UML Diagrams
Main structure diagram
External compiler
Compiler listeners
Compiler support
org.openide.compiler
package. Also related to compilation are
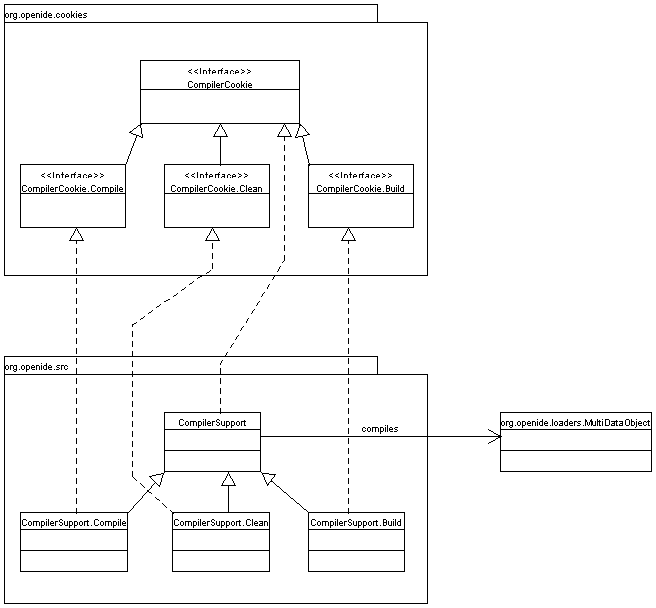
CompilerCookie,
CompilerSupport,
and
AbstractCompileAction.
In the text below, mention will be made of compiling versus building versus cleaning, as well as compilation depths (whether to recurse folders). While these concepts are documented on a user level in the IDE (e.g. Compile versus Build or versus Compile All), you may wish to refer to Types and Depths of Compilation below for details.
CompilerCookie.Compile
to indicate that they can be compiled; they have done this by
attaching a
CompilerSupport.Compile
support at
creation time.
AbstractCompileAction
notices that the compile cookie is present on all the selected nodes
and activates itself.
AbstractCompileAction.performAction(...)
is called, which collects the compiler cookie
(CompilerSupport.Compile) on each selected node.
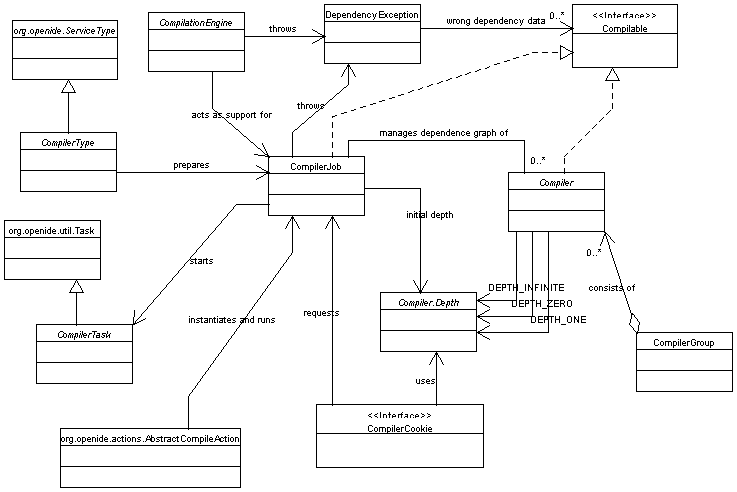
CompilerJob
is created to encapsulate the compilation of all the files. It may
get a
display name
to be used in some messages.
CompilerCookie, which
means that
CompilerSupport.addToJob(...)
is called.
CompilerType
associated with the data object it supports. See the
Services API
for details on how such associations may be made, in this case for
compiler types. This extra step permits the user to configure how
each file should be compiled. If the user has not specified otherwise,
the Java data loader provides a
default
for Java source files, which is also configurable by the user.
CompilerType.prepareJob(...).
If for example the compiler type represented (external) FastJavac
compilation, it will implement the method by creating a new
compiler object which will handle compilation of this
file. In this case, the compiler will extend
ExternalCompiler
and will include information such as the path to the
*.java file to be compiled, the path to the compiler,
the format of the compiler's error messages, optimization settings,
and so on. Other than the file itself, these settings are
initialized based on the compiler type's own
user-configured properties.
