Release 3 (8.1.7)
Part Number A83728-01
Library |
Product |
Contents |
Index |
| Oracle8i Java Developer's Guide Release 3 (8.1.7) Part Number A83728-01 |
|
![]()
![]()
![]()
The way your client calls a Java method depends on the type of Java application. The following sections discuss each of the Java APIs available for creating a Java class that can be loaded into the database and accessed by your client:
You execute Java stored procedures similarly to PL/SQL. Normally, calling a Java stored procedure is a by-product of database manipulation in that it is usually the result of a trigger or DML call.
To invoke a Java stored procedure, you must publish it through a call specification. The following example shows how to create, resolve, load, and publish a simple Java stored procedure that echoes "Hello world".
Define a class, Hello, with one method, Hello.world(), that returns the string "Hello world".
public class Hello { public static String world () { return "Hello world"; } }
javac, as follows:
javac Hello.java
Normally, it is a good idea to specify your CLASSPATH on the javac command line, especially when writing shell scripts or make files. The Java compiler produces a Java binary file--in this case, Hello.class.
Keep in mind where this Java code will execute. If you execute Hello.class on your client system, it searches the CLASSPATH for all supporting core classes it must execute. This search should result in locating the dependent class in one of the following:
In this case, you load Hello.class in the server, where it is stored in the database as a Java schema object. When you execute the world() method of the Hello.class on the server, it finds the necessary supporting classes, such as String, using a resolver--in this case, the default resolver. The default resolver looks for classes in the current schema first and then in PUBLIC. All core class libraries, including the java.lang package, are found in PUBLIC. You may need to specify different resolvers, and you can force resolution to occur when you use loadjava, to determine if there are any problems earlier, rather than at runtime. Refer to "Resolving Class Dependencies" or the Oracle8i Java Tools Reference for more details on resolvers and loadjava.
loadjava. You must specify the username and password.
loadjava -user scott/tiger Hello.class
To invoke a Java static method with a SQL CALL, you must publish it with a call specification. A call specification defines for SQL which arguments the method takes and the SQL types it returns.
In SQL*Plus, connect to the database and define a top-level call specification for Hello.world():
SQL> connect scott/tiger connected SQL> create or replace function HELLOWORLD return VARCHAR2 as 2 language java name 'Hello.world () return java.lang.String'; 3 / Function created.
SQL> variable myString varchar2[20]; SQL> call HELLOWORLD() into :myString; Call completed. SQL> print myString; MYSTRING --------------------------------------- Hello world SQL>
The call HELLOWORLD() into :myString statement performs a top-level call in Oracle8i. The Oracle-specific select HELLOWORLD from DUAL also works. Note that SQL and PL/SQL see no difference between a stored procedure written in Java, PL/SQL, or any other language. The call specification provides a means to tie inter-language calls together in a consistent manner. Call specifications are necessary only for entry points invoked with triggers or SQL and PL/SQL calls. Furthermore, JDeveloper can automate the task of writing call specifications.
For more information on Java stored procedures, using Java in triggers, call specifications, rights models, and inter-language calls, refer to the Oracle8i Java Stored Procedures Developer's Guide.
In a program whose logic is distributed, the architecture of choice has three tiers--the client, the middle tier, and the database server.
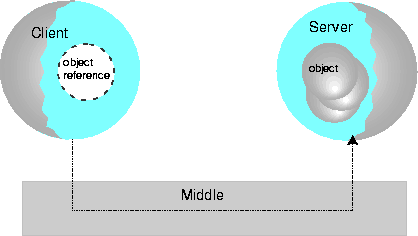
The server object within the three-tier model does the business logic. This may or may not include accessing a database for SQL queries. Oracle8i removes the need for a physical middle tier for distributed applications where the server object requires access to a database. Oracle8i still maintains a three-tier logical architecture, but by combining the middle tier and the database server, the physical architecture is two-tier. The flexibility inherent in this architecture is ideally suited to Internet applications where the client presents information in a Web browser, interacting with servers across the network. Those servers, in turn, can be federated and cooperate in their own client-server interactions to provide information to Web-based clients in an intranet or Internet application.
