Cluster Setting
Distributed Architecture
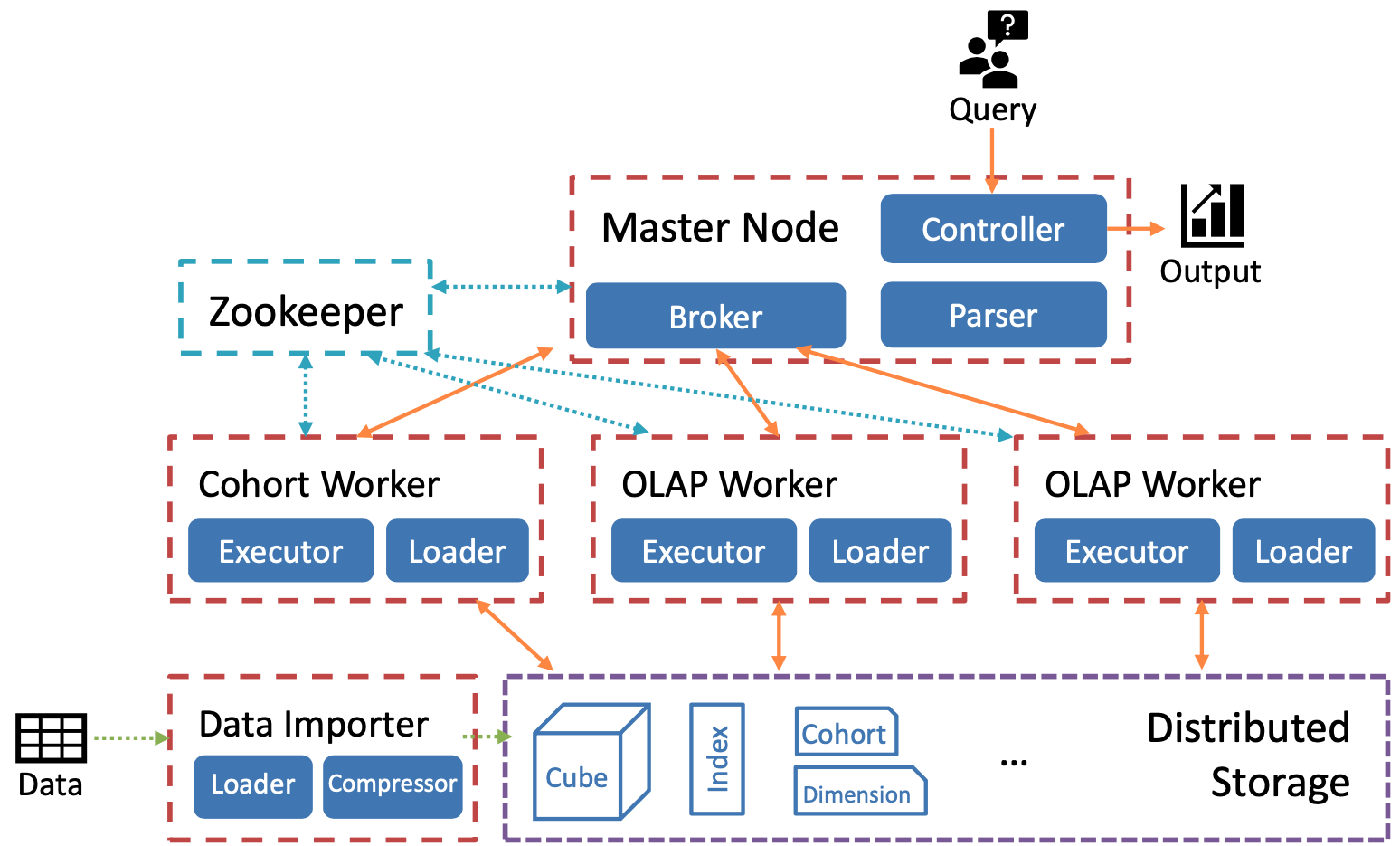
Distributed Operation
COOL can also be deployed as a scalable, distributed cluster.
Requirements
zookeeper, hdfs
Deployment
Deploy HDFS
Follow the Pseudo-distributed Operation instruction
Deploy zookeeper
Follow zookeeper started guide
Update Cfg
Update configuration at conf/app.properties
Update hdfs.host, zookeeper.host, and server host
RUN broker and worker in COOL
Run many workers, each worker has a unique port
java -jar cool-queryserver/target/cool-queryserver-0.0.1-SNAPSHOT.jar datasetSource/ 9011 WORKERjava -jar cool-queryserver/target/cool-queryserver-0.0.1-SNAPSHOT.jar datasetSource/ 9012 WORKERRun broker
java -jar cool-queryserver/target/cool-queryserver-0.0.1-SNAPSHOT.jar datasetSource/ 9013 BROKER
Datasets
Manually upload used Cublet, query.json file to HDFS, or use the following APIs to upload data, table.yaml, and query to HDFS.
- Upload all partitioned .dz files to HDFS path:
/cube/eg."/cube/health/v1/1805b2fdb75v2.dz","/cube/health/v1/1804bc18968.dz" - Upload query.json file to
/tmp/queryIDfolder, eg."/tmp/1/query.json" - Upload table.yaml file to same folder of cube, eg,
"/cube/health/v1/table.yaml"
API
In distributed mode, the client can only talk to the broker.
[server:port]: broker/load-data-to-hdfs
Upload data and table into HDFS for future usage.
This API requires the CSV and table.YAML files are already on the server-side.
curl --location --request POST 'http://127.0.0.1:9013/broker/load-data-to-hdfs' \
--header 'Content-Type: application/json' \
--data-raw '{"dataFileType": "CSV", "cubeName": "health", "schemaPath": "health/table.yaml", "dimPath": "health/dim.csv", "dataPath": "health/raw2.csv", "outputPath": "datasetSource"}'[server:port]: broker/load-query-to-hdfs
Upload the query file into HDFS for the future query.
curl --location --request POST 'http://127.0.0.1:9013/broker/load-query-to-hdfs' \
--header 'Content-Type: multipart/form-data' \
--form 'queryFile=@"FULL_PATH_PREFIX/COOL/health/query.json"'[server:port]: info
- List all workable urls
curl --location --request GET 'http://localhost:9013/info'[server:port]: /cohort/cohort-analysis
- Perform distributed cohort analysis
curl --location --request GET 'http://127.0.0.1:9013/broker/execute?queryId=1&type=cohort'- Result is stored at HDFS.