Release 3 (8.1.7)
Part Number A85397-01
Library |
Product |
Contents |
Index |
| Oracle8i SQL Reference Release 3 (8.1.7) Part Number A85397-01 |
|
![]()
![]()
This chapter contains reference information on the basic elements of Oracle SQL. These elements are simplest building blocks of SQL statements. Therefore, before using the statements described in Chapter 7 through Chapter 11, you should familiarize yourself with the concepts covered in this chapter, as well as in Chapter 3, "Operators", Chapter 4, "Functions", Chapter 5, "Expressions, Conditions, and Queries", and Chapter 6, "About SQL Statements".
This chapter contains these sections:
Each value manipulated by Oracle has a datatype. A value's datatype associates a fixed set of properties with the value. These properties cause Oracle to treat values of one datatype differently from values of another. For example, you can add values of NUMBER datatype, but not values of RAW datatype.
When you create a table or cluster, you must specify a datatype for each of its columns. When you create a procedure or stored function, you must specify a datatype for each of its arguments. These datatypes define the domain of values that each column can contain or each argument can have. For example, DATE columns cannot accept the value February 29 (except for a leap year) or the values 2 or 'SHOE'. Each value subsequently placed in a column assumes the column's datatype. For example, if you insert '01-JAN-98' into a DATE column, Oracle treats the '01-JAN-98' character string as a DATE value after verifying that it translates to a valid date.
Oracle provides a number of built-in datatypes as well as several categories for user-defined types, as shown in Figure 2-1.
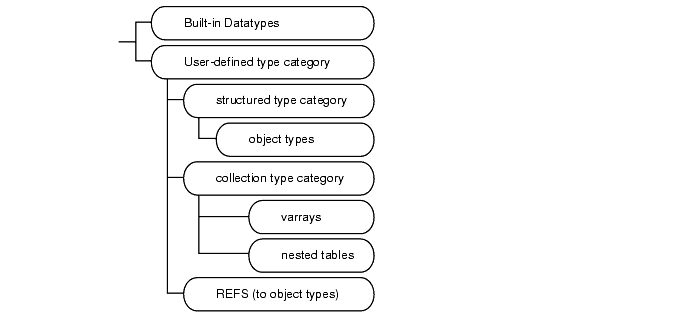
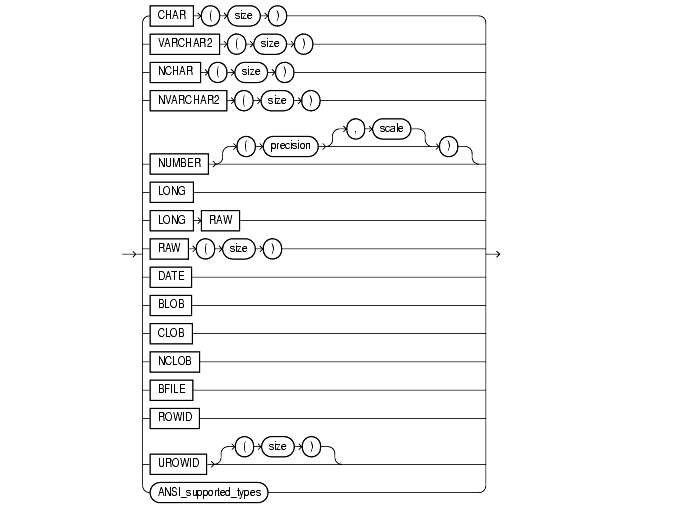
The syntax of the Oracle built-in datatypes appears in the next diagram. Table 2-1 summarizes Oracle built-in datatypes. The rest of this section describes these datatypes as well as the various kinds of user-defined types.
|
Note: The Oracle precompilers recognize other datatypes in embedded SQL programs. These datatypes are called external datatypes and are associated with host variables. Do not confuse built-in and user-defined datatypes with external datatypes. For information on external datatypes, including how Oracle converts between them and built-in or user-defined datatypes, see Pro*COBOL Precompiler Programmer's Guide, Pro*C/C++ Precompiler Programmer's Guide, and SQL*Module for Ada Programmer's Guide. |
built-in datatypes:
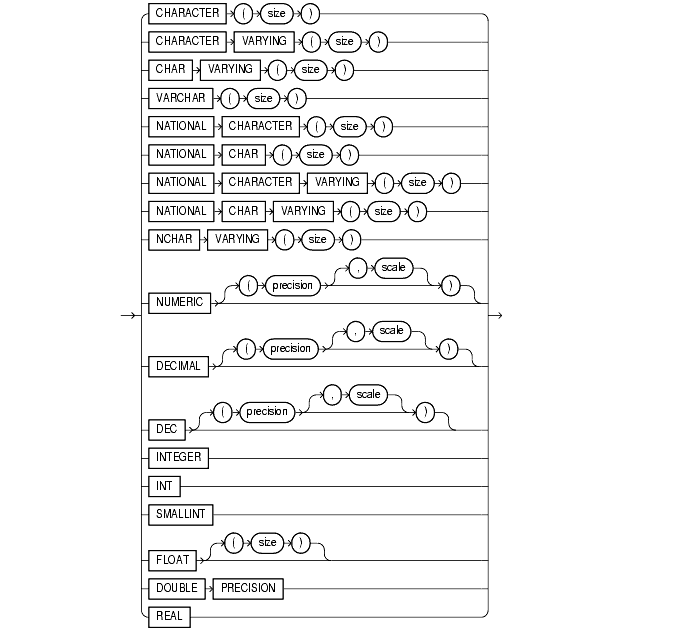
The ANSI-supported datatypes appear in the figure that follows. Table 2-2 shows the mapping of ANSI-supported datatypes to Oracle build-in datatypes.
ANSI-supported datatypes:
Character datatypes store character (alphanumeric) data, which are words and free-form text, in the database character set or national character set. They are less restrictive than other datatypes and consequently have fewer properties. For example, character columns can store all alphanumeric values, but NUMBER columns can store only numeric values.
Character data is stored in strings with byte values corresponding to one of the character sets, such as 7-bit ASCII or EBCDIC, specified when the database was created. Oracle supports both single-byte and multibyte character sets.
These datatypes are used for character data:
The CHAR datatype specifies a fixed-length character string. When you create a table with a CHAR column, you supply the column length in bytes. Oracle subsequently ensures that all values stored in that column have this length. If you insert a value that is shorter than the column length, Oracle blank-pads the value to column length. If you try to insert a value that is too long for the column, Oracle returns an error.
The default length for a CHAR column is 1 character and the maximum allowed is 2000 characters. A zero-length string can be inserted into a CHAR column, but the column is blank-padded to 1 character when used in comparisons.
|
Note: To ensure proper data conversion between databases with different character sets, you must ensure that |
The NCHAR datatype specifies a fixed-length national character set character string. When you create a table with an NCHAR column, you define the column length either in characters or in bytes. You define the national character set when you create your database.
If the national character set of the database is fixed width, such as JA16EUCFIXED, then you declare the NCHAR column size as the number of characters desired for the string length. If the national character set is variable width, such as JA16SJIS, you declare the column size in bytes. The following statement creates a table with one NCHAR column that can store strings up to 30 characters in length using JA16EUCFIXED as the national character set:
CREATE TABLE tab1 (col1 NCHAR(30));
The column's maximum length is determined by the national character set definition. Width specifications of character datatype NCHAR refer to the number of characters if the national character set is fixed width and refer to the number of bytes if the national character set is variable width. The maximum column size allowed is 2000 bytes. For fixed-width, multibyte character sets, the maximum length of a column allowed is the number of characters that fit into no more than 2000 bytes.
If you insert a value that is shorter than the column length, Oracle blank-pads the value to column length. You cannot insert a CHAR value into an NCHAR column, nor can you insert an NCHAR value into a CHAR column.
The following example compares the col1 column of tab1 with national character set string 'NCHAR literal':
SELECT * FROM tab1 WHERE col1 = N'NCHAR literal';
The NVARCHAR2 datatype specifies a variable-length national character set character string. When you create a table with an NVARCHAR2 column, you supply the maximum number of characters or bytes it can hold. Oracle subsequently stores each value in the column exactly as you specify it, provided the value does not exceed the column's maximum length.
The column's maximum length is determined by the national character set definition. Width specifications of character datatype NVARCHAR2 refer to the number of characters if the national character set is fixed width and refer to the number of bytes if the national character set is variable width. The maximum column size allowed is 4000 bytes. For fixed-width, multibyte character sets, the maximum length of a column allowed is the number of characters that fit into no more than 4000 bytes.
The following statement creates a table with one NVARCHAR2 column of 2000 characters in length (stored as 4000 bytes, because each character takes two bytes) using JA16EUCFIXED as the national character set:
CREATE TABLE tab1 (col1 NVARCHAR2(2000));
The VARCHAR2 datatype specifies a variable-length character string. When you create a VARCHAR2 column, you supply the maximum number of bytes of data that it can hold. Oracle subsequently stores each value in the column exactly as you specify it, provided the value does not exceed the column's maximum length. If you try to insert a value that exceeds the specified length, Oracle returns an error.
You must specify a maximum length for a VARCHAR2 column. This maximum must be at least 1 byte, although the actual length of the string stored is permitted to be zero. The maximum length of VARCHAR2 data is 4000 bytes. Oracle compares VARCHAR2 values using nonpadded comparison semantics.
|
Note: To ensure proper data conversion between databases with different character sets, you must ensure that |
The VARCHAR datatype is currently synonymous with the VARCHAR2 datatype. Oracle recommends that you use VARCHAR2 rather than VARCHAR. In the future, VARCHAR might be defined as a separate datatype used for variable-length character strings compared with different comparison semantics.
The NUMBER datatype stores zero, positive, and negative fixed and floating-point numbers with magnitudes between 1.0 x 10-130 and 9.9...9 x 10125 (38 nines followed by 88 zeroes) with 38 digits of precision. If you specify an arithmetic expression whose value has a magnitude greater than or equal to 1.0 x 10126, Oracle returns an error.
Specify a fixed-point number using the following form:
NUMBER(p,s)
where:
p is the precision, or the total number of digits. Oracle guarantees the portability of numbers with precision ranging from 1 to 38.
s is the scale, or the number of digits to the right of the decimal point. The scale can range from -84 to 127.
Specify an integer using the following form:
Specify a floating-point number using the following form:
NUMBER is a floating-point number with decimal precision 38. Note that a scale value is not applicable for floating-point numbers.
Specify the scale and precision of a fixed-point number column for extra integrity checking on input. Specifying scale and precision does not force all values to a fixed length. If a value exceeds the precision, Oracle returns an error. If a value exceeds the scale, Oracle rounds it.
The following examples show how Oracle stores data using different precisions and scales.
If the scale is negative, the actual data is rounded to the specified number of places to the left of the decimal point. For example, a specification of (10,-2) means to round to hundreds.
You can specify a scale that is greater than precision, although it is uncommon. In this case, the precision specifies the maximum number of digits to the right of the decimal point. As with all number datatypes, if the value exceeds the precision, Oracle returns an error message. If the value exceeds the scale, Oracle rounds the value. For example, a column defined as NUMBER(4,5) requires a zero for the first digit after the decimal point and rounds all values past the fifth digit after the decimal point. The following examples show the effects of a scale greater than precision:
| Actual Data | Specified As | Stored As |
|
.01234 |
|
.01234 |
|
.00012 |
|
.00012 |
|
.000127 |
|
.00013 |
|
.0000012 |
|
.0000012 |
|
.00000123 |
|
.0000012 |
Oracle allows you to specify floating-point numbers, which can have a decimal point anywhere from the first to the last digit or can have no decimal point at all. A scale value is not applicable to floating-point numbers, because the number of digits that can appear after the decimal point is not restricted.
You can specify floating-point numbers with the form discussed in "NUMBER Datatype". Oracle also supports the ANSI datatype FLOAT. You can specify this datatype using one of these syntactic forms:
FLOAT specifies a floating-point number with decimal precision 38, or binary precision 126.
FLOAT(b) specifies a floating-point number with binary precision b. The precision b can range from 1 to 126. To convert from binary to decimal precision, multiply b by 0.30103. To convert from decimal to binary precision, multiply the decimal precision by 3.32193. The maximum of 126 digits of binary precision is roughly equivalent to 38 digits of decimal precision.
LONG columns store variable-length character strings containing up to 2 gigabytes, or 231-1 bytes. LONG columns have many of the characteristics of VARCHAR2 columns. You can use LONG columns to store long text strings. The length of LONG values may be limited by the memory available on your computer.
|
Note: Oracle Corporation strongly recommends that you convert |
You can reference LONG columns in SQL statements in these places:
The use of LONG values is subject to some restrictions:
LONG column.
LONG attribute.
LONG columns cannot appear in integrity constraints (except for NULL and NOT NULL constraints).
LONG columns cannot be indexed.
LONG value.
LONG columns, updated tables, and locked tables must be located on the same database.
LONG columns cannot appear in certain parts of SQL statements:
WHERE clauses, GROUP BY clauses, ORDER BY clauses, or CONNECT BY clauses or with the DISTINCT operator in SELECT statements
UNIQUE operator of a SELECT statement
CREATE CLUSTER statement
CLUSTER clause of a CREATE MATERIALIZED VIEW statement
SUBSTR or INSTR)
SELECT lists of queries containing GROUP BY clauses
SELECT lists of subqueries or queries combined by the UNION, INTERSECT, or MINUS set operators
SELECT lists of CREATE TABLE ... AS SELECT statements
SELECT lists in subqueries in INSERT statements
Triggers can use the LONG datatype in the following manner:
LONG column.
LONG column can be converted to a constrained datatype (such as CHAR and VARCHAR2), a LONG column can be referenced in a SQL statement within a trigger.
LONG datatype.
NEW and :OLD cannot be used with LONG columns.
You can use the Oracle Call Interface functions to retrieve a portion of a LONG value from the database.
The DATE datatype stores date and time information. Although date and time information can be represented in both CHAR and NUMBER datatypes, the DATE datatype has special associated properties. For each DATE value, Oracle stores the following information: century, year, month, day, hour, minute, and second.
If you specify a date value without a time component, the default time is 12:00:00 AM (midnight). If you specify a time value without a date, the default date is the first day of the current month. The date function SYSDATE returns the current date and time.
The default date format is specified by the initialization parameter NLS_DATE_FORMAT and is a string such as 'DD-MON-YY'. This example default date format includes a two-digit number for the day of the month, an abbreviation of the month name, and the last two digits of the year. Oracle automatically converts character values that are in the default date format into DATE values when they are used in date expressions.
To specify a date value that is not in the default format, you must convert a character or numeric value to a date value with the TO_DATE function. In this case, you must specify the nondefault date format model (sometimes called a "date mask") to tell Oracle how to interpret the character or numeric value. For example, the date format model for '17:45:29' is 'HH24:MI:SS'. The date format model for '11-NOV-1999' is 'DD-MON-YYYY'.
|
See Also:
|
You can add and subtract number constants as well as other dates from dates. Oracle interprets number constants in arithmetic date expressions as numbers of days. For example, SYSDATE + 1 is tomorrow. SYSDATE - 7 is one week ago. SYSDATE + (10/1440) is ten minutes from now. Subtracting the hiredate column of the emp table from SYSDATE returns the number of days since each employee was hired. You cannot multiply or divide DATE values.
Oracle provides functions for many common date operations. For example, the ADD_MONTHS function lets you add or subtract months from a date. The MONTHS_BETWEEN function returns the number of months between two dates. The fractional portion of the result represents that portion of a 31-day month.
Because each date contains a time component, most results of date operations include a fraction. This fraction means a portion of one day. For example, 1.5 days is 36 hours.
A Julian date is the number of days since January 1, 4712 BC. Julian dates allow continuous dating from a common reference. You can use the date format model "J" with date functions TO_DATE and TO_CHAR to convert between Oracle DATE values and their Julian equivalents.
This statement returns the Julian equivalent of January 1, 1997:
SELECT TO_CHAR(TO_DATE('01-01-1997', 'MM-DD-YYYY'),'J') FROM DUAL; TO_CHAR -------- 2450450
The RAW and LONG RAW datatypes store data that is not to be interpreted (not explicitly converted when moving data between different systems) by Oracle. These datatypes are intended for binary data or byte strings. For example, you can use LONG RAW to store graphics, sound, documents, or arrays of binary data, for which the interpretation is dependent on the use.
|
Note: Oracle Corporation strongly recommends that you convert |
RAW is a variable-length datatype like VARCHAR2, except that Net8 (which connects user sessions to the instance) and the Import and Export utilities do not perform character conversion when transmitting RAW or LONG RAW data. In contrast, Net8 and Import/Export automatically convert CHAR, VARCHAR2, and LONG data from the database character set to the user session character set (which you can set with the NLS_LANGUAGE parameter of the ALTER SESSION statement), if the two character sets are different.
When Oracle automatically converts RAW or LONG RAW data to and from CHAR data, the binary data is represented in hexadecimal form, with one hexadecimal character representing every four bits of RAW data. For example, one byte of RAW data with bits 11001011 is displayed and entered as 'CB'.
The built-in LOB datatypes BLOB, CLOB, and NCLOB (stored internally), and the BFILE (stored externally), can store large and unstructured data such as text, image, video, and spatial data up to 4 gigabytes in size.
When creating a table, you can optionally specify different tablespace and storage characteristics for LOB columns or LOB object attributes from those specified for the table.
LOB columns contain LOB locators that can refer to out-of-line or in-line LOB values. Selecting a LOB from a table actually returns the LOB's locator and not the entire LOB value. The DBMS_LOB package and Oracle Call Interface (OCI) operations on LOBs are performed through these locators.
LOBs are similar to LONG and LONG RAW types, but differ in the following ways:
BLOB, NCLOB, and CLOB values can be stored in separate tablespaces. BFILE data is stored in an external file on the server.
BFILE maximum size is operating system dependent, but cannot exceed 4 gigabytes.
NCLOB, you can define one or more LOB attributes in an object.
NULL, empty, or replace the entire LOB with data. You can set the BFILE to NULL or make it point to a different file.)
You can access and populate rows of an internal LOB column (a LOB column stored in the database) simply by issuing an INSERT or UPDATE statement. However, to access and populate a LOB attribute that is part of an object type, you must first initialize the LOB attribute using the EMPTY_CLOB or EMPTY_BLOB function. You can then select the empty LOB attribute and populate it using the DBMS_LOB package or some other appropriate interface.
The following example creates a table with LOB columns. (It assumes the existence of tablespace resumes).
CREATE TABLE person_table (name CHAR(40), resume CLOB, picture BLOB) LOB (resume) STORE AS ( TABLESPACE resumes STORAGE (INITIAL 5M NEXT 5M) );
|
See Also:
|
The BFILE datatype enables access to binary file LOBs that are stored in file systems outside the Oracle database. A BFILE column or attribute stores a BFILE locator, which serves as a pointer to a binary file on the server's file system. The locator maintains the directory alias and the filename.
Binary file LOBs do not participate in transactions and are not recoverable. Rather, the underlying operating system provides file integrity and durability. The maximum file size supported is 4 gigabytes.
The database administrator must ensure that the file exists and that Oracle processes have operating system read permissions on the file.
The BFILE datatype allows read-only support of large binary files. You cannot modify or replicate such a file. Oracle provides APIs to access file data. The primary interfaces that you use to access file data are the DBMS_LOB package and the OCI.
|
See Also:
|
The BLOB datatype stores unstructured binary large objects. BLOBs can be thought of as bitstreams with no character set semantics. BLOBs can store up to 4 gigabytes of binary data.
BLOBs have full transactional support. Changes made through SQL, the DBMS_LOB package, or the OCI participate fully in the transaction. BLOB value manipulations can be committed and rolled back. Note, however, that you cannot save a BLOB locator in a PL/SQL or OCI variable in one transaction and then use it in another transaction or session.
The CLOB datatype stores single-byte character data. Both fixed-width and variable-width character sets are supported, and both use the CHAR database character set. CLOBs can store up to 4 gigabytes of character data.
CLOBs have full transactional support. Changes made through SQL, the DBMS_LOB package, or the OCI participate fully in the transaction. CLOB value manipulations can be committed and rolled back. Note, however, that you cannot save a CLOB locator in a PL/SQL or OCI variable in one transaction and then use it in another transaction or session.
The NCLOB datatype stores multibyte national character set character (NCHAR) data. Both fixed-width and variable-width character sets are supported. NCLOBs can store up to 4 gigabytes of character text data.
NCLOBs have full transactional support. Changes made through SQL, the DBMS_LOB package, or the OCI participate fully in the transaction. NCLOB value manipulations can be committed and rolled back. Note, however, that you cannot save an NCLOB locator in a PL/SQL or OCI variable in one transaction and then use it in another transaction or session.
Each row in the database has an address. You can examine a row's address by querying the pseudocolumn ROWID. Values of this pseudocolumn are hexadecimal strings representing the address of each row. These strings have the datatype ROWID. You can also create tables and clusters that contain actual columns having the ROWID datatype. Oracle does not guarantee that the values of such columns are valid rowids.
Beginning with Oracle8, Oracle SQL incorporated an extended format for rowids to efficiently support partitioned tables and indexes and tablespace-relative data block addresses (DBAs) without ambiguity.
Character values representing rowids in Oracle7 and earlier releases are called restricted rowids. Their format is as follows:
block.row.file
where:
The extended ROWID datatype stored in a user column includes the data in the restricted rowid plus a data object number. The data object number is an identification number assigned to every database segment. You can retrieve the data object number from data dictionary views USER_OBJECTS, DBA_OBJECTS, and ALL_OBJECTS. Objects that share the same segment (clustered tables in the same cluster, for example) have the same object number.
Extended rowids are stored as base 64 values that can contain the characters A-Z, a-z, 0-9, as well as the plus sign (+) and forward slash (/). Extended rowids are not available directly. You can use a supplied package, DBMS_ROWID, to interpret extended rowid contents. The package functions extract and provide information that would be available directly from a restricted rowid, as well as information specific to extended rowids.
|
See Also: Oracle8i Supplied PL/SQL Packages Reference for information on the functions available with the |
The restricted form of a rowid is still supported in Oracle8i for backward compatibility, but all tables return rowids in the extended format.
