum_dollar_sales FROM store s, fact f WHERE f.store_key = s.store_key GROUP BY s.store_name;
You can use the initialization parameter QUERY_REWRITE_ENABLED to disable query rewrite for all materialized views, or to enable it again for all materialized views that are individually enabled. However, the QUERY_REWRITE_ENABLED parameter cannot enable query rewrite for materialized views that have disabled it with the CREATE or ALTER statement.
The NOREWRITE hint disables query rewrite in a SQL statement, overriding the QUERY_REWRITE_ENABLED parameter, and the REWRITE (mview_name, ...) hint restricts the eligible materialized views to those named in the hint.
Query rewrite requires the following initialization parameter settings:
The QUERY_REWRITE_INTEGRITY parameter is optional, but must be set to STALE_TOLERATED, TRUSTED, or ENFORCED if it is specified (see "Accuracy of Query Rewrite"). It will default to ENFORCED if it is undefined.
Because the integrity level is set by default to ENFORCED, all constraints must be validated. Therefore, if you use ENABLE NOVALIDATE, certain types of query rewrite may not work. So you should set your integrity level to a lower level of granularity such as TRUSTED or STALE_TOLERATED.
With OPTIMIZER_MODE set to CHOOSE, a query will not be rewritten unless at least one table referenced by it has been analyzed. This is because the rule-based optimizer is used when OPTIMIZER_MODE is set to CHOOSE and none of the tables referenced in a query have been analyzed.
A materialized view is used based not on privileges the user has on that materialized view, but based on privileges the user has on detail tables or views in the query.
The system privilege GRANT REWRITE allows you to enable materialized views in your own schema for query rewrite only if all tables directly referenced by the materialized view are in that schema. The GRANT GLOBAL REWRITE privilege allows you to enable materialized views for query rewrite even if the materialized view references objects in other schemas.
The privileges for using materialized views for query rewrite are similar to those for definer-rights procedures. See Oracle8i Concepts for further information.
A query is rewritten only when a certain number of conditions are met:
To determine this, the optimizer may depend on some of the data relationships declared by the user via constraints and dimensions. Such data relationships include hierarchies, referential integrity, and uniqueness of key data, and so on.
The following sections use an example schema and a few materialized views to illustrate how the data relationships are used by the optimizer to rewrite queries. A retail database consists of these tables:
STORE (store_key, store_name, store_city, store_state, store_country) PRODUCT (prod_key, prod_name, prod_brand) TIME (time_key, time_day, time_week, time_month) FACT (store_key, prod_key, time_key, dollar_sales)
Two materialized views created on these tables contain only joins:
CREATE MATERIALIZED VIEW join_fact_store_time ENABLE QUERY REWRITE AS SELECT s.store_key, s.store_name, f.dollar_sales, t.time_key, t.time_day, f.prod_key, f.rowid, t.rowid FROM fact f, store s, time t WHERE f.time_key = t.time_key AND f.store_key = s.store_key; CREATE MATERIALIZED VIEW join_fact_store_time_oj ENABLE QUERY REWRITE AS SELECT s.store_key, s.store_name, f.dollar_sales, t.time_key, f.rowid, t.rowid FROM fact f, store s, time t WHERE f.time_key = t.time_key(+) AND f.store_key = s.store_key(+);
and two materialized views contain joins and aggregates:
CREATE MATERIALIZED VIEW sum_fact_store_time_prod ENABLE QUERY REWRITE AS SELECT s.store_name, time_week, p.prod_key, SUM(f.dollar_sales) AS sum_sales, COUNT(f.dollar_sales) AS count_sales FROM fact f, store s, time t, product p WHERE f.time_key = t.time_key AND f.store_key = s.store_key AND f.prod_key = p.prod_key GROUP BY s.store_name, time_week, p.prod_key; CREATE MATERIALIZED VIEW sum_fact_store_prod ENABLE QUERY REWRITE AS SELECT s.store_city, p.prod_name SUM(f.dollar_sales) AS sum_sales, COUNT(f.dollar_sales) AS count_sales FROM fact f, store s, product p WHERE f.store_key = s.store_key AND f.prod_key = p.prod_key GROUP BY store_city, p.prod_name;
You must collect statistics on the materialized views so that the optimizer can determine based on cost whether to rewrite the queries.
ANALYZE TABLE join_fact_store_time COMPUTE STATISTICS; ANALYZE TABLE join_fact_store_time_oj COMPUTE STATISTICS; ANALYZE TABLE sum_fact_store_time_prod COMPUTE STATISTICS; ANALYZE TABLE sum_fact_store_prod COMPUTE STATISTICS;
The optimizer uses a number of different methods to rewrite a query. The first, most important step is to determine if all or part of the results requested by the query can be obtained from the precomputed results stored in a materialized view.
The simplest case occurs when the result stored in a materialized view exactly matches what is requested by a query. The Oracle optimizer makes this type of determination by comparing the SQL text of the query with the SQL text of the materialized view definition. This method is most straightforward and also very limiting.
When the SQL text comparison test fails, the Oracle optimizer performs a series of generalized checks based on the joins, grouping, aggregates, and column data fetched. This is accomplished by individually comparing various clauses (SELECT, FROM, WHERE, GROUP BY) of a query with those of a materialized view.