To use the two-tier distributed object approach for your application, you can use either the CORBA or EJB APIs.
An EJB programmer writes business logic and the interfaces to the component; a deployment tool, deployejb, loads and publishes the component. No knowledge of IDL is necessary. This portable Java-based server framework provides a fast, scalable, and easy solution to Java-based, three-tier applications.
CORBA and EJB are complementary. The JServer implementation of the Enterprise JavaBeans 1.1 specification builds on the underlying support and services of CORBA.
Unlike a session in which the client communicates through Net8, you access CORBA and EJB sessions through IIOP, which is capable of servicing multiple client connections. Although scalable applications generally provide one session per client-server interaction, the ability to service multiple clients extends the flexibility of the session. IIOP enables callouts, callbacks, and loopbacks in your distributed communications.
You can access components through a name service, which forms a tree, similar to a file system, where you can store objects by name. When you put a CORBA or EJB object into the namespace, you are publishing it.
There are two supported naming protocols within Oracle8i:
CORBA and EJB application development are complicated topics covered in the Oracle8i Enterprise JavaBeans Developer's Guide and Reference and the Oracle8i CORBA Developer's Guide and Reference. This section gives an example of how to create an EJB component. This example creates an EmployeeBean to look up an employee record in the Oracle RDBMS.
getEmployee(). You write a bean by creating a class that implements the SessionBean interface.
deployejb tool ensures that the server enforces them.
deployejb tool does the following:
Once you create and deploy an EJB, you will want to use it from a client program. You can use EJBs between servers in n-tier applications also, in which case the client for one server can also be the server for other clients. In your client code, you must perform the following steps:
create() methods to return an activated instance of the EJB.
java.io.Serializable.
The Oracle8i Enterprise JavaBeans Developer's Guide and Reference and the Oracle8i CORBA Developer's Guide and Reference books discuss the details of these steps. Java IDEs, as with Oracle's JDeveloper, can automate and simplify the deployment and descriptor process.
Session shell is an example of a tool written completely in Java using Java stored procedures and CORBA. It interacts with server-resident objects that are visible through CORBA within your session by using UNIX shell commands. For more information, see the The Oracle8i Enterprise JavaBeans Developer's Guide and Reference and the Oracle8i CORBA Developer's Guide and Reference books. This tool demonstrates how you can use CORBA to build tools that make life simpler for developers and end users.
The session shell provides a shell-like interface to the server. This shell allows users to manipulate the session namespace with familiar UNIX commands, such as mkdir, ls, and rm. In addition, the session shell furnishes a convenient way to run Java programs in the server, using the java command. The session shell java command takes the name of a class and any arguments the user types in. The session shell calls the static main(String[]) method on the class, running the Java program in the server. System.out and System.err are captured and transparently redirected back to the user's console.
JServer fully supports Java Remote Method Invocation (RMI). All RMI classes and java.net support are in place. In general, RMI is not useful or scalable in JServer applications. CORBA and EJB are the preferred APIs for invoking methods of remote objects. The RMI Server that Sun Microsystem supplies does function on the JServer platform. Because Sun Microsystem's RMI Server uses operating system sockets and is not accessible through a presentation, it is useful only within the context of a single call. It relies heavily on Java language level threads. By contrast, the Oracle8i ORB and EJB rely on the database server to gain scalability. You can efficiently implement an RMI server as a presentation; however, CORBA and EJB currently serves this purpose.
|
Note: A presentation is an object that accepts either a Net8 or IIOP incoming connection into the database. See "Configuring JServer" for more information. |
The Java Native Interface (JNI) is a standard programming interface for writing Java native methods and embedding the Java virtual machine into native applications. The primary goal of JNI is to provide binary compatibility of Java applications that use platform-specific native libraries.
Oracle does not support the use of JNI in JServer applications. If you use JNI, your application is not 100% pure Java, and the native methods require porting between platforms. Native methods have the potential for crashing the server, violating security, and corrupting data.