CompilerJob.add(Compiler)
to insert the compiler into the specified job.
CompilationEngine.createComputationLevels(CompilerJob)
is called by the compilation system to check whether any of the
compilers depend on one another, i.e. whether any of the
compilers in the job must be run before some others in order for
the latter to work properly. This would happen during multistage
compilation, but in this case there are no such dependencies so
just one level (stage) is created.
CompilationEngine.createCompilerGroups(Collection)
is used to cluster compilers into groups, each of which
typically corresponds to a single invocation of an external
compiler, etc. Different groups (in the same level) may be run
simultaneously. The method
Compiler.compilerGroupKey()
specifies an equivalence relation that is used to group together
compilers (if they are in the same level). Each group receives one
CompilerGroup
object created according to
Compiler.compilerGroupClass().
The grouping code, after creating each group, also calls the
implementation of
CompilerGroup.add(...)
to notify the group of each compiler that it should contain. The
external compiler group implementation, for example, keeps track of
all the files it will need to compile.
AbstractCompileAction calls
CompilerJob.start().
This will use the compilation implementation to create a
CompilerTask
giving control over the running compilation task. The implementation prepares
the system to compile (possibly waiting for other jobs to finish, creating separate
threads to contain different groups, and so on), and ultimately calls
CompilerGroup.start()
on each included group to actually run the compilation.
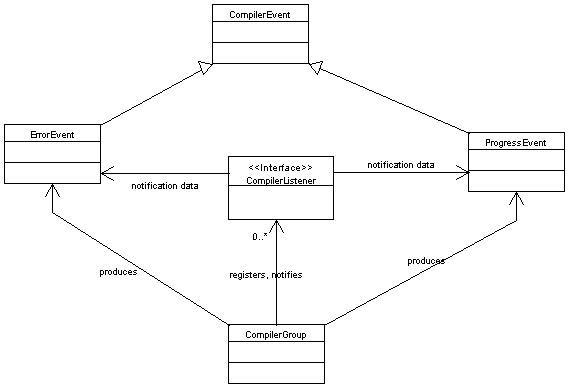
CompilerGroup.fireProgressEvent(...)
and
CompilerGroup.fireErrorEvent(...)
(the IDE has already registered listeners on these events).
CompilerGroup.start().
This code is transmitted via the compilation implementation back to the user
of the CompilerJob as the success status of the compiler task.
AbstractCompileAction.compile(...)
is the easiest way to begin compilation. You need to find the
compiler cookies from somewhere, e.g. starting with data objects
or nodes and using:
QueueEnumeration q = new QueueEnumeration ();
for (...) {
DataObject dob = ...;
// or: Node node = ...;
Object cookie = dob.getCookie (CompilerCookie.Compile.class);
// or: ... = node.getCookie ...
if (cookie != null) q.put (cookie);
}
AbstactCompileAction.compile (q, "Compiling some things");
CompilerCookie.Compile
(or the build or clean cookies, depending on what sort of
compilation you are doing) from the proper data objects or nodes as
above. In most cases the returned object will actually be a
CompilerSupport.Compile
(or .Build or .Clean), but you do not
need to depend on this being true.
Now create a compiler job using
new CompilerJob(Compiler.Depth),
which requires that you specify whether the compilation should be
recursive or not (if only source files and not directories are
involved, just use
Compiler.DEPTH_ZERO).
You should probably set a non-default display name using
CompilerJob.setDisplayName(String).
To prepare the job, all of the files to be compiled must be added
to the job, according to their compile cookies:
CompilerCookie.addToJob(...).
When the job has been populated with "compilers" (i.e. individual
compile requests), you may call
CompilerJob.start()
to actually run it. The returned
CompilerTask
permits you to tell whether the compilation was successful or not
(when it has finished), and if necessary to halt it prematurely.