Each row in a database has an address. However, the rows of some tables have addresses that are not physical or permanent, or were not generated by Oracle. For example, the row addresses of index-organized tables are stored in index leaves, which can move. Rowids of foreign tables (such as DB2 tables accessed through a gateway) are not standard Oracle rowids.
Oracle uses "universal rowids" (urowids) to store the addresses of index-organized and foreign tables. Index-organized tables have logical urowids and foreign tables have foreign urowids. Both types of urowid are stored in the ROWID pseudocolumn (as are the physical rowids of heap-organized tables).
Oracle creates logical rowids based on a table's primary key. The logical rowids do not change as long as the primary key does not change. The ROWID pseudocolumn of an index-organized table has a datatype of UROWID. You can access this pseudocolumn as you would the ROWID pseudocolumn of a heap-organized (that is, using the SELECT ROWID statement). If you wish to store the rowids of an index-organized table, you can define a column of type UROWID for the table and retrieve the value of the ROWID pseudocolumn into that column.
|
See Also:
|
SQL statements that create tables and clusters can also use ANSI datatypes and datatypes from IBM's products SQL/DS and DB2. Oracle recognizes the ANSI or IBM datatype name and records it as the name of the datatype of the column, and then stores the column's data in an Oracle datatype based on the conversions shown in Table 2-2 and Table 2-3.
Do not define columns with these SQL/DS and DB2 datatypes, because they have no corresponding Oracle datatype:
Note that data of type TIME and TIMESTAMP can also be expressed as Oracle DATE data.
User-defined datatypes use Oracle built-in datatypes and other user-defined datatypes as the building blocks of types that model the structure and behavior of data in applications.
The sections that follow describe the various categories of user-defined types.
|
See Also:
|
Object types are abstractions of the real-world entities, such as purchase orders, that application programs deal with. An object type is a schema object with three kinds of components:
An object identifier (OID) uniquely identifies an object and enables you to reference the object from other objects or from relational tables. A datatype category called REF represents such references. A REF is a container for an object identifier. REFs are pointers to objects.
When a REF value points to a nonexistent object, the REF is said to be "dangling". A dangling REF is different from a null REF. To determine whether a REF is dangling or not, use the predicate IS [NOT] DANGLING. For example, given table dept with column mgr whose type is a REF to type emp_t, which has an attribute name:
SELECT t.mgr.name FROM dept t WHERE t.mgr IS NOT DANGLING;
An array is an ordered set of data elements. All elements of a given array are of the same datatype. Each element has an index, which is a number corresponding to the element's position in the array.
The number of elements in an array is the size of the array. Oracle arrays are of variable size, which is why they are called varrays. You must specify a maximum size when you declare the array.
When you declare a varray, it does not allocate space. It defines a type, which you can use as:
Oracle normally stores an array object either in line (that is, as part of the row data) or out of line (in a LOB), depending on its size. However, if you specify separate storage characteristics for a varray, Oracle will store it out of line, regardless of its size.
A nested table type models an unordered set of elements. The elements may be built-in types or user-defined types. You can view a nested table as a single-column table or, if the nested table is an object type, as a multicolumn table, with a column for each attribute of the object type.
A nested table definition does not allocate space. It defines a type, which you can use to declare:
When a nested table appears as the type of a column in a relational table or as an attribute of the underlying object type of an object table, Oracle stores all of the nested table data in a single table, which it associates with the enclosing relational or object table.
This section describes how Oracle compares values of each datatype.
A larger value is considered greater than a smaller one. All negative numbers are less than zero and all positive numbers. Thus, -1 is less than 100; -100 is less than -1.
A later date is considered greater than an earlier one. For example, the date equivalent of '29-MAR-1997' is less than that of '05-JAN-1998' and '05-JAN-1998 1:35pm' is greater than '05-JAN-1998 10:09am'.
Character values are compared using one of these comparison rules:
The following sections explain these comparison semantics. The results of comparing two character values using different comparison semantics may vary. The table below shows the results of comparing five pairs of character values using each comparison semantic. Usually, the results of blank-padded and nonpadded comparisons are the same. The last comparison in the table illustrates the differences between the blank-padded and nonpadded comparison semantics.
| Blank-Padded | Nonpadded |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
'a ' = 'a' |
'a ' > 'a' |
If the two values have different lengths, Oracle first adds blanks to the end of the shorter one so their lengths are equal. Oracle then compares the values character by character up to the first character that differs. The value with the greater character in the first differing position is considered greater. If two values have no differing characters, then they are considered equal. This rule means that two values are equal if they differ only in the number of trailing blanks. Oracle uses blank-padded comparison semantics only when both values in the comparison are either expressions of datatype CHAR, NCHAR, text literals, or values returned by the USER function.
Oracle compares two values character by character up to the first character that differs. The value with the greater character in that position is considered greater. If two values of different length are identical up to the end of the shorter one, the longer value is considered greater. If two values of equal length have no differing characters, then the values are considered equal. Oracle uses nonpadded comparison semantics whenever one or both values in the comparison have the datatype VARCHAR2 or NVARCHAR2.
Oracle compares single characters according to their numeric values in the database character set. One character is greater than another if it has a greater numeric value than the other in the character set. Oracle considers blanks to be less than any character, which is true in most character sets.
These are some common character sets:
Portions of the ASCII and EBCDIC character sets appear in Table 2-4 and Table 2-5. Note that uppercase and lowercase letters are not equivalent. Also, note that the numeric values for the characters of a character set may not match the linguistic sequence for a particular language.
Object values are compared using one of two comparison functions: MAP and ORDER. Both functions compare object type instances, but they are quite different from one another. These functions must be specified as part of the object type.
|
See Also: "CREATE TYPE" and Oracle8i Application Developer's Guide - Fundamentals for a description of |
You cannot compare varrays and nested tables in Oracle8i.
Generally an expression cannot contain values of different datatypes. For example, an expression cannot multiply 5 by 10 and then add 'JAMES'. However, Oracle supports both implicit and explicit conversion of values from one datatype to another.
Oracle automatically converts a value from one datatype to another when such a conversion makes sense. Oracle performs conversions in these cases:
INSERT or UPDATE statement assigns a value of one datatype to a column of another, Oracle converts the value to the datatype of the column.
The text literal '10' has datatype CHAR. Oracle implicitly converts it to the NUMBER datatype if it appears in a numeric expression as in the following statement:
SELECT sal + '10' FROM emp;
When a condition compares a character value and a NUMBER value, Oracle implicitly converts the character value to a NUMBER value, rather than converting the NUMBER value to a character value. In the following statement, Oracle implicitly converts '7936' to 7936:
SELECT ename FROM emp WHERE empno = '7936';
In the following statement, Oracle implicitly converts '12-MAR-1993' to a DATE value using the default date format 'DD-MON-YYYY':
SELECT ename FROM emp WHERE hiredate = '12-MAR-1993';
In the following statement, Oracle implicitly converts the text literal 'AAAAZ8AABAAABvlAAA' to a rowid value:
SELECT ename FROM emp WHERE ROWID = 'AAAAZ8AABAAABvlAAA';
You can also explicitly specify datatype conversions using SQL conversion functions. Table 2-6 shows SQL functions that explicitly convert a value from one datatype to another.
|
Note: You cannot specify |
Oracle recommends that you specify explicit conversions rather than rely on implicit or automatic conversions for these reasons:
VARCHAR2 value may return an unexpected year depending on the value of the NLS_DATE_FORMAT parameter.
The terms literal and constant value are synonymous and refer to a fixed data value. For example, 'JACK', 'BLUE ISLAND', and '101' are all character literals; 5001 is a numeric literal. Note that character literals are enclosed in single quotation marks, which enable Oracle to distinguish them from schema object names.
This section contains these topics:
Many SQL statements and functions require you to specify character and numeric literal values. You can also specify literals as part of expressions and conditions. You can specify character literals with the 'text' notation, national character literals with the N'text' notation, and numeric literals with the integer or number notation, depending on the context of the literal. The syntactic forms of these notations appear in the sections that follow.
To specify a datetime or interval datatype as a literal, you must take into account any optional precisions included in the datatypes. Examples of specifying datetime and interval datatypes as literals are provided in the relevant sections of "Datatypes".
Text specifies a text or character literal. You must use this notation to specify values whenever 'text' or char appear in expressions, conditions, SQL functions, and SQL statements in other parts of this reference.
The syntax of text is as follows:
text::=
where
N specifies representation of the literal using the national character set. Text entered using this notation is translated into the national character set by Oracle when used.
c is any member of the user's character set, except a single quotation mark (').
A text literal must be enclosed in single quotation marks. This reference uses the terms text literal and character literal interchangeably.
Text literals have properties of both the CHAR and VARCHAR2 datatypes:
CHAR by comparing them using blank-padded comparison semantics.
Here are some valid text literals:
'Hello' 'ORACLE.dbs' 'Jackie''s raincoat' '09-MAR-98' N'nchar literal'
You must use the integer notation to specify an integer whenever integer appears in expressions, conditions, SQL functions, and SQL statements described in other parts of this reference.
The syntax of integer is as follows:
integer::=