Two methods are used by the optimizer:
In full SQL text match, the entire SQL text of a query is compared against the entire SQL text of a materialized view definition (that is, the entire SELECT expression), ignoring the white space during SQL text comparison. The following query
SELECT s.store_name, time_week, p.prod_key, SUM(f.dollar_sales) AS sum_sales, COUNT(f.dollar_sales) AS count_sales FROM fact f, store s, time t, product p WHERE f.time_key = t.time_key AND f.store_key = s.store_key AND f.prod_key = p.prod_key GROUP BY s.store_name, time_week, p.prod_key;
which matches sum_fact_store_time_prod (white space excluded) will be rewritten as:
SELECT store_name, time_week, product_key, sum_sales, count_sales FROM sum_fact_store_time_prod;
When full SQL text match fails, the optimizer then attempts a partial SQL text match. In this method, the SQL text starting from the FROM clause of a query is compared against the SQL text starting from the FROM clause of a materialized view definition. Therefore, this query:
SELECT s.store_name, time_week, p.prod_key, AVG(f.dollar_sales) AS avg_sales FROM fact f, store s, time t, product p WHERE f.time_key = t.time_key AND f.store_key = s.store_key AND f.prod_key = p.prod_key GROUP BY s.store_name, time_week, p.prod_key;
will be rewritten as:
SELECT store_name, time_week, prod_key, sum_sales/count_sales AS avg_sales FROM sum_fact_store_time_prod;
Note that, under the partial SQL text match rewrite method, the average of sales aggregate required by the query is computed using sum of sales and count of sales aggregates stored in the materialized view.
When neither SQL text match succeeds, the optimizer uses a general query rewrite method.
The general query rewrite methods are much more powerful than SQL text match methods because they can enable the use of a materialized view even if it contains only part of the data requested by a query, or it contains more data than what is requested by a query, or it contains data in a different form which can be converted into a form required by a query. To achieve this, the optimizer compares the SQL clauses (SELECT, FROM, WHERE, GROUP BY) individually between a query and a materialized view.
The Oracle optimizer employs four different checks called:
Depending on the type of a materialized view, some or all four checks are made to determine if the materialized view can be used to rewrite a query as illustrated in Table 19-1.
|
MV with Joins Only |
MV with Joins and Aggregates | MV with Aggregates on a Single Table | |
|---|---|---|---|
|
Join Compatibility |
X |
X |
- |
|
Data Sufficiency |
X |
X |
X |
|
Grouping Compatibility |
- |
X |
X |
|
Aggregate Computability |
- |
X |
X |
To perform these checks, the optimizer uses data relationships on which it can depend. For example, primary key and foreign key relationships tell the optimizer that each row in the foreign key table joins with at most one row in the primary key table. Furthermore, if there is a NOT NULL constraint on the foreign key, it indicates that each row in the foreign key table joins with exactly one row in the primary key table.
Data relationships such as these are very important for query rewrite because they tell what type of result is produced by joins, grouping, or aggregation of data. Therefore, to maximize the rewritability of a large set of queries when such data relationships exist in a database, they should be declared by the user.
In this check, the joins in a query are compared against the joins in a materialized view. In general, this comparison results in the classification of joins into three categories:
They can be visualized as follows:
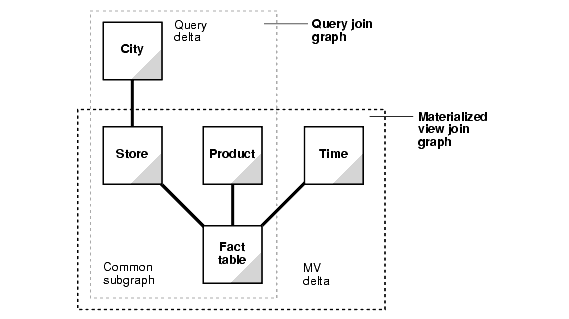
The common join pairs between the two must be of the same type, or the join in the query must be derivable from the join in the materialized view. For example, if a materialized view contains an outer join of table A with table B, and a query contains an inner join of table A with table B, the result of the inner join can be derived by filtering the anti-join rows from the result of the outer join.
For example, consider this query:
SELECT s.store_name, t.time_day, SUM(f.dollar_sales) FROM fact f, store s, time t WHERE f.time_key = t.time_key AND f.store_key = s.store_key AND t.time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP BY s.store_name, t.time_day;
The common joins between this query and the materialized view join_fact_store_time are:
f.time_key = t.time_key AND f.store_key = s.store_key
They match exactly and the query can be rewritten as:
SELECT store_name, time_day, SUM(dollar_sales) FROM join_fact_store_time WHERE time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP BY store_name, time_day;
The query could also be answered using the join_fact_store_time_oj materialized view where inner joins in the query can be derived from outer joins in the materialized view. The rewritten version will (transparently to the user) filter out the anti-join rows. The rewritten query will have the structure:
SELECT store_name, time_day, SUM(f.dollar_sales) FROM join_fact_store_time_oj WHERE time_key IS NOT NULL AND store_key IS NOT NULL AND time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP BY store_name, time_day;
In general, if you use an outer join in a materialized view containing only joins, you should put in the materialized view either the primary key or the rowid on the right side of the outer join. For example, in the previous example, join_fact_store_time_oj there is a primary key on both store and time.
