Release 3 (8.1.7)
Part Number A85397-01
Library |
Product |
Contents |
Index |
| Oracle8i SQL Reference Release 3 (8.1.7) Part Number A85397-01 |
|
![]()
![]()
![]()
SQL Statements:
CREATE CLUSTER to CREATE SEQUENCE, 2 of 25
Use the CREATE CLUSTER statement to create a cluster. A cluster is a schema object that contains data from one or more tables, all of which have one or more columns in common. Oracle stores together all the rows (from all the tables) that share the same cluster key.
For information on existing clusters, query the USER_CLUSTERS, ALL_CLUSTERS, and DBA_CLUSTERS data dictionary views.
|
See Also:
|
To create a cluster in your own schema, you must have CREATE CLUSTER system privilege. To create a cluster in another user's schema, you must have CREATE ANY CLUSTER system privilege. Also, the owner of the schema to contain the cluster must have either space quota on the tablespace containing the cluster or UNLIMITED TABLESPACE system privilege.
Oracle does not automatically create an index for a cluster when the cluster is initially created. Data manipulation language (DML) statements cannot be issued against clustered tables until a cluster index has been created.
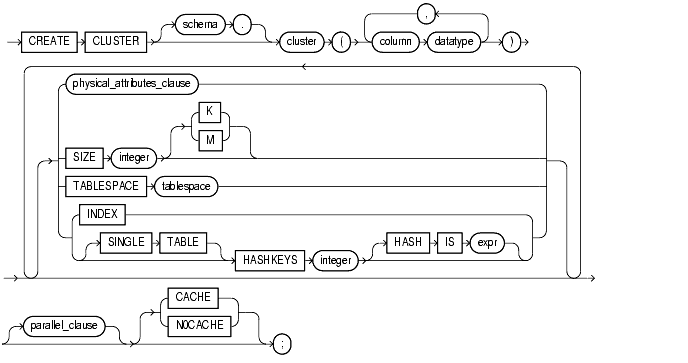

storage_clause: See the storage_clause.

schema
Specify the schema to contain the cluster. If you omit schema, Oracle creates the cluster in your current schema.
cluster
Specify is the name of the cluster to be created.
After you create a cluster, you add tables to it. A cluster can contain a maximum of 32 tables. After you create a cluster and add tables to it, the cluster is transparent. You can access clustered tables with SQL statements just as you can nonclustered tables.
column
Specify one or more names of columns in the cluster key. You can specify up to 16 cluster key columns. These columns must correspond in both datatype and size to columns in each of the clustered tables, although they need not correspond in name.
You cannot specify integrity constraints as part of the definition of a cluster key column. Instead, you can associate integrity constraints with the tables that belong to the cluster.
datatype
Specify the datatype of each cluster key column.
Restrictions:
LONG, LONG RAW, REF, nested table, varray, BLOB, CLOB, BFILE, or user-defined object type.
HASH IS clause if any column datatype is not INTEGER or NUMBER with scale 0.
ROWID, but Oracle does not guarantee that the values in such columns are valid rowids.
physical_attributes_clause
The physical_attributes_clause lets you specify the storage characteristics of the cluster. Each table in the cluster uses these storage characteristics as well.
|
|
Specify the limit that Oracle should use to determine when additional rows can be added to a cluster's data block. The value of this parameter is expressed as a whole number and interpreted as a percentage. |
|
|
|
Specify the space to be reserved in each of the cluster's data blocks for future expansion. The value of the parameter is expressed as a whole number and interpreted as a percentage. |
|
|
|
Specify the initial number of concurrent update transactions allocated for data blocks of the cluster. The value of this parameter for a cluster cannot be less than 2 or more than the value of the |
|
|
|
Specify the maximum number of concurrent update transactions for any given data block belonging to the cluster. The value of this parameter cannot be less than the value of the |
|
|
||
|
|
The |
|
SIZE
Specify the amount of space in bytes to store all rows with the same cluster key value or the same hash value. Use K or M to specify this space in kilobytes or megabytes. This space determines the maximum number of cluster or hash values stored in a data block. If SIZE is not a divisor of the data block size, Oracle uses the next largest divisor. If SIZE is larger than the data block size, Oracle uses the operating system block size, reserving at least one data block per cluster or hash value.