where digit is one of 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
An integer can store a maximum of 38 digits of precision.
Here are some valid integers:
7 +255
You must use the number notation to specify values whenever number appears in expressions, conditions, SQL functions, and SQL statements in other parts of this reference.
The syntax of number is as follows:
number::=
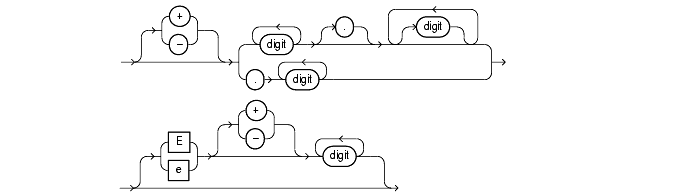
where
digit is one of 0, 1, 2, 3, 4, 5, 6, 7, 8 or 9.
A number can store a maximum of 38 digits of precision.
If you have established a decimal character other than a period (.) with the initialization parameter NLS_NUMERIC_CHARACTERS, you must specify numeric literals with 'text' notation. In such cases, Oracle automatically converts the text literal to a numeric value.
For example, if the NLS_NUMERIC_CHARACTERS parameter specifies a decimal character of comma, specify the number 5.123 as follows:
'5,123'
Here are some valid representations of number:
25 +6.34 0.5 25e-03 -1
An interval literal specifies a period of time. You can specify these differences in terms of years and months, or in terms of days, hours, minutes, and seconds. Oracle supports two types of interval literals, YEAR TO MONTH and DAY TO SECOND. Each type contains a leading field and may contain a trailing field. The leading field defines the basic unit of date or time being measured. The trailing field defines the smallest increment of the basic unit being considered. For example, a YEAR TO MONTH interval considers an interval of years to the nearest month. A DAY TO MINUTE interval considers an interval of days to the nearest minute.
If you have date data in numeric form, you can use the NUMTOYMINTERVAL or NUMTODSINTERVAL conversion function to convert the numeric data into interval literals.
Interval literals are used primarily with analytic functions.
Specify YEAR TO MONTH interval literals using the following syntax:
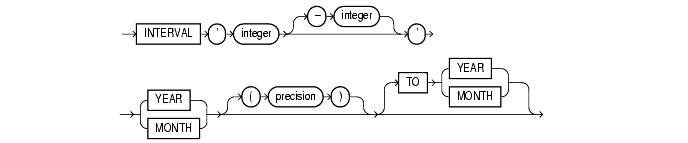
where
integer [-integer]' specifies integer values for the leading and optional trailing field of the literal. If the leading field is YEAR and the trailing field is MONTH, the range of integer values for the month field is 0 to 11.
precision is the number of digits in the leading field. The valid range of the leading field precision is 0 to 9 and its default value is 2.
The leading field must be a larger time element than the trailing field. For example, INTERVAL '0-1' MONTH TO YEAR is not valid.
The following INTERVAL YEAR TO MONTH literal indicates an interval of 123 years, 2 months:
INTERVAL '123-2' YEAR(3) TO MONTH
Examples of the other forms of the literal follow, including some abbreviated versions:
You can add or subtract one INTERVAL YEAR TO MONTH literal to or from another to yield another INTERVAL YEAR TO MONTH literal. For example:
INTERVAL '5-3' YEAR TO MONTH + INTERVAL '20' MONTH TO MONTH = INTERVAL '6-11' YEAR TO MONTH
Specify DAY TO SECOND interval literals using the following syntax:
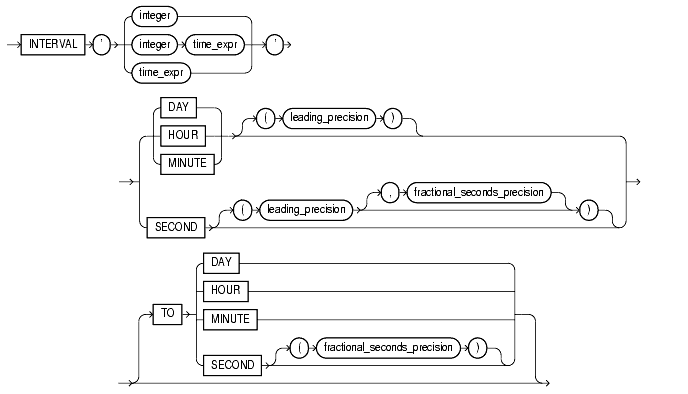
where
integer specifies the number of days. If this value contains more digits than the number specified by the leading precision, Oracle returns an error.
time_expr specifies a time in the format HH[:MI[:SS[.n]]]or MI[:SS[.n]] or SS[.n], where n specifies the fractional part of a second. If n contains more digits than the number specified by fractional_seconds_precision, then n is rounded to the number of digits specified by the fractional_seconds_precision value. You can specify time_expr following an integer and a space only if the leading field is DAY.
leading_precision is the number of digits in the leading field. Accepted values are 0 to 9. The default is 2.
fractional_seconds_precision is the number of digits in the fractional part of the SECOND datetime field. Accepted values are 1 to 9. The default is 6.
The leading field must be a larger time element than the trailing field. For example, INTERVAL MINUTE TO DAY is not valid. As a result of this restriction, if SECOND is the leading field, the interval literal cannot have any trailing field.
The valid range of values for the trailing field are as follows:
|
HOUR |
0 to 23 |
|
MINUTE |
0 to 59 |
|
SECOND |
0 to 59.999999999 |
Examples of the various forms of INTERVAL DAY TO SECOND literals follow, including some abbreviated versions:
You can add or subtract one DAY TO SECOND interval literal from another DAY TO SECOND literal. For example.
INTERVAL '20' DAY - INTERVAL '240' HOUR = INTERVAL '10' DAY
A format model is a character literal that describes the format of DATE or NUMBER data stored in a character string. When you convert a character string into a date or number, a format model tells Oracle how to interpret the string. In SQL statements, you can use a format model as an argument of the TO_CHAR and TO_DATE functions:
For example, the date format model for the string '17:45:29' is 'HH24:MI:SS'. The date format model for the string '11-Nov-1999' is 'DD-Mon-YYYY'. The number format model for the string '$2,304.25' is '$9,999.99'. For lists of date and number format model elements, see Table 2-7, "Number Format Elements" and Table 2-9, "Datetime Format Elements".
The values of some formats are determined by the value of initialization parameters. For such formats, you can specify the characters returned by these format elements implicitly using the initialization parameter NLS_TERRITORY. You can change the default date format for your session with the ALTER SESSION statement.
|
See Also:
|
You can use a format model to specify the format for Oracle to use to return values from the database to you.
The following statement selects the commission values of the employees in Department 30 and uses the TO_CHAR function to convert these commissions into character values with the format specified by the number format model '$9,990.99':
SELECT ename employee, TO_CHAR(comm, '$9,990.99') commission FROM emp WHERE deptno = 30; EMPLOYEE COMMISSION ---------- ---------- ALLEN $300.00 WARD $500.00 MARTIN $1,400.00 BLAKE TURNER $0.00 JAMES
Because of this format model, Oracle returns commissions with leading dollar signs, commas every three digits, and two decimal places. Note that TO_CHAR returns null for all employees with null in the comm column.
The following statement selects the date on which each employee from Department 20 was hired and uses the TO_CHAR function to convert these dates to character strings with the format specified by the date format model 'fmMonth DD, YYYY':
SELECT ename, TO_CHAR(Hiredate,'fmMonth DD, YYYY') hiredate FROM emp WHERE deptno = 20; ENAME HIREDATE ---------- ------------------ SMITH December 17, 1980 JONES April 2, 1981 SCOTT April 19, 1987 ADAMS May 23, 1987 FORD December 3, 1981 LEWIS October 23, 1997
With this format model, Oracle returns the hire dates (as specified by "fm") without blank padding, two digits for the day, and the century included in the year.
When you insert or update a column value, the datatype of the value that you specify must correspond to the column's datatype. You can use format models to specify the format of a value that you are converting from one datatype to another datatype required for a column.
For example, a value that you insert into a DATE column must be a value of the DATE datatype or a character string in the default date format (Oracle implicitly converts character strings in the default date format to the DATE datatype). If the value is in another format, you must use the TO_DATE function to convert the value to the DATE datatype. You must also use a format model to specify the format of the character string.
The following statement updates BAKER's hire date using the TO_DATE function with the format mask 'YYYY MM DD' to convert the character string '1998 05 20' to a DATE value:
UPDATE emp SET hiredate = TO_DATE('1998 05 20','YYYY MM DD') WHERE ename = 'BLAKE';
This remainder of this section describes how to use:
You can use number format models:
TO_CHAR function to translate a value of NUMBER datatype to VARCHAR2 datatype
TO_NUMBER function to translate a value of CHAR or VARCHAR2 datatype to NUMBER datatype
All number format models cause the number to be rounded to the specified number of significant digits. If a value has more significant digits to the left of the decimal place than are specified in the format, pound signs (#) replace the value. If a positive value is extremely large and cannot be represented in the specified format, then the infinity sign (~) replaces the value. Likewise, if a negative value is extremely small and cannot be represented by the specified format, then the negative infinity sign replaces the value (-~). This event typically occurs when you are using TO_CHAR with a restrictive number format string, causing a rounding operation.
A number format model is composed of one or more number format elements. Table 2-7 lists the elements of a number format model. Examples are shown in Table 2-8.
Negative return values automatically contain a leading negative sign and positive values automatically contain a leading space unless the format model contains the MI, S, or PR format element.
Table 2-8 shows the results of the following query for different values of number and 'fmt':
SELECT TO_CHAR(number, 'fmt') FROM DUAL;
You can use date format models:
TO_DATE function to translate a character value that is in a format other than the default date format into a DATE value
TO_CHAR function to translate a DATE value that is in a format other than the default date format into a string (for example, to print the date from an application)
The default date format is specified either explicitly with the initialization parameter NLS_DATE_FORMAT or implicitly with the initialization parameter NLS_TERRITORY. For information on these parameters, see Oracle8i Reference.
You can change the default date format for your session with the ALTER SESSION statement.
The total length of a date format model cannot exceed 22 characters.
A date format model is composed of one or more date format elements as listed in Table 2-9.
TO_DATE function, as noted in Table 2-9.
Capitalization in a spelled-out word, abbreviation, or Roman numeral follows capitalization in the corresponding format element. For example, the date format model 'DAY' produces capitalized words like 'MONDAY'; 'Day' produces 'Monday'; and 'day' produces 'monday'.