Another example of when a materialized view containing only joins is used is the case of a semi-join rewrites. That is, a query contains either an EXISTS or an IN subquery with a single table.
Consider this query, which reports the stores that had sales greater than $10,000 during the 1997 Christmas season.
SELECT DISTINCT store_name FROM store s WHERE EXISTS (SELECT * FROM fact f WHERE f.store_key = s.store_key AND f.dollar_sales > 10000 AND f.time_key BETWEEN '01-DEC-1997' AND '31-DEC-1997');
This query could also be seen as:
SELECT DISTINCT store_name FROM store s WHERE s.store_key IN (SELECT f.store_key FROM fact f WHERE f.dollar_sales > 10000);
This query contains a semi-join 'f.store_key = s.store_key' between the store and the fact table. This query can be rewritten to use either the join_fact_store_time materialized view, if foreign key constraints are active or join_fact_store_time_oj materialized view, if primary keys are active. Observe that both materialized views contain 'f.store_key = s.store_key' which can be used to derive the semi-join in the query.
The query is rewritten with join_fact_store_time as follows:
SELECT store_name FROM (SELECT DISTINCT store_name, store_key FROM join_fact_store_time WHERE dollar_sales > 10000 AND f.time_key BETWEEN '01-DEC-1997' AND '31-DEC-1997');
If the materialized view join_fact_store_time is partitioned by time_key, then this query is likely to be more efficient than the original query because the original join between store and fact has been avoided.
The query could be rewritten using join_fact_store_time_oj as follows.
SELECT store_name FROM (SELECT DISTINCT store_name, store_key FROM join_fact_store_time_oj WHERE dollar_sales > 10000 AND store_key IS NOT NULL AND time_key BETWEEN '01-DEC-1997' AND '31-DEC-1997');
Rewrites with semi-joins are currently restricted to materialized views with joins only and are not available for materialized views with joins and aggregates.
A query delta join is a join that appears in the query but not in the materialized view. Any number and type of delta joins in a query are allowed and they are simply retained when the query is rewritten with a materialized view. Upon rewrite, the materialized view is joined to the appropriate tables in the query delta.
For example, consider this query:
SELECT store_name, prod_name, SUM(f.dollar_sales) FROM fact f, store s, time t, product p WHERE f.time_key = t.time_key AND f.store_key = s.store_key AND f.prod_key = p.prod_key AND t.time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP BY store_name, prod_name;
Using the materialized view join_fact_store_time, common joins are: f.time_key = t.time_key AND f.store_key = s.store_key. The delta join in the query is f.prod_key = p.prod_key.
The rewritten form will then join the join_fact_store_time materialized view with the product table:
SELECT store_name, prod_name, SUM(f.dollar_sales) FROM join_fact_store_time mv, product p WHERE mv.prod_key = p.prod_key AND mv.time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP BY store_name, prod_name;
A materialized view delta join is a join that appears in the materialized view but not the query. All delta joins in a materialized view are required to be lossless with respect to the result of common joins. A lossless join guarantees that the result of common joins is not restricted. A lossless join is one where, if two tables called A and B are joined together, rows in table A will always match with rows in table B and no data will be lost, hence the term lossless join. For example, every row with the foreign key matches a row with a primary key provided no nulls are allowed in the foreign key. Therefore, to guarantee a lossless join, it is necessary to have FOREIGN KEY, PRIMARY KEY, and NOT NULL constraints on appropriate join keys. Alternatively, if the join between tables A and B is an outer join (A being the outer table), it is lossless as it preserves all rows of table A.
All delta joins in a materialized view are required to be non-duplicating with respect to the result of common joins. A non-duplicating join guarantees that the result of common joins is not duplicated. For example, a non-duplicating join is one where, if table A and table B are joined together, rows in table A will match with at most one row in table B and no duplication occurs. To guarantee a non-duplicating join, the key in table B must be constrained to unique values by using a primary key or unique constraint.
Consider this query which joins FACT and TIME:
SELECT t.time_day, SUM(f.dollar_sales) FROM fact f, time t WHERE f.time_key = t.time_key AND t.time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP t.time_day;
The materialized view join_fact_store_time has an additional join between FACT and STORE: 'f.store_key = s.store_key'. This is the delta join in join_fact_store_time.
We can rewrite the query if this join is lossless and non-duplicating. This is the case if f.store_key is a foreign key to s.store_key and is not null. The query is therefore rewritten as:
SELECT time_day, SUM(f.dollar_sales) FROM join_fact_store_time WHERE time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP BY time_day;
The query could also be rewritten with the materialized view join_fact_store_time_oj where foreign key constraints are not needed. This view contains an outer join between fact and store: 'f.store_key = s.store_key(+)' which makes the join lossless. If s.store_key is a primary key, then the non-duplicating condition is satisfied as well and optimizer will rewrite the query as:
SELECT time_day, SUM(f.dollar_sales) FROM join_fact_store_time_oj WHERE time_key IS NOT NULL AND time_day BETWEEN '01-DEC-1997' AND '31-DEC-1997' GROUP BY time_day;
The current limitations restrict most rewrites with outer joins to materialized views with joins only. There is very limited support for rewrites with materialized aggregate views with outer joins. Those views should rely on foreign key constraints to assure losslessness of materialized view delta joins.