If you know that the data object does do this, you may find the
proper compiler type for a data object using
CompilerSupport.getCompilerType(MultiDataObject.Entry)
(on the
primary entry)
and use its
CompilerType.prepareJob(...)
method directly to add compilers to the job (created as above). In
this case, it is necessary to specify the type of compilation here
(e.g., CompilerCookie.Compile).
Compiler;
and add it to the job using
CompilerJob.add(Compiler).
Now start the job as above.
The IDE's standard internal Javac-based compiler implementation
is not currently available in the Open APIs. However, a generic
external compiler (implemented fairly simply in terms of the
Execution API) is available. The standard external Javac
compilation is derived from this with a few implementation
enhancements. There are several constructors you may use, but
typically
new ExternalCompiler(FileObject,...)
is most natural.
Note that in addition to the file to be compiled (which should be present in the Repository), you must configure how the classpath works, and how to recognize errors. The error expression is configured via regular expression and should be handle to handle almost all normal compiler output.
This compiler will work efficiently if multiple such compilers are added to a job - all the file arguments will be collected and passed to one invocation, assuming that the compilers are all configured identically except for the file.
Compiler.
Several methods need to be implemented.
Compiler.isUpToDate()
is used by the compiler job to determine if this compiler actually
needs to be run or not - i.e., if the associated file (typically) is
lacking a compiled form, or has been edited since last compilation. If
the compiler is up to date, the job will skip it, saving time. Conventionally,
if a compiler is created using CompilerCookie.Build it should always
return false to force recompilation.
Compiler.compilerGroupClass()
indicates what type of compiler group to use - usually this will be
a class you implement yourself. Just
provide the class name.
FileObject,
DataObject,
or
MultiDataObject.Entry
is needed to specify what to compile, and the class of the compiler
cookie is usually also given so as to know whether to compile,
build, or clean.
It is possible to have the compiler's constructor accept multiple files at once, so as to batch them up. However, more natural is to have the group object handle batching instead; conventionally every compiler instance handles exactly one file or compilable object.
Object methods equals and
hashCode must be overridden correctly so
as to form a natural equivalence relation. Under some circumstances,
two identically configured compiler objects may be created during a
complex job; these must test as equal and have the same hash code, or
the file may be needlessly compiled twice. These methods are used to
remove duplicate compilers, and for manipulating compilers during the
calculation of dependencies, levels, and groups.
Compiler.compilerGroupKey()
must be overridden if you have added any compiler
properties (relative to the superclass) which might affect
grouping. For example, if the superclass implements regular Javac
compilation, but your compiler class also adds a special
configurable flag to the compiler command, you must override this
method to ensure that all the compilers in a group use the same
value for this flag. All compilers with the same key will be
grouped together.
The suggested implementation is something like this:
Object supe = super.compilerGroupKey (); List key = new ArrayList (2); key.add (supe); key.add (valueOfMyFlag); return key;This works because lists can be compared against one another, and the comparison traverses members of the list recursively.
CompilerGroup
and implement its two abstract methods (the others it should not be
necessary to override).
CompilerGroup.add(...)
will be called when a new compiler associated with this type of group
is created. Since there is no way to extract the compilers in the
group later, it is necessary to retain any required information about
the compilers now - either actual references to the compiler objects,
or just the essential data about which file was requested.
It is the responsibility of the compiler group to decide whether or not to batch up files together or not, and to handle this batching if so. Also note that if the compilers have specified dependencies among themselves (see below), multiple compiler groups may be created in parallel; each one has no cross-dependencies internally, so its files may be compiled in any order; and the groups will be executed sequentially, so as to make sure the dependencies are respected.
CompilerGroup.start()
should actually run the compilation to completion. It should upon
completion indicate whether all files were successfully compiled or
not. This method will typically be called in a dedicated thread. The
compiler group should handle setting up any external process (using
the Execution API, e.g.); controlling output streams; etc.
During the course of the compilation, the compiler group implementation should inform its listeners (normally just the IDE's internal compiler-handling code) of interesting events relating to the compilation:
CompilerGroup.fireProgressEvent(...)
should be used whenever the compiler moves into a new phase, or
switches to a new file (if it is possible to determine such things),
so that the IDE can (e.g.) display status messages in the main window
informing the user of what is going on.