You can also include these characters in a date format model:
These characters appear in the return value in the same location as they appear in the format model.
Oracle returns an error if an alphanumeric character is found in the date string where punctuation character is found in the format string. For example:
TO_CHAR (TO_DATE('0297','MM/YY'), 'MM/YY')
returns an error.
The functionality of some date format elements depends on the country and language in which you are using Oracle. For example, these date format elements return spelled values:
The language in which these values are returned is specified either explicitly with the initialization parameter NLS_DATE_LANGUAGE or implicitly with the initialization parameter NLS_LANGUAGE. The values returned by the YEAR and SYEAR date format elements are always in English.
The date format element D returns the number of the day of the week (1-7). The day of the week that is numbered 1 is specified implicitly by the initialization parameter NLS_TERRITORY.
|
See Also: Oracle8i Reference and Oracle8i National Language Support Guide for information on national language support initialization parameters |
Oracle calculates the values returned by the date format elements IYYY, IYY, IY, I, and IW according to the ISO standard. For information on the differences between these values and those returned by the date format elements YYYY, YYY, YY, Y, and WW, see the discussion of national language support in Oracle8i National Language Support Guide.
The RR date format element is similar to the YY date format element, but it provides additional flexibility for storing date values in other centuries. The RR date format element allows you to store 21st century dates in the 20th century by specifying only the last two digits of the year. It will also allow you to store 20th century dates in the 21st century in the same way if necessary.
If you use the TO_DATE function with the YY date format element, the date value returned always has the same first 2 digits as the current year. If you use the RR date format element instead, the century of the return value varies according to the specified two-digit year and the last two digits of the current year. Table 2-10 summarizes the behavior of the RR date format element.
The following examples demonstrate the behavior of the RR date format element.
Assume these queries are issued between 1950 and 1999:
SELECT TO_CHAR(TO_DATE('27-OCT-98', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 1998 SELECT TO_CHAR(TO_DATE('27-OCT-17', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 2017
Now assume these queries are issued between 2000 and 2049:
SELECT TO_CHAR(TO_DATE('27-OCT-98', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 1998 SELECT TO_CHAR(TO_DATE('27-OCT-17', 'DD-MON-RR') ,'YYYY') "Year" FROM DUAL; Year ---- 2017
Note that the queries return the same values regardless of whether they are issued before or after the year 2000. The RR date format element allows you to write SQL statements that will return the same values from years whose first two digits are different.
Table 2-11 lists suffixes that can be added to date format elements:
| Suffix | Meaning | Example Element | Example Value |
|---|---|---|---|
|
TH |
Ordinal Number |
DDTH |
4TH |
|
SP |
Spelled Number |
DDSP |
FOUR |
|
SPTH or THSP |
Spelled, ordinal number |
DDSPTH |
FOURTH |
|
Restrictions: |
|||
The FM and FX modifiers, used in format models in the TO_CHAR function, control blank padding and exact format checking.
A modifier can appear in a format model more than once. In such a case, each subsequent occurrence toggles the effects of the modifier. Its effects are enabled for the portion of the model following its first occurrence, and then disabled for the portion following its second, and then reenabled for the portion following its third, and so on.
"Fill mode". This modifier suppresses blank padding in the return value of the TO_CHAR function:
TO_CHAR function, this modifier suppresses blanks in subsequent character elements (such as MONTH) and suppresses leading zeroes for subsequent number elements (such as MI) in a date format model. Without FM, the result of a character element is always right padded with blanks to a fixed length, and leading zeroes are always returned for a number element. With FM, because there is no blank padding, the length of the return value may vary.
TO_CHAR function, this modifier suppresses blanks added to the left of the number, so that the result is left-justified in the output buffer. Without FM, the result is always right-justified in the buffer, resulting in blank-padding to the left of the number.
"Format exact". This modifier specifies exact matching for the character argument and date format model of a TO_DATE function:
When FX is enabled, you can disable this check for leading zeroes by using the FM modifier as well.
If any portion of the character argument violates any of these conditions, Oracle returns an error message.
The following statement uses a date format model to return a character expression:
SELECT TO_CHAR(SYSDATE, 'fmDDTH')||' of '||TO_CHAR (SYSDATE, 'fmMonth')||', '||TO_CHAR(SYSDATE, 'YYYY') "Ides" FROM DUAL; Ides ------------------ 3RD of April, 1998
Note that the statement above also uses the FM modifier. If FM is omitted, the month is blank-padded to nine characters:
SELECT TO_CHAR(SYSDATE, 'DDTH')||' of '|| TO_CHAR(SYSDATE, 'Month')||', '|| TO_CHAR(SYSDATE, 'YYYY') "Ides" FROM DUAL; Ides ----------------------- 03RD of April , 1998
The following statement places a single quotation mark in the return value by using a date format model that includes two consecutive single quotation marks:
SELECT TO_CHAR(SYSDATE, 'fmDay')||'''s Special' "Menu" FROM DUAL; Menu ----------------- Tuesday's Special
Two consecutive single quotation marks can be used for the same purpose within a character literal in a format model.
Table 2-12 shows whether the following statement meets the matching conditions for different values of char and 'fmt' using FX (the table named table has a column date_column of datatype DATE):
UPDATE table SET date_column = TO_DATE(char, 'fmt');
The following additional formatting rules apply when converting string values to date values (unless you have used the FX or FXFM modifiers in the format model to control exact format checking):
Table 2-13 Oracle Format Matching
| Original Format Element | Additional Format Elements to Try in Place of the Original |
|---|---|
'MM' |
'MON' and 'MONTH' |
|
|
|
|
|
|
|
|
|
|
|
|
If a column in a row has no value, then the column is said to be null, or to contain a null. Nulls can appear in columns of any datatype that are not restricted by NOT NULL or PRIMARY KEY integrity constraints. Use a null when the actual value is not known or when a value would not be meaningful.
Do not use null to represent a value of zero, because they are not equivalent. (Oracle currently treats a character value with a length of zero as null. However, this may not continue to be true in future releases, and Oracle recommends that you do not treat empty strings the same as nulls.) Any arithmetic expression containing a null always evaluates to null. For example, null added to 10 is null. In fact, all operators (except concatenation) return null when given a null operand.
All scalar functions (except REPLACE, NVL, and CONCAT) return null when given a null argument. You can use the NVL function to return a value when a null occurs. For example, the expression NVL(COMM,0) returns 0 if COMM is null or the value of COMM if it is not null.
Most aggregate functions ignore nulls. For example, consider a query that averages the five values 1000, null, null, null, and 2000. Such a query ignores the nulls and calculates the average to be (1000+2000)/2 = 1500.
To test for nulls, use only the comparison operators IS NULL and IS NOT NULL. If you use any other operator with nulls and the result depends on the value of the null, the result is UNKNOWN. Because null represents a lack of data, a null cannot be equal or unequal to any value or to another null. However, Oracle considers two nulls to be equal when evaluating a DECODE expression.
Oracle also considers two nulls to be equal if they appear in compound keys. That is, Oracle considers identical two compound keys containing nulls if all the non-null components of the keys are equal.
A condition that evaluates to UNKNOWN acts almost like FALSE. For example, a SELECT statement with a condition in the WHERE clause that evaluates to UNKNOWN returns no rows. However, a condition evaluating to UNKNOWN differs from FALSE in that further operations on an UNKNOWN condition evaluation will evaluate to UNKNOWN. Thus, NOT FALSE evaluates to TRUE, but NOT UNKNOWN evaluates to UNKNOWN.
Table 2-14 shows examples of various evaluations involving nulls in conditions. If the conditions evaluating to UNKNOWN were used in a WHERE clause of a SELECT statement, then no rows would be returned for that query.
For the truth tables showing the results of logical expressions containing nulls, see Table 3-6, as well as Table 3-7 and Table 3-8.
A pseudocolumn behaves like a table column, but is not actually stored in the table. You can select from pseudocolumns, but you cannot insert, update, or delete their values. This section describes these pseudocolumns:
A sequence is a schema object that can generate unique sequential values. These values are often used for primary and unique keys. You can refer to sequence values in SQL statements with these pseudocolumns:
|
|
The |
|
|
The |
You must qualify CURRVAL and NEXTVAL with the name of the sequence:
sequence.CURRVAL sequence.NEXTVAL
To refer to the current or next value of a sequence in the schema of another user, you must have been granted either SELECT object privilege on the sequence or SELECT ANY SEQUENCE system privilege, and you must qualify the sequence with the schema containing it:
schema.sequence.CURRVAL schema.sequence.NEXTVAL
To refer to the value of a sequence on a remote database, you must qualify the sequence with a complete or partial name of a database link:
schema.sequence.CURRVAL@dblink schema.sequence.NEXTVAL@dblink
|
See Also:
"Referring to Objects in Remote Databases" for more information on referring to database links |
You can use CURRVAL and NEXTVAL in:
SELECT list of a SELECT statement that is not contained in a subquery, materialized view, or view