In this check, the optimizer determines if the necessary column data requested by a query can be obtained from a materialized view. For this, the equivalence of one column with another is used. For example, if an inner join between table A and table B is based on a join predicate A.X = B.X, then the data in column A.X will equal the data in column B.X in the result of the join. This data property is used to match column A.X in a query with column B.X in a materialized view or vice versa.
For example, consider this query:
SELECT s.store_name, f.time_key, SUM(f.dollar_sales) FROM fact f, store s, time t WHERE f.time_key = t.time_key AND f.store_key = s.store_key GROUP BY s.store_name, f.time_key;
This query can be answered with join_fact_store_time even though the materialized view doesn't have f.time_key. Instead, it has t.time_key which, through a join condition 'f.time_key = t.time_key', is equivalent to f.time_key.
Thus, the optimizer may select this rewrite:
SELECT store_name, time_key, SUM(dollar_sales) FROM join_fact_store_time GROUP BY store_name, time_key;
If some column data requested by a query cannot be obtained from a materialized view, the optimizer further determines if it can be obtained based on a data relationship called functional dependency. When the data in a column can determine data in another column, such a relationship is called functional dependency or functional determinance. For example, if a table contains a primary key column called prod_key and another column called prod_name, then, given a prod_key value, it is possible to look up the corresponding prod_name. The opposite is not true, which means a prod_name value need not relate to a unique prod_key.
When the column data required by a query is not available from a materialized view, such column data can still be obtained by joining the materialized view back to the table that contains required column data provided the materialized view contains a key that functionally determines the required column data.
For example, consider this query:
SELECT s.store_name, t.time_week, p.prod_name, SUM(f.dollar_sales) AS sum_sales, FROM fact f, store s, time t, product p WHERE f.time_key = t.time_key AND f.store_key = s.store_key AND f.prod_key = p.prod_key AND p.prod_brand = 'KELLOGG' GROUP BY s.store_name, t.time_week, p.prod_name;
The materialized view sum_fact_store_time_prod contains p.prod_key, but not p.prod_brand. However, we can join sum_fact_store_time_prod back to PRODUCT to retrieve prod_brand because prod_key functionally determines prod_brand. The optimizer rewrites this query using sum_fact_store_time_prod as:
SELECT mv.store_name, mv.time_week, p.product_key, mv.sum_sales, FROM sum_fact_store_time_prod mv, product p WHERE mv.prod_key = p.prod_key AND p.prod_brand = 'KELLOGG' GROUP BY mv.store_name, mv.time_week, p.prod_key;
Here the PRODUCT table is called a joinback table because it was originally joined in the materialized view but joined again in the rewritten query.
There are two ways to declare functional dependency:
The DETERMINES clause of a dimension definition may be the only way you could declare functional dependency when the column that determines another column cannot be a primary key. For example, the STORE table is a denormalized dimension table which has columns store_key, store_name, store_city, city_name, and store_state. Store_key functionally determines store_name and store_city functionally determines city_name.
The first functional dependency can be established by declaring store_key as the primary key, but not the second functional dependency because the store_city column contains duplicate values. In this situation, you can use the DETERMINES clause of a dimension to declare the second functional dependency.
The following dimension definition illustrates how the functional dependencies are declared.
CREATE DIMENSION store_dim LEVEL store_key IS store.store_key LEVEL city IS store.store_city LEVEL state IS store.store_state LEVEL country IS store.store_country HIERARCHY geographical_rollup ( store_key CHILD OF city CHILD OF state CHILD OF country ) ATTRIBUTE store_key DETERMINES store.store_name; ATTRIBUTE store_city DETERMINES store.city_name;
The hierarchy geographical_rollup declares hierarchical relationships which are also 1:n functional dependencies. The 1:1 functional dependencies are declared using the DETERMINES clause, such as store_city functionally determines city_name.
The following query:
SELECT s.store_city, p.prod_name SUM(f.dollar_sales) AS sum_sales, FROM fact f, store s, product p WHERE f.store_key = s.store_key AND f.prod_key = p.prod_key AND s.city_name = 'BELMONT' GROUP BY s.store_city, p.prod_name;
can be rewritten by joining sum_fact_store_prod to the STORE table so that city_name is available to evaluate the predicate. But the join will be based on the store_city column, which is not a primary key in the STORE table; therefore, it allows duplicates. This is accomplished by using an inline view which selects distinct values and this view is joined to the materialized view as shown in the rewritten query below.
SELECT iv.store_city, mv.prod_name, mv.sum_sales FROM sum_fact_store_prod mv, (SELECT DISTINCT store_city, city_name FROM store) iv WHERE mv.store_city = iv.store_city AND iv.city_name = 'BELMONT' GROUP BY iv.store_city, mv.prod_name;
This type of rewrite is possible because of the fact that store_city functionally determines city_name as declared in the dimension.
This check is required only if both the materialized view and the query contain a GROUP BY clause. The optimizer first determines if the grouping of data requested by a query is exactly the same as the grouping of data stored in a materialized view. In other words, the level of grouping is the same in both the query and the materialized view. For example, a query requests data grouped by store_city and a materialized view stores data grouped by store_city and store_state. The grouping is the same in both provided store_city functionally determines store_state, such as the functional dependency shown in the dimension example above.