You can use one of two protocols for querying the database from a Java client. Both protocols establish a session with a given username/password to the database and execute SQL queries against the database.
JDBC is an industry-standard API developed by Sun Microsystems that allows you to embed SQL statements as Java method arguments. JDBC is based on the X/Open SQL Call Level Interface and complies with the SQL92 Entry Level standard. Each vendor, such as Oracle, creates its JDBC implementation by implementing the interfaces of the Sun Microsystems java.sql package. Oracle offers three JDBC drivers that implement these standard interfaces:
For the developer, using JDBC is a step-by-step process of creating a statement object of some type for your desired SQL operation, assigning any local variables that you want to bind to the SQL operation, and then executing the operation. This process is sufficient for many applications but becomes cumbersome for any complicated statements. Dynamic SQL operations, where the operations are not known until runtime, require JDBC. In typical applications, however, this represents a minority of the SQL operations.
SQLJ offers an industry-standard way to embed any static SQL operation directly into Java source code in one simple step, without requiring the individual steps of JDBC. Oracle SQLJ complies with ANSI standard X3H2-98-320.
SQLJ consists of a translator--a precompiler that supports standard SQLJ programming syntax--and a runtime component. After creating your SQLJ source code in a .sqlj file, you process it with the translator, which translates your SQLJ source code to standard Java source code, with SQL operations converted to calls to the SQLJ runtime. In the Oracle SQLJ implementation, the translator invokes a Java compiler to compile the Java source. When your Oracle SQLJ application runs, the SQLJ runtime calls JDBC to communicate with the database.
SQLJ also allows you to catch errors in your SQL statements before runtime. JDBC code, being pure Java, is compiled directly. The compiler has no knowledge of SQL, so it is unaware of any SQL errors. By contrast, when you translate SQLJ code, the translator analyzes the embedded SQL statements semantically and syntactically, catching SQL errors during development, instead of allowing an end-user to catch them when running the application.
The following is an example of a simple operation, first in JDBC code and then SQLJ code.
JDBC:
// (Presume you already have a JDBC Connection object conn) // Define Java variables String name; int id=37115; float salary=20000; // Set up JDBC prepared statement. PreparedStatement pstmt = conn.prepareStatement ("select ename from emp where empno=? and sal>?"); pstmt.setInt(1, id); pstmt.setFloat(2, salary); // Execute query; retrieve name and assign it to Java variable. ResultSet rs = pstmt.executeQuery(); while (rs.next()) { name=rs.getString(1); System.out.println("Name is: " + name); } // Close result set and statement objects. rs.close() pstmt.close();
name, id, and salary.
prepareStatement() method of the connection object).
You can use a prepared statement whenever values within the SQL statement must be dynamically set (you can use the same prepared statement repeatedly with different variable values). The question marks in the prepared statement are placeholders for Java variables and are given values in the pstmt.setInt() and pstmt.setFloat() lines of code. The first "?" is set to the int variable id (with a value of 37115). The second "?" is set to the float variable salary (with a value of 20000).
By comparison, here is some SQLJ code that performs the same task. Note that all SQLJ statements, both declarations and executable statements, start with the #sql token.
SQLJ:
String name; int id=37115; float salary=20000; #sql {select ename into :name from emp where empno=:id and sal>:salary}; System.out.println("Name is: " + name);
SQLJ, in addition to allowing SQL statements to be directly embedded in Java code, supports Java host expressions (also known as bind expressions) to be used directly in the SQL statements. In the simplest case, a host expression is a simple variable as in this example, but more complex expressions are allowed as well. Each host expression is preceded by ":" (colon). This example uses Java host expressions name, id, and salary. In SQLJ, because of its host expression support, you do not need a result set or equivalent when you are returning only a single row of data.