SELECT list of a subquery in an INSERT statement
VALUES clause of an INSERT statement
SET clause of an UPDATE statement
Restrictions: You cannot use CURRVAL and NEXTVAL:
DELETE, SELECT, or UPDATE statement
SELECT statement with the DISTINCT operator
SELECT statement with a GROUP BY clause or ORDER BY clause
SELECT statement that is combined with another SELECT statement with the UNION, INTERSECT, or MINUS set operator
WHERE clause of a SELECT statement
DEFAULT value of a column in a CREATE TABLE or ALTER TABLE statement
CHECK constraint
Also, within a single SQL statement that uses CURVAL or NEXTVAL, all referenced LONG columns, updated tables, and locked tables must be located on the same database.
When you create a sequence, you can define its initial value and the increment between its values. The first reference to NEXTVAL returns the sequence's initial value. Subsequent references to NEXTVAL increment the sequence value by the defined increment and return the new value. Any reference to CURRVAL always returns the sequence's current value, which is the value returned by the last reference to NEXTVAL. Note that before you use CURRVAL for a sequence in your session, you must first initialize the sequence with NEXTVAL.
Within a single SQL statement, Oracle will increment the sequence only once per row. If a statement contains more than one reference to NEXTVAL for a sequence, Oracle increments the sequence once and returns the same value for all occurrences of NEXTVAL. If a statement contains references to both CURRVAL and NEXTVAL, Oracle increments the sequence and returns the same value for both CURRVAL and NEXTVAL regardless of their order within the statement.
A sequence can be accessed by many users concurrently with no waiting or locking.
This example selects the current value of the employee sequence:
SELECT empseq.currval FROM DUAL;
This example increments the employee sequence and uses its value for a new employee inserted into the employee table:
INSERT INTO emp VALUES (empseq.nextval, 'LEWIS', 'CLERK', 7902, SYSDATE, 1200, NULL, 20);
This example adds a new order with the next order number to the master order table. It then adds suborders with this number to the detail order table:
INSERT INTO master_order(orderno, customer, orderdate) VALUES (orderseq.nextval, 'Al''s Auto Shop', SYSDATE); INSERT INTO detail_order (orderno, part, quantity) VALUES (orderseq.currval, 'SPARKPLUG', 4); INSERT INTO detail_order (orderno, part, quantity) VALUES (orderseq.currval, 'FUEL PUMP', 1); INSERT INTO detail_order (orderno, part, quantity) VALUES (orderseq.currval, 'TAILPIPE', 2);
For each row returned by a hierarchical query, the LEVEL pseudocolumn returns 1 for a root node, 2 for a child of a root, and so on. A root node is the highest node within an inverted tree. A child node is any nonroot node. A parent node is any node that has children. A leaf node is any node without children. Figure 2-2 shows the nodes of an inverted tree with their LEVEL values.
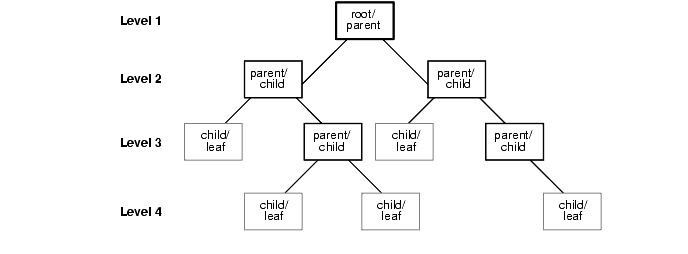
To define a hierarchical relationship in a query, you must use the START WITH and CONNECT BY clauses.
|
See also:
|
For each row in the database, the ROWID pseudocolumn returns a row's address. Oracle8i rowid values contain information necessary to locate a row:
Usually, a rowid value uniquely identifies a row in the database. However, rows in different tables that are stored together in the same cluster can have the same rowid.
Values of the ROWID pseudocolumn have the datatype ROWID or UROWID.
Rowid values have several important uses:
You should not use ROWID as a table's primary key. If you delete and reinsert a row with the Import and Export utilities, for example, its rowid may change. If you delete a row, Oracle may reassign its rowid to a new row inserted later.
Although you can use the ROWID pseudocolumn in the SELECT and WHERE clause of a query, these pseudocolumn values are not actually stored in the database. You cannot insert, update, or delete a value of the ROWID pseudocolumn.
This statement selects the address of all rows that contain data for employees in department 20:
SELECT ROWID, ename FROM emp WHERE deptno = 20; ROWID ENAME ------------------ ---------- AAAAqYAABAAAEPvAAA SMITH AAAAqYAABAAAEPvAAD JONES AAAAqYAABAAAEPvAAH SCOTT AAAAqYAABAAAEPvAAK ADAMS AAAAqYAABAAAEPvAAM FORD
For each row returned by a query, the ROWNUM pseudocolumn returns a number indicating the order in which Oracle selects the row from a table or set of joined rows. The first row selected has a ROWNUM of 1, the second has 2, and so on.
You can use ROWNUM to limit the number of rows returned by a query, as in this example:
SELECT * FROM emp WHERE ROWNUM < 10;
If an ORDER BY clause follows ROWNUM in the same query, the rows will be reordered by the ORDER BY clause. The results can vary depending on the way the rows are accessed. For example, if the ORDER BY clause causes Oracle to use an index to access the data, Oracle may retrieve the rows in a different order than without the index. Therefore, the following statement will not have the same effect as the preceding example:
SELECT * FROM emp WHERE ROWNUM < 11 ORDER BY empno;
If you embed the ORDER BY clause in a subquery and place the ROWNUM condition in the top-level query, you can force the ROWNUM condition to be applied after the ordering of the rows. For example, the following query returns the 10 smallest employee numbers. This is sometimes referred to as a "top-N query":
SELECT * FROM (SELECT empno FROM emp ORDER BY empno) WHERE ROWNUM < 11;
In the preceding example, the ROWNUM values are those of the top-level SELECT statement, so they are generated after the rows have already been ordered by empno in the subquery.
|
See Also:
Oracle8i Application Developer's Guide - Fundamentals for more information about top-N queries |
Conditions testing for ROWNUM values greater than a positive integer are always false. For example, this query returns no rows:
SELECT * FROM emp WHERE ROWNUM > 1;
The first row fetched is assigned a ROWNUM of 1 and makes the condition false. The second row to be fetched is now the first row and is also assigned a ROWNUM of 1 and makes the condition false. All rows subsequently fail to satisfy the condition, so no rows are returned.
You can also use ROWNUM to assign unique values to each row of a table, as in this example:
UPDATE tabx SET col1 = ROWNUM;
|
Note: Using |
You can associate comments with SQL statements and schema objects.
Comments within SQL statements do not affect the statement execution, but they may make your application easier for you to read and maintain. You may want to include a comment in a statement that describes the statement's purpose within your application.
A comment can appear between any keywords, parameters, or punctuation marks in a statement. You can include a comment in a statement using either of these means:
A SQL statement can contain multiple comments of both styles. The text of a comment can contain any printable characters in your database character set.
These statements contain many comments:
SELECT ename, sal + NVL(comm, 0), job, loc /* Select all employees whose compensation is greater than that of Jones.*/ FROM emp, dept /*The DEPT table is used to get the department name.*/ WHERE emp.deptno = dept.deptno AND sal + NVL(comm,0) > /* Subquery: */ (SELECT sal + NLV(comm,0) /* total compensation is sal + comm */ FROM emp WHERE ename = 'JONES'); SELECT ename, -- select the name sal + NVL(comm, 0), -- total compensation job, -- job loc -- and city containing the office FROM emp, -- of all employees dept WHERE emp.deptno = dept.deptno AND sal + NVL(comm, 0) > -- whose compensation -- is greater than (SELECT sal + NVL(comm,0) -- the compensation FROM emp WHERE ename = 'JONES'); -- of Jones.
You can associate a comment with a table, view, materialized view, or column using the COMMENT command. Comments associated with schema objects are stored in the data dictionary.
You can use comments in a SQL statement to pass instructions, or hints, to the Oracle optimizer. The optimizer uses these hints as suggestions for choosing an execution plan for the statement.
A statement block can have only one comment containing hints, and that comment must follow the SELECT, UPDATE, INSERT, or DELETE keyword. The syntax below shows hints contained in both styles of comments that Oracle supports within a statement block.
{DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */
or
{DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...
where:
DELETE, INSERT, SELECT, or UPDATE is a DELETE, INSERT, SELECT, or UPDATE keyword that begins a statement block. Comments containing hints can appear only after these keywords.
hint is one of the hints discussed in this section. The space between the plus sign and the hint is optional. If the comment contains multiple hints, separate the hints by at least one space.
text is other commenting text that can be interspersed with the hints.
The syntax and a brief description of each hint appear below. Hints are divided into functional categories.
|
See Also:
Oracle8i Performance Guide and Reference and Oracle8i Concepts for more information on hints |
The ALL_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best throughput (that is, minimum total resource consumption).
The ALL_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best throughput (that is, minimum total resource consumption).
The FIRST_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best response time (minimum resource usage to return first row).
This hint causes the optimizer to make the following choices:
ORDER BY clause, then the optimizer might choose it to avoid a sort operation.
![]()
The RULE hint explicitly chooses rule-based optimization for a statement block. It also makes the optimizer ignore other hints specified for the statement block.
The AND_EQUAL hint explicitly chooses an execution plan that uses an access path that merges the scans on several single-column indexes.
The CLUSTER hint explicitly chooses a cluster scan to access the specified table. It applies only to clustered objects.
The FULL hint explicitly chooses a full table scan for the specified table.
The HASH hint explicitly chooses a hash scan to access the specified table. It applies only to tables stored in a cluster.