If the grouping of data requested by a query is at a coarser level compared to the grouping of data stored in a materialized view, the optimizer can still use the materialized view to rewrite the query. For example, the materialized view sum_fact_store_time_prod groups by store_name, time_week, and prod_key. This query groups by store_name, a coarser grouping granularity:
SELECT s.store_name, SUM(f.dollar_sales) AS sum_sales, FROM fact f, store s WHERE f.store_key = s.store_key GROUP BY s.store_name;
Therefore, the optimizer will rewrite this query as:
SELECT store_name, SUM(sum_dollar_sales) AS sum_sales, FROM sum_fact_store_time_prod GROUP BY s.store_name;
In another example, a query requests data grouped by store_state whereas a materialized view stores data grouped by store_city. If store_city is a CHILD OF store_state (see the dimension example above), the grouped data stored in the materialized view can be further grouped by store_state when the query is rewritten. In other words, aggregates at store_city level (finer granularity) stored in a materialized view can be rolled up into aggregates at store_state level (coarser granularity).
For example, consider the following query:
SELECT store_state, prod_name, SUM(f.dollar_sales) AS sum_sales FROM fact f, store s, product p WHERE f.store_key = s.store_key AND f.prod_key = p.prod_key GROUP BY store_state, prod_name;
Because store_city functionally determines store_state, sum_fact_store_prod can be used with a joinback to store table to retrieve store_state column data, and then aggregates can be rolled up to store_state level, as shown below:
SELECT store_state, prod_name, sum(mv.sum_sales) AS sum_sales FROM sum_fact_store_prod mv, (SELECT DISTINCT store_city, store_state FROM store) iv WHERE mv.store_city = iv.store_city GROUP BY store_state, prod_name;
Note that for this rewrite, the data sufficiency check determines that a joinback to the STORE table is necessary, and the grouping compatibility check determines that aggregate rollup is necessary.
This check is required only if both the query and the materialized view contain aggregates. Here the optimizer determines if the aggregates requested by a query can be derived or computed from one or more aggregates stored in a materialized view. For example, if a query requests AVG(X) and a materialized view contains SUM(X) and COUNT(X), then AVG(X) can be computed as SUM(X) / COUNT(X).
If the grouping compatibility check determined that the rollup of aggregates stored in a materialized view is required, then the aggregate computability check determines if it is possible to roll up each aggregate requested by the query using aggregates in the materialized view.
For example, SUM(sales) at the city level can be rolled up to SUM(sales) at the state level by summing all SUM(sales) aggregates in a group with the same state value. However, AVG(sales) cannot be rolled up to a coarser level unless COUNT(sales) is also available in the materialized view. Similarly, VARIANCE(sales) or STDDEV(sales) cannot be rolled up unless COUNT(sales) and SUM(sales) are also available in the materialized view. For example, given the query:
SELECT p.prod_name, AVG(f.dollar_sales) AS avg_sales FROM fact f, product p WHERE f.prod_key = p.prod_key GROUP BY p.prod_name;
The materialized view sum_fact_store_prod can be used to rewrite it provided the join between FACT and STORE is lossless and non-duplicating. Further, the query groups by prod_name whereas the materialized view groups by store_city, prod_name, which means the aggregates stored in the materialized view will have to be rolled up. The optimizer will rewrite the query as:
SELECT mv.prod_name, SUM(mv.sum_sales)/SUM(mv.count_sales) AS avg_sales FROM sum_fact_store_prod mv GROUP BY mv.prod_name;
The argument of an aggregate such as SUM can be an arithmetic expression like A+B. The optimizer will try to match an aggregate SUM(A+B) in a query with an aggregate SUM(A+B) or SUM(B+A) stored in a materialized view. In other words, expression equivalence is used when matching the argument of an aggregate in a query with the argument of a similar aggregate in a materialized view. To accomplish this, Oracle converts the aggregate argument expression into a canonical form such that two different but equivalent expressions convert into the same canonical form. For example, A*(B-C), A*B-C*A, (B-C)*A, and -A*C+A*B all convert into the same canonical form and, therefore, they are successfully matched.
A query that contains GROUP BY CUBE or GROUP BY ROLLUP clauses can be rewritten in terms of a materialized view as long as the grouping of the query is compatible with the grouping in a materialized view. For example, consider the following query:
SELECT store_city, prod_name, AVG(f.dollar_sales) AS avg_sales FROM fact f, store s, product p WHERE f.store_key = s.store_key AND f.prod_key = p.prod_key GROUP BY CUBE(store_city, prod_name);
This query can be rewritten in terms of the materialized view sum_fact_store_prod as follows:
SELECT store_city, prod_name, SUM(sum_sales)/SUM(count_sales) AS avg_sales FROM sum_fact_store_prod GROUP BY CUBE (store_city, prod_name);
Note that the grouping in sum_fact_store_prod matches with the grouping in the query. However, the query requires a cube result which means super aggregates should be computed from the base aggregates available from the materialized view. This is accomplished by retaining the GROUP BY CUBE clause in the rewritten query.