CompilerGroup.fireErrorEvent(...)
should be called if the compilation produces any sort of error or
diagnostic warning. The event object fired can be examined by the IDE
to specially mark offending lines in the Editor, as well as being
displayed in the Compiler tab of the Output Window.
Compiler objects by a CompilerCookie implementation,
since there are usually details of the compilation (such as executable paths) which
the user should be permitted to configure for themselves if necessary,
possibly with multiple configurations according to the project and file.
Such configuration is best handled by the existing
service type system.
Instead, you may provide a
CompilerType
implementation which handles the details of constructing the compiler,
based on the data object it is supplied. (Using a data object should
almost always suffice, as a properly designed data object will
correspond to exactly one compilable item.) The
Services API: Creating a Service Type
details aspects of creating service types which are not specific to compilation,
so look at this first.
CompilerType.prepareJob(...)
should just extract the relevant information from the data object,
create an appropriate compiler object, and
insert it
into the supplied compiler job.
Generally a compiler type, like any service type, will have some
user-configurable Bean properties with getters and setters and
associated BeanInfo, which is all covered by the Services
API. Generally the compiler type will create the proper compiler by
passing it constructor arguments specifying the data object (or
file object, etc.) to compile; the cookie type if needed (for
example because the compiler may implement isUpToDate
differently for build cookies than for compile cookies); and
whatever compiler type parameters are to be used during the
compilation, such as process paths, classpath information, and so
on.
The second argument to prepareJob will be a
type of task,
such as
CompilerCookie.Compile,
and the method can just ignore the request if the compilation type
is inappropriate. Remember to check for exact
equality of the cookie class you expect to receive with the one
supplied. Often clean cookies (if supported) will be handled by an
entirely separate compiler and compiler group than the regular
compilation, for clarity of code; a typical prepareJob
implementation will switch based on the cookie as follows:
CompilerCookie.Compile cookies can be handled by
just creating a regular compiler and adding it to the job.
CompilerCookie.Clean cookies can be handled by
creating a cleaning compiler and adding it to the job.
CompilerCookie.Build cookies can be handled most
easily by creating both types of compilers and adding both to the
job. Then use
Compiler.dependsOn(Compilable)
to specify that the regular compiler depends on the clean
compiler. That is, the clean compiler will always be run to
completion first, removing all class files associated with the
object (or whatever your implementation of cleaning does); then the
regular compiler will be run in a later compilation level, as
desired.
If there is reason to make the new compiler type the default for some class of files, there are a couple options:
CompilerSupport,
you may specify that your compiler type should be the default for
this type of object by overriding
CompilerSupport.defaultCompilerType().
filesystem.attributes file in your template JAR.
Compiler,
CompilerGroup and CompilerType. However,
commonly running a compiler simply means calling an external compiler
process to do the job, and cleaning up the results a little by
handling its error messages. In this case, you need not implement all
of the logic to control an external process yourself; the APIs already
include an easily extensible compiler implementation designed for this
case.
Note that the API implementation of external compilation does not include any support for clean cookies - and its build cookie support does not remove old classfiles as a preliminary step, it merely affects up-to-date checks. If you do not need to support clean cookies, you should specifically ignore them if passed to your compiler type. If you do, you must handle them separately - probably by creating a custom compiler and compiler group to handle your cleaning. The reason this is not supported automatically is that cleaning is typically more dependent on the nature of the compiler (thus what files it produces) than the regular compilation.
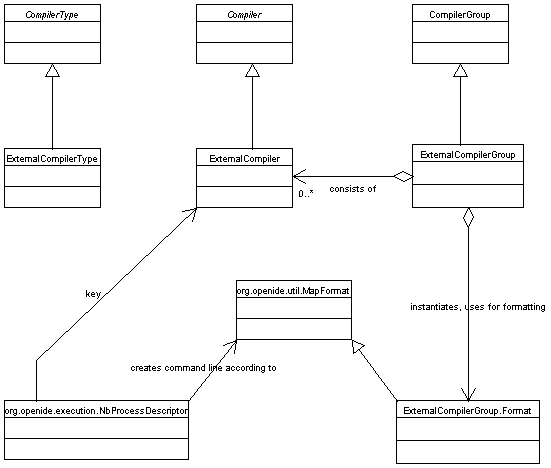
You will want to subclass
ExternalCompilerType
for its basic functionality (and BeanInfo). By default it includes
Bean properties permitting you to set the path to the compiler
executable, as well as a regular expression used to recognize and
parse compiler error messages. Decide on what additional (or
replacement) parameters the compiler will need for a full
configuration (e.g. optimization flags, etc.) and make Bean properties
for these, remembering to create corresponding BeanInfo entries - see
the Services API for general tips.