The INDEX hint explicitly chooses an index scan for the specified table. You can use the INDEX hint for domain, B*-tree, and bitmap indexes. However, Oracle recommends using INDEX_COMBINE rather than INDEX for bitmap indexes, because it is a more versatile hint.

The INDEX_ASC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, then Oracle scans the index entries in ascending order of their indexed values.

The INDEX_COMBINE hint explicitly chooses a bitmap access path for the table. If no indexes are given as arguments for the INDEX_COMBINE hint, then the optimizer uses whatever Boolean combination of bitmap indexes has the best cost estimate for the table. If certain indexes are given as arguments, then the optimizer tries to use some Boolean combination of those particular bitmap indexes.

The INDEX_DESC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, then Oracle scans the index entries in descending order of their indexed values. In a partitioned index, the results are in descending order within each partition.

The INDEX_FFS hint causes a fast full index scan to be performed rather than a full table scan.

The NO_INDEX hint explicitly disallows a set of indexes for the specified table.
The ROWID hint explicitly chooses a table scan by rowid for the specified table.
The ORDERED hint causes Oracle to join tables in the order in which they appear in the FROM clause.
If you omit the ORDERED hint from a SQL statement performing a join, then the optimizer chooses the order in which to join the tables. You might want to use the ORDERED hint to specify a join order if you know something about the number of rows selected from each table that the optimizer does not. Such information lets you choose an inner and outer table better than the optimizer could.
The STAR hint forces a star query plan to be used, if possible. A star plan has the largest table in the query last in the join order and joins it with a nested loops join on a concatenated index. The STAR hint applies when there are at least three tables, the large table's concatenated index has at least three columns, and there are no conflicting access or join method hints. The optimizer also considers different permutations of the small tables.
The DRIVING_SITE hint forces query execution to be done at a different site than that selected by Oracle. This hint can be used with either rule-based or cost-based optimization.

For a specific query, place the MERGE_AJ or HASH_AJ hints into the NOT IN subquery. MERGE_AJ uses a sort-merge anti-join and HASH_AJ uses a hash anti-join.
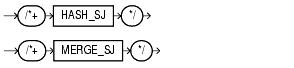
For a specific query, place the HASH_SJ or MERGE_SJ hint into the EXISTS subquery. HASH_SJ uses a hash semi-join and MERGE_SJ uses a sort merge semi-join.
The LEADING hint causes Oracle to use the specified table as the first table in the join order.
If you specify two or more LEADING hints on different tables, then all of them are ignored. If you specify the ORDERED hint, then it overrides all LEADING hints.
The USE_HASH hint causes Oracle to join each specified table with another row source with a hash join.
The USE_MERGE hint causes Oracle to join each specified table with another row source with a sort-merge join.
The USE_NL hint causes Oracle to join each specified table to another row source with a nested loops join using the specified table as the inner table.
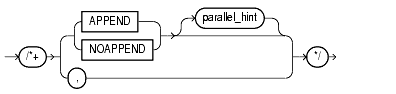
When you use the APPEND hint for INSERT, data is simply appended to a table. Existing free space in the blocks currently allocated to the table is not used.
If INSERT is parallelized using the PARALLEL hint or clause, then append mode is used by default. You can use NOAPPEND to override append mode. The APPEND hint applies to both serial and parallel insert.
The append operation is performed in LOGGING or NOLOGGING mode, depending on whether the [NO] option is set for the table in question. Use the ALTER TABLE... [NO]LOGGING statement to set the appropriate value.
The NOAPPEND hint overrides append mode.
The NOPARALLEL hint overrides a PARALLEL specification in the table clause. In general, hints take precedence over table clauses.
Restriction: You cannot parallelize a query involving a nested table.

The PARALLEL hint lets you specify the desired number of concurrent servers that can be used for a parallel operation. The hint applies to the INSERT, UPDATE, and DELETE portions of a statement as well as to the table scan portion.
If any parallel restrictions are violated, then the hint is ignored.

The PARALLEL_INDEX hint specifies the desired number of concurrent servers that can be used to parallelize index range scans for partitioned indexes.

The PQ_DISTRIBUTE hint improves parallel join operation performance. Do this by specifying how rows of joined tables should be distributed among producer and consumer query servers. Using this hint overrides decisions the optimizer would normally make.
Use the EXPLAIN PLAN statement to identify the distribution chosen by the optimizer. The optimizer ignores the distribution hint if both tables are serial.
|
See Also: Oracle8i Performance Guide and Reference for the permitted combinations of distributions for the outer and inner join tables |

The NOPARALLEL_INDEX hint overrides a PARALLEL attribute setting on an index to avoid a parallel index scan operation.
The MERGE hint lets you merge a view on a per-query basis.
If a view's query contains a GROUP BY clause or DISTINCT operator in the SELECT list, then the optimizer can merge the view's query into the accessing statement only if complex view merging is enabled. Complex merging can also be used to merge an IN subquery into the accessing statement if the subquery is uncorrelated.
Complex merging is not cost-based--that is, the accessing query block must include the MERGE hint. Without this hint, the optimizer uses another approach.
The NO_EXPAND hint prevents the cost-based optimizer from considering OR-expansion for queries having OR conditions or IN-lists in the WHERE clause. Usually, the optimizer considers using OR expansion and uses this method if it decides that the cost is lower than not using it.
The NO_MERGE hint causes Oracle not to merge mergeable views.
The NOREWRITE hint disables query rewrite for the query block, overriding the setting of the parameter QUERY_REWRITE_ENABLED. Use the NOREWRITE hint on any query block of a request.

The REWRITE hint forces the cost-based optimizer to rewrite a query in terms of materialized views, when possible, without cost consideration. Use the REWRITE hint with or without a view list. If you use REWRITE with a view list and the list contains an eligible materialized view, then Oracle uses that view regardless of its cost.
Oracle does not consider views outside of the list. If you do not specify a view list, then Oracle searches for an eligible materialized view and always uses it regardless of its cost.
The STAR_TRANSFORMATION hint makes the optimizer use the best plan in which the transformation has been used. Without the hint, the optimizer could make a cost-based decision to use the best plan generated without the transformation, instead of the best plan for the transformed query.
Even if the hint is given, there is no guarantee that the transformation will take place. The optimizer only generates the subqueries if it seems reasonable to do so. If no subqueries are generated, then there is no transformed query, and the best plan for the untransformed query is used, regardless of the hint.
The USE_CONCAT hint forces combined OR conditions in the WHERE clause of a query to be transformed into a compound query using the UNION ALL set operator. Generally, this transformation occurs only if the cost of the query using the concatenations is cheaper than the cost without them.
The USE_CONCAT hint turns off IN-list processing and OR-expands all disjunctions, including IN-lists.
The CACHE hint specifies that the blocks retrieved for the table are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables.
The NOCACHE hint specifies that the blocks retrieved for the table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. This is the normal behavior of blocks in the buffer cache.
If you enabled subquery unnesting with the UNNEST_SUBQUERY parameter, then the NO_UNNEST hint turns it off for specific subquery blocks.
The ORDERED_PREDICATES hint forces the optimizer to preserve the order of predicate evaluation, except for predicates used as index keys. Use this hint in the WHERE clause of SELECT statements.
If you do not use the ORDERED_PREDICATES hint, then Oracle evaluates all predicates in the order specified by the following rules. Predicates:
WHERE clause.
WHERE clause.
WHERE clause (for example, predicates transitively generated by the optimizer) are evaluated next.
WHERE clause.
The PUSH_PRED hint forces pushing of a join predicate into the view.
The NO_PUSH_PRED hint prevents pushing of a join predicate into the view.
The PUSH_SUBQ hint causes non-merged subqueries to be evaluated at the earliest possible place in the execution plan. Generally, subqueries that are not merged are executed as the last step in the execution plan. If the subquery is relatively inexpensive and reduces the number of rows significantly, then it improves performance to evaluate the subquery earlier.
This hint has no effect if the subquery is applied to a remote table or one that is joined using a merge join.
Setting the UNNEST_SUBQUERY session parameter to TRUE enables subquery unnesting. Subquery unnesting unnests and merges the body of the subquery into the body of the statement that contains it, allowing the optimizer to consider them together when evaluating access paths and joins.
UNNEST_SUBQUERY first verifies if the statement is valid. If the statement is not valid, then subquery unnesting cannot proceed. The statement must then must pass a heuristic test.
The UNNEST hint checks the subquery block for validity only. If it is valid, then subquery unnesting is enabled without Oracle checking the heuristics.
Oracle recognizes objects that are associated with a particular schema and objects that are not associated with a particular schema, as described in the sections that follow.
A schema is a collection of logical structures of data, or schema objects. A schema is owned by a database user and has the same name as that user. Each user owns a single schema. Schema objects can be created and manipulated with SQL and include the following types of objects:
Other types of objects are also stored in the database and can be created and manipulated with SQL but are not contained in a schema:
In this reference, each type of object is briefly defined in Chapter 7 through Chapter 11, in the section describing the statement that creates the database object. These statements begin with the keyword CREATE. For example, for the definition of a cluster, see CREATE CLUSTER.
You must provide names for most types of schema objects when you create them. These names must follow the rules listed in the following sections.
Some schema objects are made up of parts that you can or must name, such as:
Tables and indexes can be partitioned. When partitioned, these schema objects consist of a number of parts called partitions, all of which have the same logical attributes. For example, all partitions in a table share the same column and constraint definitions, and all partitions in an index share the same index columns.
When you partition a table or index using the range method, you specify a maximum value for the partitioning key column(s) for each partition. When you partition a table or index using the hash method, you instruct Oracle to distribute the rows of the table into partitions based on a system-defined hash function on the partitioning key column(s). When you partition a table or index using the composite-partitioning method, you specify ranges for the partitions, and Oracle distributes the rows in each partition into one or more hash subpartitions based on a hash function. Each subpartition of a table or index partitioned using the composite method has the same logical attributes.
Partition-extended and subpartition-extended table names let you perform some partition-level and subpartition-level operations, such as deleting all rows from a partition or subpartition, on only one partition or subpartition. Without extended table names, such operations would require that you specify a predicate (WHERE clause). For range-partitioned tables, trying to phrase a partition-level operation with a predicate can be cumbersome, especially when the range partitioning key uses more than one column. For hash partitions and subpartitions, using a predicate is more difficult still, because these partitions and subpartitions are based on a system-defined hash function.
Partition-extended table names let you use partitions as if they were tables. An advantage of this method, which is most useful for range-partitioned tables, is that you can build partition-level access control mechanisms by granting (or revoking) privileges on these views to (or from) other users or roles.To use a partition as a table, create a view by selecting data from a single partition, and then use the view as a table.
You can specify partition-extended or subpartition-extended table names for the following DML statements:
The basic syntax for using partition-extended and subpartition-extended table names is:

Currently, the use of partition-extended and subpartition-extended table names has the following restrictions:
In the following statement, sales is a partitioned table with partition jan97. You can create a view of the single partition jan97, and then use it as if it were a table. This example deletes rows from the partition.
CREATE VIEW sales_jan97 AS SELECT * FROM sales PARTITION (jan97); DELETE FROM sales_jan97 WHERE amount < 0;
This section provides:
The following rules apply when naming schema objects:
If your database character set contains multibyte characters, Oracle recommends that each name for a user or a role contain at least one single-byte character.
Depending on the Oracle product you plan to use to access a database object, names might be further restricted by other product-specific reserved words.
|
See Also:
|
DUAL as a name for an object or part. DUAL is the name of a dummy table.
DIMENSION, SEGMENT, ALLOCATE, DISABLE, and so forth). These words are not reserved. However, Oracle uses them internally. Therefore, if you use these words as names for objects and object parts, your SQL statements may be more difficult to read and may lead to unpredictable results.
In particular, do not use words beginning with "SYS_" as schema object names, and do not use the names of SQL built-in functions for the names of schema objects or user-defined functions.
The following figure shows the namespaces for schema objects. Each box is a namespace. Tables and views are in the same namespace. Therefore, a table and a view in the same schema cannot have the same name. However, tables and indexes are in different namespaces. Therefore, a table and an index in the same schema can have the same name.

Each schema in the database has its own namespaces for the objects it contains. This means, for example, that two tables in different schemas are in different namespaces and can have the same name.
The following figure shows the namespaces for nonschema objects. Because the objects in these namespaces are not contained in schemas, these namespaces span the entire database.

If you give a schema object a name enclosed in double quotation marks, you must use double quotation marks whenever you refer to the object.
Enclosing a name in double quotes allows it to:
By enclosing names in double quotation marks, you can give the following names to different objects in the same namespace:
emp "emp" "Emp" "EMP "
Note that Oracle interprets the following names the same, so they cannot be used for different objects in the same namespace:
emp EMP "EMP"
If you give a user or password a quoted name, the name cannot contain lowercase letters.
Database link names cannot be quoted.
The following examples are valid schema object names:
ename horse scott.hiredate "EVEN THIS & THAT!" a_very_long_and_valid_name
Although column aliases, table aliases, usernames, and passwords are not objects or parts of objects, they must also follow these naming rules with these exceptions:
Here are several helpful guidelines for naming objects and their parts:
When naming objects, balance the objective of keeping names short and easy to use with the objective of making names as descriptive as possible. When in doubt, choose the more descriptive name, because the objects in the database may be used by many people over a period of time. Your counterpart ten years from now may have difficulty understanding a database with a name like pmdd instead of payment_due_date.
Using consistent naming rules helps users understand the part that each table plays in your application. One such rule might be to begin the names of all tables belonging to the FINANCE application with fin_.
Use the same names to describe the same things across tables. For example, the department number columns of the sample employees and departments tables are both named deptno.
This section tells you how to refer to schema objects and their parts in the context of a SQL statement. This section shows you:
The following diagram shows the general syntax for referring to an object or a part:

where:
object is the name of the object.
schema is the schema containing the object. The schema qualifier allows you to refer to an object in a schema other than your own. You must be granted privileges to refer to objects in other schemas. If you omit schema, Oracle assumes that you are referring to an object in your own schema.
Only schema objects can be qualified with schema. Schema objects are shown with list item 9. Nonschema objects, also shown with list item 9, cannot be qualified with schema because they are not schema objects. (An exception is public synonyms, which can optionally be qualified with "PUBLIC". The quotation marks are required.)
part is a part of the object. This identifier allows you to refer to a part of a schema object, such as a column or a partition of a table. Not all types of objects have parts.
dblink applies only when you are using Oracle's distributed functionality. This is the name of the database containing the object. The dblink qualifier lets you refer to an object in a database other than your local database. If you omit dblink, Oracle assumes that you are referring to an object in your local database. Not all SQL statements allow you to access objects on remote databases.
You can include spaces around the periods separating the components of the reference to the object, but it is conventional to omit them.
When you refer to an object in a SQL statement, Oracle considers the context of the SQL statement and locates the object in the appropriate namespace. After locating the object, Oracle performs the statement's operation on the object. If the named object cannot be found in the appropriate namespace, Oracle returns an error.
The following example illustrates how Oracle resolves references to objects within SQL statements. Consider this statement that adds a row of data to a table identified by the name dept:
INSERT INTO dept VALUES (50, 'SUPPORT', 'PARIS');
Based on the context of the statement, Oracle determines that dept can be:
Oracle always attempts to resolve an object reference within the namespaces in your own schema before considering namespaces outside your schema. In this example, Oracle attempts to resolve the name dept as follows:
dept. If the object is not of the correct type for the statement, Oracle returns an error. In this example, dept must be a table, view, or a private synonym resolving to a table or view. If dept is a sequence, Oracle returns an error.
dept is a public synonym for a sequence, Oracle returns an error.
To refer to objects in schemas other than your own, prefix the object name with the schema name:
schema.object
For example, this statement drops the emp table in the schema scott:
DROP TABLE scott.emp
To refer to objects in databases other than your local database, follow the object name with the name of the database link to that database. A database link is a schema object that causes Oracle to connect to a remote database to access an object there. This section tells you:
You create a database link with the statement CREATE DATABASE LINK. The statement allows you to specify this information about the database link:
Oracle stores this information in the data dictionary.
When you create a database link, you must specify its name. Database link names are different from names of other types of objects. They can be as long as 128 bytes and can contain periods (.) and the "at" sign (@).
The name that you give to a database link must correspond to the name of the database to which the database link refers and the location of that database in the hierarchy of database names. The following syntax diagram shows the form of the name of a database link:
dblink::=

where:
database should specify name portion of the global name of the remote database to which the database link connects. This global name is stored in the data dictionary of the remote database; you can see this name in the GLOBAL_NAME view.
domain should specify the domain portion of the global name of the remote database to which the database link connects. If you omit domain from the name of a database link, Oracle qualifies the database link name with the domain of your local database as it currently exists in the data dictionary.
connect_descriptor allows you to further qualify a database link. Using connect descriptors, you can create multiple database links to the same database. For example, you can use connect descriptors to create multiple database links to different instances of the Oracle Parallel Server that access the same database.
The combination database.domain is sometimes called the "service name".
Oracle uses the username and password to connect to the remote database. The username and password for a database link are optional.
The database connect string is the specification used by Net8 to access the remote database. For information on writing database connect strings, see the Net8 documentation for your specific network protocol. The database string for a database link is optional.
Database links are available only if you are using Oracle's distributed functionality. When you issue a SQL statement that contains a database link, you can specify the database link name in one of these forms:
complete is the complete database link name as stored in the data dictionary, including the database, domain, and optional connect_descriptor components.
partial is the database and optional connect_descriptor components, but not the domain component.
Oracle performs these tasks before connecting to the remote database:
GLOBAL_NAME data dictionary view.)
GLOBAL_NAMES parameter is true, Oracle verifies that the database.domain portion of the database link name matches the complete global name of the remote database. If this condition is true, Oracle proceeds with the connection, using the username and password chosen in Step 2. If not, Oracle returns an error.
You can disable the requirement that the database.domain portion of the database link name must match the complete global name of the remote database by setting to false the initialization parameter GLOBAL_NAMES or the GLOBAL_NAMES parameter of the ALTER SYSTEM or ALTER SESSION statement.
To reference object type attributes or methods in a SQL statement, you must fully qualify the reference with a table alias. Consider the following example:
CREATE TYPE person AS OBJECT (ssno VARCHAR(20), name VARCHAR (10)); CREATE TABLE emptab (pinfo person);
In a SQL statement, reference to the ssno attribute must be fully qualified using a table alias, as illustrated below:
SELECT e.pinfo.ssno FROM emptab e; UPDATE emptab e SET e.pinfo.ssno = '510129980' WHERE e.pinfo.name = 'Mike';
To reference an object type's member method that does not accept arguments, you must provide "empty" parentheses. For example, assume that age is a method in the person type that does not take arguments. In order to call this method in a SQL statement, you must provide empty parentheses as shows in this example:
SELECT e.pinfo.age() FROM emptab e WHERE e.pinfo.name = 'Mike';
|
|
 Copyright © 1996-2000, Oracle Corporation. All Rights Reserved. |
|