A cube or rollup query can be also rewritten in terms of a materialized view which groups data at a finer granularity level. In this type of rewrite, the rewritten query will compute both the base aggregates (from finer to coarser granularity level) and the super aggregates.
To clarify when dimensions and constraints are required for the different types of query rewrite, refer to Table 19-2.
Rewrite capability with complex materialized views is limited to SQL text match-based rewrite (partial or full). A materialized view can be defined using arbitrarily complex SQL query expressions, but such a materialized view is treated as complex by query rewrite. For example, some of the constructs that make a materialized view complex are: selection predicates in the WHERE clause, a HAVING clause, inline views, multiple instances of same table or view, set operators (UNION, UNION ALL, INTERSECT, MINUS), START WITH clause, CONNECT BY clause, etc. Therefore, a complex materialized view limits rewritability but can be used to rewrite specific queries that are highly complex and execute very slowly.
A view-based materialized view contains one or more named views in the FROM clause of its SQL expression. Such a materialized view is subject to some important query rewrite restrictions. In order for the view-based materialized view to be eligible to rewrite a query, all views referenced in it must also be referenced in the query. However, the query can have additional views and this will not make a view-based materialized view ineligible.
Another important restriction with view-based materialized views is related to the determination of the lossless joins. Any join based on view columns in a view-based materialized view is considered a lossy join by the join compatibility check. This means that if there are some delta joins in a view-based materialized view and if at least one of the delta joins is based on view columns, the join compatibility check will fail.
View-based materialized views are useful when you want to materialize only a subset of table data. For example, if you want to summarize the data only for the year 1996 and store it in a materialized view, it can be done in two ways.
Query rewrite is attempted recursively to take advantage of nested materialized views. Oracle first tries to rewrite a query Q with a materialized view having aggregates and joins, then with a materialized join view. If any of the rewrites succeeds, Oracle repeats that process again until no rewrites have occurred.
For example, assume that you had created materialized views join_fact_store_time and sum_sales_store_time as in "Example of a Nested Materialized View".
Consider this query:
SELECT store_name, time_day, SUM(dollar_sales) FROM fact f, store s, time t WHERE f.time_key = t.time_key AND f.store_key = s.store_key GROUP BY store_name, time_day;
Oracle first tries to rewrite it with a materialized aggregate view and finds there is none eligible (note that single-table aggregate materialized view, sum_sales_store_time cannot yet be used), and then tries a rewrite with a materialized join view and finds that join_fact_store_time is eligible for rewrite. The rewritten query has this form:
SELECT store_name, time_day, SUM(dollar_sales) FROM join_fact_store_time GROUP BY store_name, time_day;
Because a rewrite occurred, Oracle tries the process again. This time the above query can be rewritten with single-table aggregate materialized view sum_sales_store_time into this form:
SELECT store_name, time_day, sum_sales FROM sum_sales_store_time;
An expression that appears in a query can be replaced with a simple column in a materialized view provided the materialized view column represents a precomputed expression that matches with the expression in the query. Because a materialized view stores pre-computed results of an expression, any query that is rewritten to use such a materialized view will benefit through performance improvement achieved by obviating the need for expression computation.
The expression matching is done by first converting the expressions into canonical forms and then comparing them for equality. Therefore, two different expressions will be matched as long as they are equivalent to each other. Further, if the entire expression in a query fails to match with an expression in a materialized view, then subexpressions of it are tried to find a match. The subexpressions are tried in a top-down order to get maximal expression matching.
Consider a query that asks for sum of sales by age brackets (1-10, 11-20, 21-30,...).
SELECT (age+9)/10 AS age_bracket, SUM(sales) AS sum_sales FROM fact, customer WHERE fact.cust_id = customer.cust_id GROUP BY (age+9)/10;
Assume that there is a materialized view MV1 that summarizes sales by same age brackets as shown below:
CREATE MATERIALIZED VIEW sum_sales_mv ENABLE QUERY REWRITE AS SELECT (9+age)/10 AS age_bracket, SUM(sales) AS sum_sales FROM fact, customer WHERE fact.cust_id = customer.cust_id GROUP BY (9+age)/10;
The above query is rewritten in terms of sum_sales_mv based on the matching of the canonical forms of the age bracket expressions (i.e. (9+age)/10 and (age+9)/10) as follows.
SELECT age_bracket, sum_sales FROM sum_sales_mv;
Date folding rewrite is a specific form of expression matching rewrite. In this type of rewrite, a date range in a query is folded into an equivalent date range representing higher date granules. The resulting expressions representing higher date granules in the folded date range are matched with equivalent expressions in a materialized view. The folding of date range into higher date granules such as months, quarters, or years is done when the underlying datatype of the column is an Oracle DATE. The expression matching is done based on the use of canonical forms for the expressions.
DATE is a built-in datatype which represents ordered time units such as seconds, days, and months, and incorporates a time hierarchy (second -> minute -> hour -> day -> month -> quarter -> year). This hard-coded knowledge about DATE is used in folding date ranges from lower-date granules to higher-date granules. Specifically, folding a date value to the beginning of a month, quarter, year, or to the end of a month, quarter, year is supported. For example, the date value '1-jan-1999' can be folded into the beginning of either year '1999' or quarter '1999-1' or month '1999-01'. And, the date value '30-sep-1999' can be folded into the end of either quarter '1999-03' or month '1999-09'.