You will also want to subclass
ExternalCompiler
and
ExternalCompilerGroup.
Generally, the compiler object will hold onto various parameters as
well as specific information on the file to be compiled. Typically
these are passed to the compiler in its constructor by the compiler
type, and made available to the compiler group object via accessor
methods.
Implementing the compiler object should not be particularly tricky,
as it does not itself do much, though care must be taken as usual that
compilerGroupKey, equals, and
hashCode are sensibly overridden. Note that
isUpToDate will certainly need to be overridden if you
are not using the compiler on Java classes, since its default
implementation checks for matching *.class files. For
other data types, just implement this to look for the expected
compiler output files matching your known source files, and also check
that they are newer than the source files.
The compiler group also need not be difficult. In most cases, the
implementation of start in
ExternalCompilerGroup will suffice, as it handles all
aspects of launching and controlling the compiler process, as well as
collecting error output and the exit status. Most users of this class
will only need to override
ExternalCompilerGroup.createProcess(...)
which permits subclasses to specify details of how the external
command will be assembled. This is normally done using command
templates for maximum flexibility to the user. Please see the
Execution API
for details on how command templates may be used, since they apply
also to external execution.
It is a good idea to make sure any affected file folders are
refreshed before your compilation finishes (i.e. before the
start method returns). The implementation in
ExternalCompilerGroup will automatically refresh all file
folders in which source files were contained. If your compiler
produces output to alternate destinations which might be mounted in
the Repository, try to refresh all potentially affected folders:
override start to call the super implementation and then
perform refreshes before returning. If this is not done, subsequent
compilations may be performed unnecessarily (due to inaccurate
up-to-date checks), execution may perform erratically, etc.
ExternalCompiler provides the ability to serve as the
compiler for files which are not mounted in a filesystem, and thus do
not have a FileObject representation; and files which
actually do not exist at the time the compiler is created, but are
expected to exist by the time the compiler group's start
method is called. Except in these cases, the
new ExternalCompiler(FileObject,...)
constructor should be used.
The first case, that of unmounted files, is potentially useful for
compilations which should be run on "scratch" files outside of the
normal development area. These might be temporary files such as are
created e.g. as intermediates in JSP compilation. To handle these, use
the
new ExternalCompiler(File,...)
constructor. Here you can specify a java.io.File (which
need not exist at the time the constructor is called).
The second case, that of files which will have
FileObject representations but simply do not exist yet,
is normal during multistage compilations: for example, an IDL file may
be compiled to a Java source and then a classfile in one user-visible
step but two compilation stages. The first can use the regular
constructor; but for the second, the Java source does not exist at the
time the compiler job is being prepared, so this is
impossible. Instead, use
new ExternalCompiler(FileSystem,String,...)
(or just
new ExternalCompiler(String,...))
to specify what the expected name of the source file is, so that it can be found when it is actually required.
To produce a working multistage compilation you will need to set up compiler dependencies between the stages properly, usually done by the compiler type; see below.
There are three defined types of compilation, each associated with
a subinterface of
CompilerCookie,
as well as a user-visible command, and each implying a different sort
of action:
CompilerCookie.Compile)
to compile when needed (to bring things up-to-date). That is, sources
which have never been compiled will be compiled now; and sources which
have changed recently will be recompiled. Sources which were compiled
after their last modification will be left untouched.
CompilerCookie.Build)
to force recompilation (whether up-to-date or not), and take any other
measures to be positive everything that can be built, is. When in
doubt, implementors may make this identical to .Compile.
CompilerCookie.Clean)
to remove any detritus associated with the compilation process, such
as temporary files.