Oracle also considers the length of the cluster key when determining how much space to reserve for the rows having a cluster key value. Larger cluster keys require larger sizes. To see the actual size, query the KEY_SIZE column of the USER_CLUSTERS data dictionary view. (This does not apply to hash clusters, because hash values are not actually stored in the cluster.)
If you omit this parameter, Oracle reserves one data block for each cluster key value or hash value.
TABLESPACE
Specify the tablespace in which the cluster is created.
INDEX | HASH
|
|
Specify After you create an indexed cluster, you must create an index on the cluster key before you can issue any data manipulation language (DML) statements against a table in the cluster. This index is called the cluster index. |
|
|
|
|
|
|
|
Specify the
Oracle rounds up the
When you create a hash cluster, Oracle immediately allocates space for the cluster based on the values of the
|
|
|
|
|
Restriction: Only one table can be present in the cluster at a time. However, you can drop the table and create a different table in the same cluster. |
|
|
|
Specify an expression to be used as the hash function for the hash cluster. The expression: |
|
|
|
|
|
|
|
|
|
|
If you omit the
For information on existing hash functions, query the
|
|
|
|
The cluster key of a hash column can have one or more columns of any datatype. Hash clusters with composite cluster keys or cluster keys made up of noninteger columns must use the internal hash function. |
|
parallel_clause
The parallel_clause lets you parallelize the creation of the cluster.
Restriction: If the tables in cluster contain any columns of LOB or user-defined object type, this statement as well as subsequent INSERT, UPDATE, or DELETE operations on cluster are executed serially without notification.
CACHE | NOCACHE
The following statement creates an indexed cluster named personnel with the cluster key column department_number, a cluster size of 512 bytes, and storage parameter values:
CREATE CLUSTER personnel ( department_number NUMBER(2) ) SIZE 512 STORAGE (INITIAL 100K NEXT 50K);
The following statements add the emp and dept tables to the cluster:
CREATE TABLE emp (empno NUMBER PRIMARY KEY, ename VARCHAR2(10) NOT NULL CHECK (ename = UPPER(ename)), job VARCHAR2(9), mgr NUMBER REFERENCES scott.emp(empno), hiredate DATE CHECK (hiredate < TO_DATE ('08-14-1998', 'MM-DD-YYYY')), sal NUMBER(10,2) CHECK (sal > 500), comm NUMBER(9,0) DEFAULT NULL, deptno NUMBER(2) NOT NULL ) CLUSTER personnel (deptno); CREATE TABLE dept (deptno NUMBER(2), dname VARCHAR2(9), loc VARCHAR2(9)) CLUSTER personnel (deptno);
The following statement creates the cluster index on the cluster key of personnel:
CREATE INDEX idx_personnel ON CLUSTER personnel;
After creating the cluster index, you can insert rows into either the emp or dept tables.
The following statement creates a hash cluster named personnel with the cluster key column department_number, a maximum of 503 hash key values, each of which is allocated 512 bytes, and storage parameter values:
CREATE CLUSTER personnel ( department_number NUMBER ) SIZE 512 HASHKEYS 500 STORAGE (INITIAL 100K NEXT 50K);
Because the above statement omits the HASH IS clause, Oracle uses the internal hash function for the cluster.
The following statement creates a hash cluster named personnel with the cluster key made up of the columns home_area_code and home_prefix, and uses a SQL expression containing these columns for the hash function:
CREATE CLUSTER personnel ( home_area_code NUMBER, home_prefix NUMBER ) HASHKEYS 20 HASH IS MOD(home_area_code + home_prefix, 101);
The following statement creates a single-table hash cluster named personnel with the cluster key deptno and a maximum of 503 hash key values, each of which is allocated 512 bytes:
CREATE CLUSTER personnel (deptno NUMBER) SIZE 512 SINGLE TABLE HASHKEYS 500;
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|