Because date values are ordered, any range predicate specified on date columns can be folded from lower level granules into higher level granules provided the date range represents an integral number of higher level granules. For example, the range predicate date_col BETWEEN '1-jan-1999' AND '30-jun-1999' can be folded into either a month range or a quarter range using the TO_CHAR function, which extracts specific date components from a date value.
The advantage of aggregating data by folded date values is the compression of data achieved. Without date folding, the data is aggregated at the lowest granularity level, resulting in increased disk space for storage and increased I/O to scan the materialized view.
Consider a query that asks for the sum of sales by product types for the years 1991, 1992, 1993.
SELECT prod_type, sum(sales) AS sum_sales FROM fact, product WHERE fact.prod_id = product.prod_id AND sale_date BETWEEN '1-jan-1991' AND '31-dec-1993' GROUP BY prod_type;
The date range specified in the query represents an integral number of years, quarters, or months. Assume that there is a materialized view MV3 that contains pre-summarized sales by prod_type and is defined as follows:
CREATE MATERIALIZED VIEW MV3 ENABLE QUERY REWRITE AS SELECT prod_type, TO_CHAR(sale_date,'yyyy-mm') AS month, SUM(sales) AS sum_sales FROM fact, product WHERE fact.prod_id = product.prod_id GROUP BY prod_type, TO_CHAR(sale_date, 'yyyy-mm');
The query can be rewritten by first folding the date range into the month range and then matching the expressions representing the months with the month expression in MV3. This rewrite is shown below in two steps (first folding the date range followed by the actual rewrite).
SELECT prod_type, SUM(sales) AS sum_sales FROM fact, product WHERE fact.prod_id = product.prod_id AND TO_CHAR(sale_date, 'yyyy-mm') BETWEEN TO_CHAR('1-jan-1991', 'yyyy-mm') AND TO_CHAR('31-dec-1993', 'yyyy-mm') GROUP BY prod_type; SELECT prod_type, sum_sales FROM MV3 WHERE month BETWEEN TO_CHAR('1-jan-1991', 'yyyy-mm') AND TO_CHAR('31-dec-1993', 'yyyy-mm'); GROUP BY prod_type;
If MV3 had pre-summarized sales by prod_type and year instead of prod_type and month, the query could still be rewritten by folding the date range into year range and then matching the year expressions.
Query rewrite offers three levels of rewrite integrity that are controlled by the initialization parameter QUERY_REWRITE_INTEGRITY, which can either be set in your parameter file or controlled using the ALTER SYSTEM or ALTER SESSION command. The three values it can take are:
This is the default mode. The optimizer will only use materialized views which it knows contain fresh data and only use those relationships that are based on enforced constraints.
In TRUSTED mode, the optimizer trusts that the data in the materialized views based on prebuilt tables is correct, and the relationships declared in dimensions and RELY constraints are correct. In this mode, the optimizer uses prebuilt materialized views, and uses relationships that are not enforced as well as those that are enforced. In this mode, the optimizer also 'trusts' declared but not enforced constraints and data relationships specified using dimensions.
In STALE_TOLERATED mode, the optimizer uses materialized views that are valid but contain stale data as well as those that contain fresh data. This mode offers the maximum rewrite capability but creates the risk of generating wrong results.
If rewrite integrity is set to the safest level, ENFORCED, the optimizer uses only enforced primary key constraints and referential integrity constraints to ensure that the results of the query are the same as the results when accessing the detail tables directly.
If the rewrite integrity is set to levels other than ENFORCED, then there are several situations where the output with rewrite may be different from that without it.
Since query rewrite occurs transparently, special steps have to be taken to verify that a query has been rewritten. Of course, if the query runs faster, this should indicate that rewrite has occurred but that is not proof. Therefore, to confirm that query rewrite does occur, use the EXPLAIN PLAN statement.
The EXPLAIN PLAN facility is used as described in Oracle8i SQL Reference. For query rewrite, all you need to check is that the object_name column in PLAN_TABLE contains the materialized view name. If it does, then query rewrite will occur when this query is executed.
In this example, the materialized view store_mv has been created.
CREATE MATERIALIZED VIEW store_mv ENABLE QUERY REWRITE AS SELECT s.region, SUM(grocery_sq_ft) AS sum_floor_plan FROM store s GROUP BY s.region;
If EXPLAIN PLAN is used on this SQL statement, the results are placed in the default table PLAN_TABLE.
EXPLAIN PLAN FOR SELECT s.region, SUM(grocery_sq_ft) FROM store s GROUP BY s.region;
For the purposes of query rewrite, the only information of interest from PLAN_TABLE is the OBJECT_NAME, which identifies the objects that will be used to execute this query. Therefore, you would expect to see the object name STORE_MV in the output as illustrated below.
SELECT object_name FROM plan_table; OBJECT_NAME ------------------------------ STORE_MV 2 rows selected.
A materialized view is only eligible for query rewrite if the ENABLE QUERY REWRITE clause has been specified, either initially when the materialized view was first created or subsequently via an ALTER MATERIALIZED VIEW command.