CompilerSupport is
being used, since associated compilers might possibly support all
three; and the compiler type should select the correct compiler
implementation based on the cookie class - e.g. the Clean cookie would
probably select a completely different compiler class.
There are three depths of compilation, each associated with a
constant of type
Compiler.Depth.
Most implementors will never need to bother with these, since the
combination of CompilerSupport and
CompilerType handles this detail, but for those who need
to know:
Compiler.DEPTH_ZERO
indicates that an individual file will be compiled, but folders should
be ignored. There is no user-visible action which employs this depth,
though API code may make use of it if desired.
Compiler.DEPTH_ONE
requests that files be compiled, and the immediate contents of
specified folders should be compiled as well (but not the contents of
subfolders). The user action Compile (for example) uses this
depth.
Compiler.DEPTH_INFINITE
requests that files be compiled, and all contents (immediate and
recursive) of subfolders. The corresponding user actions are
Compile All (and so on).
A new compiler-cookie implementation need only support a compiler depth of
one.
This is true e.g. of
CompilerSupport
(which most implementors should use if possible).
The standard implementation of
DataFolder
provides all three types of cookies at any compiler depth; recursive
compilation actions (such as are presented in the Build menu) work by
recursively looking for file-based data objects under the given
folder, and collecting into a compiler job any that implement the same
type of cookie (Compile, etc.).
The compilation system supports a system of cross-dependencies between compilers.
It is best to give some examples of when dependencies would be needed:
Foo.sqlj would first be "compiled" (using
a preprocessor) to a Foo.java file, then a regular Java
compiler run on this to create a Foo.class. In some cases
even more stages may be involved. Clearly these stages must be
ordered. In this case, the Java compiler must depend on the
preprocessor. In other cases, a postprocessor would need to depend on
a Java compiler; and so on.
All of these examples require a similar basic mechanism of specifying
dependencies, which is possible in the APIs and is typically employed
by a compiler type when preparing a job. First of all, both
Compiler and CompilerJob implement an
interface
Compilable
which specifies compilers included in the objects, as well as
dependencies on other compilables. Both also provide methods to add
dependencies (the links are for Compiler):
dependsOn(Compilable)
and
dependsOn(Collection<Compilable>).
Dependencies between compilers and/or compiler jobs may be added at
any time before a job is started, though typically it is the domain of
a compiler type to arrange the dependencies.
How would these methods be used in practice?
CompilerCookie in any particular way;
and CompilerCookie only specifies that the object knows
how to add compilers to a job, but does not give a way of obtaining
these compilers directly. Therefore, it is necessary to create a new
dummy compiler job. Each data object should be asked for its
cookie, and this cookie used to prepare the dummy job. Now, the JAR's
own compiler can specify a dependency on the dummy compiler job. This
means two things: if the job to which the JAR's own compiler was added
is run, then all of these other compilers will be run as well; and
that all of these other compilers must finish (and succeed,
i.e. return true from
CompilerGroup.start())
before the JAR's compiler may be started.
Technically, all the Compilable's are arranged into a
partial order according to their dependencies (calculated in a
recursively transitive way). This ensures that the proper order for
the entire top-level job is respected. First, all compilers are put
into a partial order, i.e. a set of levels; the order of compilers
within a level is unspecified, but between any two consecutive levels
at least one compiler in the latter depends on at least one in the
former. After levels are computed, compilers are further clustered
into groups for efficiency. The levels are run in sequence by the
compilation engine, while the groups within a level may be run in
parallel (i.e. in different threads).
Note that there is a distinction between
CompilerJob.add(Compiler)
and
CompilerJob.dependsOn(Compilable)
(with a Compiler argument, let us say). The first ensures
that the stated compiler is included in the job, which for
example means that if the job depends on some other compilable, then
that other compilable will be run to completion before the stated
compiler is started. dependsOn will also cause the
compilable (say, compiler) to be run if the whole job is started; but
the compiler is just another dependency of the whole compiler job (and
thus might be run in parallel with some other dependency of the
job). This is why compiler types should generally use add
and not dependsOn (in case some other code adds a
dependency from the job).