This section presents a complete example of a simple SQLJ program:
import java.sql.*; import sqlj.runtime.ref.DefaultContext; import oracle.sqlj.runtime.Oracle; #sql iterator MyIter (String ename, int empno, float sal); public class MyExample { public static void main (String args[]) throws SQLException { Oracle.connect ("jdbc:oracle:thin:@oow11:5521:sol2", "scott", "tiger"); #sql { insert into emp (ename, empno, sal) values ('SALMAN', 32, 20000) }; MyIter iter; #sql iter={ select ename, empno, sal from emp }; while (iter.next()) { System.out.println (iter.ename()+" "+iter.empno()+" "+iter.sal()); } } }
#sql iterator MyIter (String ename, int empno, float sal);
This declaration results in SQLJ creating an iterator class MyIter. Iterators of type MyIter can store results whose first column maps to a Java String, whose second column maps to a Java int, and whose third column maps to a Java float. This definition also names the three columns--ename, empno, and sal, respectively--to match the table column names in the database. MyIter is a named iterator. See Chapter 3 of the Oracle8i SQLJ Developer's Guide and Reference to learn about positional iterators, which do not require column names.
Oracle.connect("jdbc:oracle:thin:@oow11:5521:sol2","scott", "tiger");
Oracle SQLJ furnishes the Oracle class, and its connect() method accomplishes three important things:
scott, password tiger) at the specified URL (host oow11, port 5521, SID so12, "thin" JDBC driver).
while (iter.next()){ System.out.println(iter.ename()+" "+iter.empno()+" "+iter.sal()); }
The next() method is common to all iterators and plays the same role as the next() method of a JDBC result set, returning true and moving to the next row of data if any rows remain. You access the data in each row by calling iterator accessor methods whose names match the column names (this is a characteristic of all named iterators). In this example, you access the data using the methods ename(), empno(), and sal().
SQLJ uses strong typing--such as iterators--instead of result sets, which allows your SQL instructions to be checked against the database during translation. For example, SQLJ can connect to a database and check your iterators against the database tables that will be queried. The translator will verify that they match, allowing you to catch SQL errors during translation that would otherwise not be caught until a user runs your application. Furthermore, if changes are subsequently made to the schema, you can determine if this affects the application simply by re-running the translator.
Integrated development environments such as Oracle JDeveloper, a Windows-based visual development environment for Java programming, can translate, compile, and customize your SQLJ program for you as you build it. If you are not using an IDE, then you can use the front-end SQLJ utility, sqlj. You can run it as follows:
%sqlj MyExample.sqlj
The SQLJ translator checks the syntax and semantics of your SQL operations. You can enable online checking to check your operations against the database. If you choose to do this, you must specify an example database schema in your translator option settings. It is not necessary for the schema to have identical data to the one the program will eventually run against; however, the tables should have columns with corresponding names and datatypes. Use the user option to enable online checking and specify the username, password, and URL of your schema, as in the following example:
%sqlj -user=scott/tiger@jdbc:oracle:thin:@oow11:5521:sol2 MyExample.sqlj
Many SQLJ applications run on a client; however, SQLJ offers an advantage in programming stored procedures--which are usually SQL-intensive--to run in the server.
There is almost no difference between coding for a client-side SQLJ program and a server-side SQLJ program. The SQLJ runtime packages are automatically available on the server, and there are just the following few considerations:
System.out in a deployed server application.
To run a SQLJ program in the server, presuming you developed the code on a client, you have two options:
.jar file first.
In either case, you can use the Oracle loadjava utility to load the file or files to the server. See the Oracle8i SQLJ Developer's Guide and Reference for more information.
The steps in converting an existing SQLJ client-side application to run in the server are as follows. Assume this is an application that has already been translated on the client:
.jar file for your application components.
loadjava utility to load the .jar file to the server.
MyExample application in the server:
create or replace procedure SQLJ_MYEXAMPLE as language javaname `MyExample.main(java.lang.String[])';
You can then execute SQLJ_MYEXAMPLE as with any other stored procedure.
All the Oracle JDBC drivers communicate seamlessly with Oracle SQL and PL/SQL, and it is important to note that SQLJ interoperates with PL/SQL. You can start using SQLJ without having to rewrite any PL/SQL stored procedures. Oracle SQLJ includes syntax for calling PL/SQL stored procedures and also allows PL/SQL anonymous blocks to be embedded in SQLJ executable statements, just as with SQL operations.
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|