The initialization parameters described above can be set using the ALTER SYSTEM SET command. For a given user's session, ALTER SESSION can be used to disable or enable query rewrite for that session only. For example:
ALTER SESSION SET QUERY_REWRITE_ENABLED = TRUE;
The correctness of query rewrite can be set for a session, thus allowing different users to work at different integrity levels.
ALTER SESSION SET QUERY_REWRITE_INTEGRITY = STALE_TOLERATED; ALTER SESSION SET QUERY_REWRITE_INTEGRITY = TRUSTED; ALTER SESSION SET QUERY_REWRITE_INTEGRITY = ENFORCED;
Hints may be included in SQL statements to control whether query rewrite occurs. Using the NOREWRITE hint in a query prevents the optimizer from rewriting it.
The REWRITE hint with no argument in a query forces the optimizer to use a materialized view (if any) to rewrite it regardless of the cost.
The REWRITE (mv1, mv2, ...) hint with argument(s) forces rewrite to select the most suitable materialized view from the list of names specified.
For example, to prevent a rewrite, you can use:
SELECT /*+ NOREWRITE */ s.city, SUM(s.grocery_sq_ft) FROM store s GROUP BY s.city;
To force a rewrite using mv1, you can use:
SELECT /*+ REWRITE (mv1) */ s.city, SUM(s.grocery_sq_ft) FROM store s GROUP BY s.city;
Note that the scope of a rewrite hint is a query block. If a SQL statement consists of several query blocks (SELECT clauses), you may need to specify rewrite hint on each query block to control the rewrite for the entire statement.
The following guidelines will help in getting the maximum benefit from query rewrite. They are not mandatory for using query rewrite and rewrite is not guaranteed if you follow them. They are general rules of thumb.
Make sure all inner joins referred to in a materialized view have referential integrity (foreign key - primary key constraints) with additional NOT NULL constraints on the foreign key columns. Since constraints tend to impose a large overhead, you could make them NONVALIDATE and RELY and set the parameter QUERY_REWRITE_INTEGRITY to STALE_TOLERATED or TRUSTED. However, if you set QUERY_REWRITE_INTEGRITY to ENFORCED, all constraints must be enforced to get maximum rewritability.
You can express the hierarchical relationships and functional dependencies in normalized or denormalized dimension tables using the HIERARCHY and DETERMINES clauses of a dimension. Dimensions can express intra-table relationships which cannot be expressed by any constraints. Set the parameter QUERY_REWRITE_INTEGRITY to TRUSTED or STALE_TOLERATED for query rewrite to take advantage of the relationships declared in dimensions.
Another way of avoiding constraints is to use outer joins in the materialized view. Query rewrite will be able to derive an inner join in the query, such as (A.a = B.b), from an outer join in the materialized view (A.a = B.b(+)), as long as the rowid of B or column B.b is available in the materialized view. Most of the support for rewrites with outer joins is provided for materialized views with joins only. To exploit it, a materialized view with outer joins should store the rowid or primary key of the inner table of an outer join. For example, the materialized view join_fact_store_time_oj stores the primary keys store_key and time_key of the inner tables of outer joins.
If you need to speed up an extremely complex, long-running query, you could create a materialized view with the exact text of the query.
In order to get the maximum benefit from query rewrite, make sure that all aggregates which are needed to compute ones in the targeted set of queries are present in the materialized view. The conditions on aggregates are quite similar to those for incremental refresh. For instance, if AVG(x) is in the query, then you should store COUNT(x) and AVG(x) or store SUM(x) and COUNT(x) in the materialized view. Refer to Requirements for Fast Refresh in "General Restrictions on Fast Refresh".
Aggregating data at lower levels in the hierarchy is better than aggregating at higher levels because lower levels can be used to rewrite more queries. Note, however, that doing so will also take up more space. For example, instead of grouping on state, group on city (unless space constraints prohibit it).
Instead of creating multiple materialized views with overlapping or hierarchically related GROUP BY columns, create a single materialized view with all those GROUP BY columns. For example, instead of using a materialized view that groups by city and another materialized view that groups by month, use a materialized view that groups by city and month.
Use GROUP BY on columns which correspond to levels in a dimension but not on columns that are functionally dependent, because query rewrite will be able to use the functional dependencies automatically based on the DETERMINES clause in a dimension. For example, instead of grouping on city_name, group on city_id (as long as there is a dimension which indicates that the attribute city_id determines city_name, you will enable the rewrite of a query involving city_name).
If several queries share the same common subexpression, it is advantageous to create a materialized view with the common subexpression as one of its SELECT columns. This way, the performance benefit due to precomputation of the common subexpression can be obtained across several queries.
When creating a materialized view which aggregates data by folded date granules such as months or quarters or years, always use the year component as the prefix but not as the suffix. For example, TO_CHAR(date_col, 'yyyy-q') folds the date into quarters, which collate in year order, whereas TO_CHAR(date_col, 'q-yyyy') folds the date into quarters, which collate in quarter order. The former preserves the ordering while the latter does not. For this reason, any materialized view created without a year prefix will not be eligible for date folding rewrite.
Optimization with materialized views is based on cost and the optimizer needs statistics of both the materialized view and the tables in the query to make a cost-based choice. Materialized views should thus have statistics collected using either the ANALYZE TABLE statement or the DBMS_STATISTICS package.
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|